




NVIDIAは9日から開催していたGTC(GPU Technology Conference)で、次世代のGPUアーキテクチャである「Volta」と具体的な製品である「Tesla V100」を発表した。Tesla V100に含まれるGPUは、GV100と呼ばれるものだ。本記事ではVoltaアーキテクチャのGV100に関して、セッションの内容などを元に解説を行なう。
最大の特徴は、4×4の行列演算を可能にする「Tensor Core」が組み込まれたことだろう。「Tensor」は、日本では「テンソル」と訳されるが、ここでは、数学的な意味のテンソルとの混同を避けるため「Tensor」のままとする。
まずは、論理的な性能比較から。前世代となるPascalアーキテクチャを使う前世代のGPUであるP100との性能比較は下の写真を見てほしい。
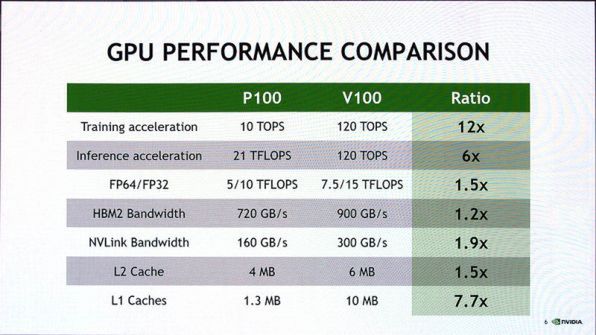
前世代となるPascal(Telsa P100)とVolta(Tesla V100)の比較
このうち、最初の2つの項目「Training acceleration」(学習アクセラレーション)と「Inference acceleration」(推論アクセラレーション)がTensor Coreによる効果で、それぞれ12倍、6倍の性能となる。
P100の推論速度が学習速度より大きいのは、16bitの半精度浮動小数点(FP16)を利用するからだ。これに対してTensor Coreも推論時にFP16で演算をすることができるが、Tensor Coreの機構上、どちらでも速度が変わらないため、比率(Ratio)が半分になっているように見える。
また、浮動小数点演算性能が1.5倍に上がったほか、HBM(High Bandwidth Memory)の接続速度、NVLinkの接続速度(V100はNVLink2と呼ばれる次世代のものに変更)、L1/L2キャッシュ容量の増加により、性能が向上している。
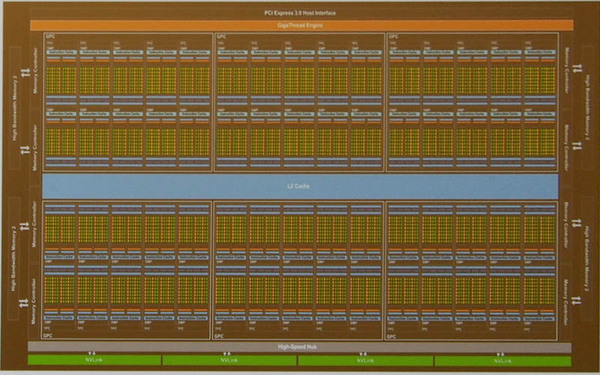
Telsa V100は、下の写真のような構造で、演算を実行するSM(Streaming Multiprocessor)が80個あり、その中に5120個のCUDAコア、640個のTensor Coreが含まれている。210億のトランジスタを815mm2のダイに集積してある。このサイズは、現在V100チップの製造を請け負うTSMCで作ることができる最大のダイサイズだ。

Tesla V100のGPU部分(GV100)には84個のSMがあり、うち80個が有効(残り4個は歩留まりを上げる冗長性に使われる)
写真の中で、緑色の4つの小さなブロックがSMを表し、全体で84個のSMがあるように見えるが、これは製造上の問題で、動かないSMがあった場合の対策。SMの不良が4つまでなら、正常な製品として出荷できるように冗長性を持たせているのだ。
上部の赤い部分がスレッドの実行制御を行なう「GigaThread Engine」であり、左右にメモリコントローラーが4つずつ、合計8個あり、HMB2と接続している。中央の青い部分がL2キャッシュで、下の緑色の部分がNVLink(第二世代)でこれは6チャンネルある。
前世代となるPascalアーキテクチャのGP100と比較してみよう。基本的な構造は似ているが、SMの数が違う。GP100のSMは56個で、実際には60個のSMがあり、うち4個を冗長性のために利用する。ラスタライザーを持つGPC(Graphics Processing Cluster)は6つでGV100と同じだ。
Pascal世代のGP100は、全体的にはGV100と同じ構造だが、SMの数が違っている
次にGV100のSMだが、これは下写真のような構造となる。
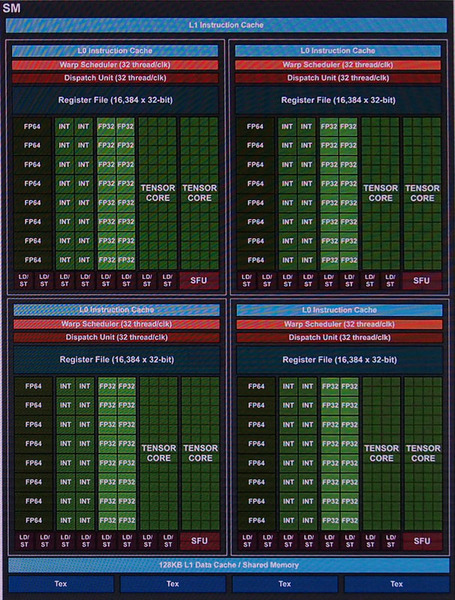
VoltaのSM(Straming Multiprocessor)は4つのブロックがあり、4つのWARPを並列実行できる。内部に浮動小数点演算ユニットや行列計算を行なうTensor Coreがある
これに対して、GP100のSMは次の写真のようになっている。

PascalのSMには、Tensor Coreはなく、さらにSM内は、2つのブロックになっている。ただしPascalでは1つのブロックが2つのWARPを並列実行するため、SM当たりのWARP実行数は、Voltaと同じ
最大の特徴は、4×4の行列演算を実行できる2つのTensor Core。図の表現からLD/ST(Load/Store Unit。メモリアクセスを行う)やSFU(Special Function Unit。超越関数などを計算するユニット)が小さく書かれているが、実際の数は同じだ。
GP100では、SM内は2つのブロックに分かれ、1つのブロックで2つのWARP(スレッドの集まり。GPUのスレッド実行単位)並列実行していたが、GV100のSMは、内部が4つのブロックとなり、それぞれでWARPを実行する。このため、レジスタファイルは、ブロックあたり16384とGP100 SMの半分だが、WARPあたりの割り当て量は同じになる。
GV100のTensor Coreのところをよく見ると64個の小さな矩形が書かれている。これは、行列演算を行なう場合の演算ユニットを表す。GV100のTensor Coreは、4×4の行列A、B、Cに対して、
C=A・B+C
という演算を行なう。この演算は、2つの4×4の行列AとBで内積演算(結果は4×4の行列となる)を行ない、これを行列C(やはり4×4)に加算していくというもの。AとBを変えて演算を繰り返していくとCにその結果が加算されていく。
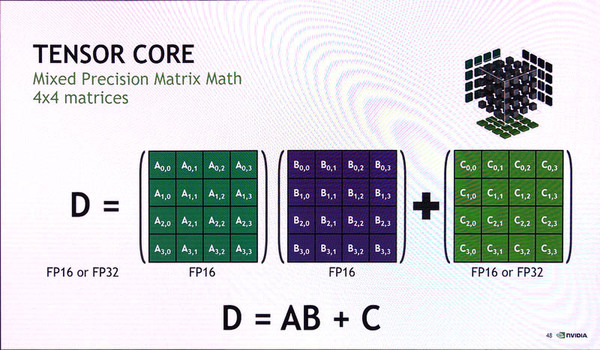
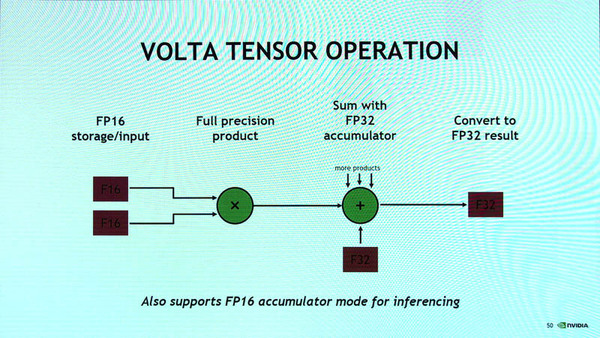
Tensor Coreは、4×4の行列の演算を1命令で行える。具体的には4×4の行列(64個のFP16数値)同士の内積を取り、結果をもう1つの4×4行列に加算していく
このとき4×4行列の内積(A・B)演算では、64個の乗算が必要になるが、そのための乗算ユニットを表しているのがこの小さな矩形の意味である。
なお、このとき、内積を行なう2つの行列の各要素は半精度浮動小数点(FP16)であり、内積を行うと有効桁数が増えFP32相当となり、これをFP32で表現されているCに加算していく。SM内のブロックには、このTensor Coreが2個、SMあたり8個が搭載されている。
Tensor Coreは、2クロックで4×4の内積と加算を完了できる。4×4の行列演算しかできないのではもっと要素の多い行列の計算には対応できないのでは? と思われるかもしれないが、行列の内積計算は、行列を複数のブロック行列に分解して計算させることができる。このため、4×4行列の計算が高速にできるなら、これを組みあわせてより要素数の多い行列の計算が可能だ。これを繰り返すことで、さらに大きな行列であっても内積計算ができる。
いわゆるディープラーニングと呼ばれるAI技術では、多数のニューロンを接続したニューラルネットワークを使う。学習時には、個々のニューロンが持つパラメーター(重みとも呼ばれる)を計算する必要がある。このとき、ニューラルネットワーク内で、レイヤーとレイヤー内のニューロンの位置を適切な方法で添え字を付けて表現すると、学習処理や推論処理をテンソル計算としてすることが可能になる。これを使った機械学習のフレームワークがGoogleのTensor Flowで、その登場以来、ディープラーニングの学習、推論処理を「テンソル演算」と呼ぶことが多くなった。
テンソルとは、数値(スカラー、大きさのみ、0階のテンソル)、ベクトル(大きさと方向、1階のテンソル)の上位となる数学的な概念(次元が違うのではなく、階数が違う)だ。
テンソル演算は、行列演算の組合せでできるため、行列計算を高速化することで、学習や推論処理を高速にすることが可能になる。Tensor Coreは、それを狙ったもの。もはやグラフィックスに必要な機能ではなく、科学技術計算、特にディープラーニング用の機能だといえる。
なお、GP100との比較でディープラーニングの学習速度を「120TOPS」としているのは、1つのマトリクス演算を従来のPASCALでの演算(64個の乗算と加算)に分解したときの速度で、
80[SMの個数]×8[SMあたりのTensor Core数]×128[行列演算の演算数]×1.453GHz[動作クロック]
≒120テラオペレーション
という計算だ。なお、NVIDIAが提供している計算ライブラリcuBLASを使った行列計算では、V100に最適化されたライブラリとP100のライブラリでは、2048×2048のFP16の行列の乗算を行わせたときに9.3倍の高速になるという。

NVIDIAが提供しているライブラリ(cuBLAS)により行列演算の比較。Pascalに対して9.3倍の速度がある
もう1つの大きな変更点は、スレッドの制御だ。Pascalまでのスレッドは、32スレッドをまとめたWARPで1つのグループを作り、同一のコードを並列実行する(対象データはスレッドごとに違う)。このため、この32スレッドは、プログラムカウンタを共有していた。つまり、WARP内の32スレッドは、まったく同じように動作していたわけだ。
これに対してVoltaでは、WARPは同じく32スレッドだが、それぞれのスレッド用のプログラムカウンタを持つようになり、スレッドごとに独立してコードを実行できるようになった。
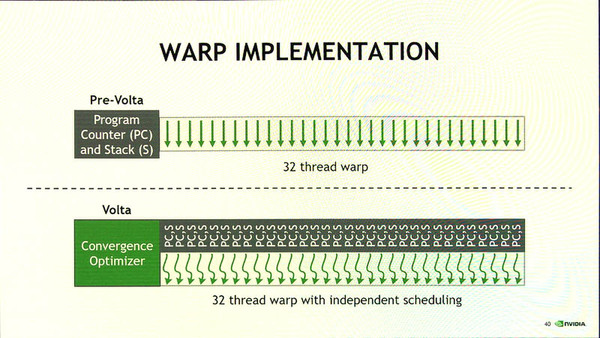
Pascalまでは、32スレッドまとめたWARPがプログラムカウンタを共有しているため、32スレッドが完全に同期して動作していた。これに対してVoltaでは、スレッドごとにプログラムカウンタを持ち、それぞれが個別に動作できる
ただし、WARPで行う処理によっては、実行中のある時点で、すべてのスレッドが特定の処理を終了していることが必要になる。たとえば、スレッドの演算結果を他のスレッドが利用するような依存関係がある場合だ。このような場合には、スレッド間で実行位置を合わせる「同期」を行うことができる。こうした改良により、従来は利用できなかったアルゴリズムを採用することが可能になったという。
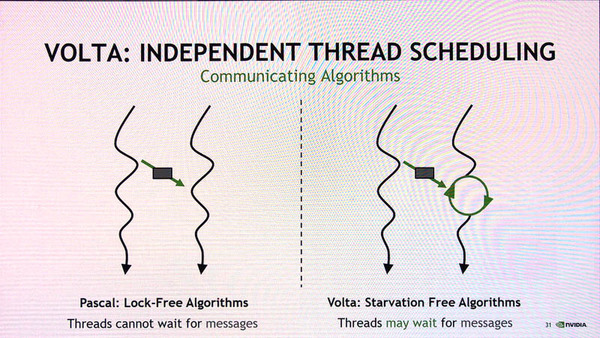
WARP内のスレッドが個別に動作するため、他のスレッドの結果を待って動作するようなプログラムを開発することも可能になった
また、SMに対して命令を発効するMulti Process ServiceもSM割り当てのアルゴリズムが変更になり、プロセスごとにまとめて割り当てができるようになり、SMの利用効率が向上している。このためにプロセス起動が早くなり、より多くのプロセスを同時に処理できる。
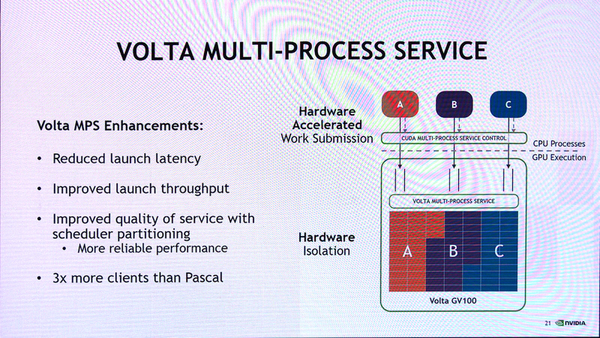
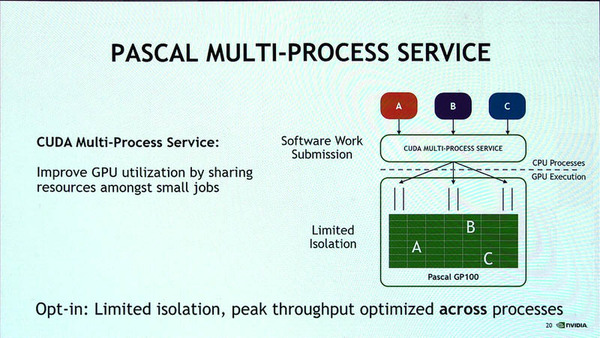
Voltaでは、GPU側のMulti-Process Serviceでプロセスの実行を制御するようになり、効率的なプロセス資源割り当てが可能になった。従来のPascalでは、CPU側でプロセスを起動させていたため、資源割り当ての状態が不明で効率的な実行ができなかった
また、Voltaでは、L1キャッシュについても変更があった。Pascalアーキテクチャでは、L1キャッシュはSMあたり24KBでリードオンリー(つまり書き込みはL2キャッシュへ直接行なわれる)で、それを補うために64KBの読み書き可能な共有メモリが装備されていた。
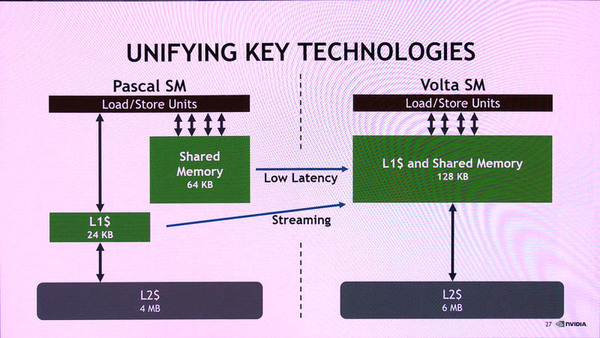
Pascalは、24KBのL1キャッシュと64KBの共有メモリを持っていたが、Voltaでは共有メモリを廃し、128KBの読み書き可能なL1キャッシュとした
ソフトウェアの開発時に必要なデータをあらかじめ共有メモリに入れておいたり、テンポラリな値をここに書き込んでおくことで、高速にアクセスできたが、開発者が使い方を考える必要があった。
これに対して、Voltaでは、L1キャッシュを128KBと増量し書き込みも可能にした。GV100全体では10MBを搭載している。ただし、共有メモリは廃止している。これにより、開発者は、共有メモリの使い方を考えることなく、128KB以内であれば、データのアクセスはL1キャッシュを介してできようになり、Pascalの共有メモリよりも高速にデータにアクセスが可能になり、かつ、より大きなデータに高速にアクセスできる。
なお、L2キャッシュも4MBから6MB(SMあたり)に増量されており、平均メモリアクセス時間が向上している。ただし、GV100ではL1キャッシュが大量に増やされ、L2キャッシュよりも大きくなっている。
さらに、V100上に集積されたHMBにアクセスするメモリコントローラーも強化されており、900GB/秒(Tesla P100では720GB/秒)になった。
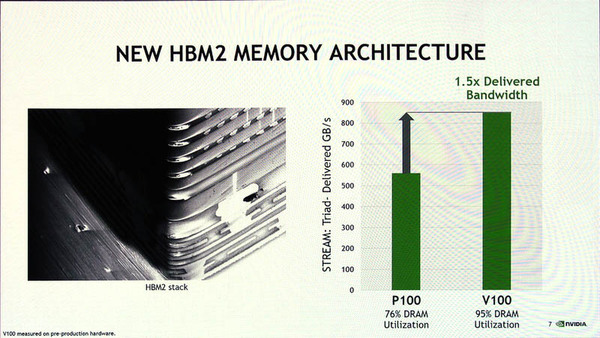
Tesla V100では、HBM2(High Bandwidth Memory)の接続バンド幅が拡大している。HBM2は、Tesla V100のパッケージ上に集積されている
また、CPU側とユニファイドメモリを構成するためのNVLinkも強化され、転送速度が300GB/秒と1.9倍(GP100では160GB/秒だった)になっている。
CPUとGPU側で同じメモリを共有するユニファイドメモリは、実際には、NVLink(x86/x64アーキテクチャではさらにPCI Expressブリッジを使っての接続。IBMのPower8以降はNVLinkを装備)を介して、メモリ領域をお互いにコピーすることで実現している。
つまり、1つのメモリデバイスを共有するのではなく、それぞれに接続されたメモリ間でメモリ内容のコピーすることで、見かけ上、同じメモリを読み書きしているように見せている。Pascal世代では、このために、片方がメモリにアクセスしている間には、メモリコピーが行えず,アクセスが双方で続くとページデータのコピーが多発する。
Voltaに装備されたNVLink2では、まず、相手側にあるメモリへのリモートアクセスをサポートした。これにより、低頻度のアクセスでは、ページのコピーが発生しない。また、ページに対するアクセスカウンタが装備され、どちらかが高い頻度でアクセスを行なうと、ページを移動させるようになった。


Voltaでは、Unified Memoryシステムも改良され、低頻度の場合には、メモリページをコピーせず、GPU側からCPU側のメモリへリモートアクセスできるようになった。また、アクセスカウンタがあり、アクセス頻度が上がるとページがGPU側にコピーされる
この改良によりメモリの一貫性維持やアトミックオペレーション(動作が分割されずに実行される動作)時の動作効率が上がっている。
たとえば、同じメモリページに同時にアトミック処理を行なう場合、Pascal世代では、片方のアトミックオペレーションが終了したのちにメモリをコピーしてもう1つのアトミックオペレーションを実行していたが、Voltaでは、NVLinkを介してページコピーを起こさずに相手側メモリでアトミックオペレーションを実行する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります


















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")


































