
AMDは、技術発表会「HotChips」で、Zenの詳細を発表した。結果、いくつか連載370回で説明した内容で間違っているところや、新たに判明したことなどがあるのでまとめて補足しておきたい。
まずHotChipsで紹介されたZenの特徴が下の画像である。

主な特徴。とにかくQueueが全般的に大きめになっているのがわかる。ちなみにL1はWritebackだが、L2はWrite Throughの模様だ
スケジューラーやキューのサイズは、Skylakeよりもやや少ないが、Haswell/Broadwell世代とはほぼ互角といったところまで増えており、一方でキャッシュは明らかにHaswell/BroadwellはおろかSkylake世代を上回る帯域となっている。
結果、小さいプログラムやデータを扱う範囲ではSkylakeに分があるかもしれないが、大きなデータやプログラムに関してはZenに分がありそうだ。
さて、まずフェッチのところであるが、TLBがかなり強化され、さらにL0 TLBが搭載されているのがわかる。
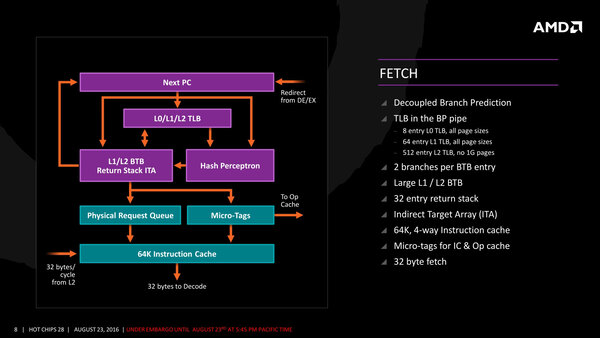
Micro-Op Cacheの制御もこの段階で行なわれる。要するにHash Perceptronのユニットで、Op Cache経由で読み込むか、通常のデコードを行なうかをMicro-Tagの形で付加していると思われる
また分岐予測にパーセプトロン(一種のニューラルネットワーク)を応用した仕組みを取り入れており、これで分岐ミスをさらに減らそうという試みのようだ。この段階では、1サイクルあたり32バイトで命令を読み込み、これをデコード段に渡す形だ。
そのデコード段であるが、Pick(32バイトのデータから命令をピックアップ)→デコード(x86命令を解釈)し、これをMicro-opキューに引き渡す格好だが、このあとマイクロコードRomを経るあたりは、やはり予想通りデコード段では最終的なMicroOpではなく、中間的な命令になると思われる。
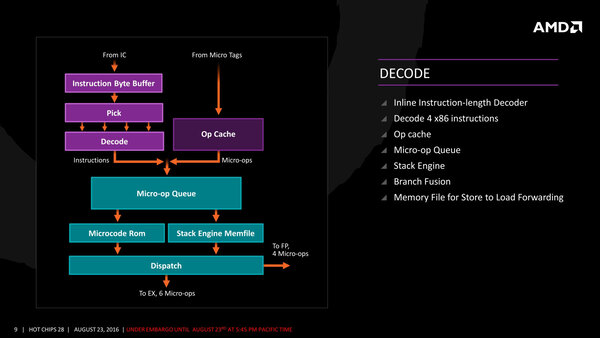
Branch Fusionは、分岐命令を1 Micro-Opにまとめる仕組みである。通常分岐はまず条件判断命令、ついで判断結果に応じて分岐という2つのx86命令で表現されるが、これは当然ペアとなるので1つのMicro-opとすることで、Micro-op数の削減や消費電力削減に効果的という話だった
またStack Engine Memfileと呼ばれるユニットがここに追加されているのがわかる。これは連載370回で説明したStack Engineに関係する。
もともとK10の世代で搭載されたSideband Stack OptimizerはStackの処理のみを行なうユニットである。Stack処理とは、PUSH(あるレジスタのデータをStack領域に保存)とPOP(Stack領域からデータをレジスターに復活)の2つであるが、処理的には単純なデータのMoveと、Stack Pointerという値の加減算のみで、わざわざALUを動かすのはもったいないので、Stack Pointerの加減算専用のユニット(Sideband Stack Optimizer)を用意して、こちらで処理を行なうことで省電力化を図るというものだった。
Stack Engineはこれをもう一歩すすめ、Move処理も省電力化した。ZenにはMove Eliminationという機能がある。これはRegister Fileの名前を付け替えることでデータの移動を省く仕組みだが、Stack処理の場合、従来ではメモリーに置かれたStack領域を利用するので、どうしてもメモリーアクセスが発生してしまう。
そこで、Stack専用のMemfileを32エントリー分用意し(これが上の画像に出てくるStack Engine Memfileだ)、ここにStackデータを保存することで、メモリアクセスそのものも省こうというものだ。
大規模にStackを積むと、当然32エントリーでは足りなくなるため、メモリーアクセスが発生するのは避けられないが、ちょっとしたサブルーチンコールなどではレジスターを数個Stackに保存する程度なので、ここで内部のMemfileが利用できれば省電力性と高速性の両方に役立つことになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第971回
PC
GTC 2026激震! 突如現れたGroq 3と消えたRubin CPX。NVIDIAの推論戦略を激変させたTSMCの逼迫とメモリー高騰 -
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 - この連載の一覧へ








