




今回のスーパーコンピューターの系譜は、BlueGen/Pの後継であり、現在も広く使われているBlue Gene/Qを解説しよう。


Blue Gene/Q
このBlue Gene/QをベースとしたSequoia(セコイア)は、ASCのシステムとしてローレンス・リバモア国立研究所に導入され、2012年6月のTOP500では京コンピューターを退けて世界最速の座に着いたマシンである。
現時点での最新のリスト(2014年6月)でもまだ3位に位置しているあたり、まさに現役のアーキテクチャーである。
同時4スレッド実行可能なプロセッサーを採用した
BlueGene/Q
さて、前回の最後でも述べたが、Blue Gene/PのアーキテクチャーはBlue Gene/Lと比べてずば抜けて優れていたわけではない。
もちろんプロセスの微細化やI/Fの高速化などで性能と消費電力の両面で改善はあったものの、それは数%~数十%で、積み重ねても数倍という域には達していない。これもあって、Blue Gene/Qでは、基本的なアーキテクチャーそのものは同じながら、実装はずいぶん変化した。
基本的なアーキテクチャーとは「PowerPCベースの超並列」で、これに変化はない。使われるコアはPowerA2になった。IBMは2000年のISSCCで、ネットワークプロセッサーとしてPowerEN(Power Edge of Network)という製品を発表したが、このPowerENに使われてたのがPowerA2である。

ネットワークプロセッサー「PowerEN」の構成図。構成そのものはそう珍しいものではない。ISSCC 2010におけるIBMの“A Wire-Speed Power Processor: 2.3GHz 45nm SOI with 16 Cores and 64 Threads”という論文より抜粋
Blue Gene/Qでは、このPowerA2コア、というよりPowerENのプロセッサー周辺部をまるごと流用したことになる。そのPowerA2コアの構造は下の画像のとおり。

PowerA2コアの構造。ネットワークプロセッサーの場合、1スレッドあたりの性能というよりはどれだけ多くのスレッドを実行できるかの方が重要だ。ここからのスライドは、IBMが2011年11月に公開した“Blue Gene/Q Overview and Update”という資料からの抜粋となる
In-Orderのパイプライン構成で、実行ユニットは2命令同時実行という慎ましやかなものだが、SMT(Simultaneous Multithreading:同時マルチスレッディング)で同時4スレッド実行可能というあたりがあまり一般的ではない。
もっとも当初のネットワークプロセッサーの場合、処理の大半はデータをメモリー経由で読んで、少し手を加えて送り出すという過程になるため、性能はもっぱらメモリーアクセス性能で決まる。
つまりCPUコアの大半はメモリーアクセス待ちに陥るわけで、SMTを使ってメモリーアクセス要求を効率的に出し続けることで実効性能を引き上げようという発想そのものは正しい。
実はこの考え方はHPCにもそのまま当てはまる。要するにメモリーアクセスが最終的にはボトルネックになるので、なるべくメモリーアクセスを効率よく行なわせる必要があり、このためには複数スレッドを同時に走らせることは確かに効果的である。
ただし、PowerA2そのものは浮動小数点演算をサポートしていない。そこで、これもBlue Gene/LやBlue Gene/Pと同じく外付けで「QXP」という名称のFPUを追加したのだが、この際に規模を倍増している。
これにより1サイクルあたり倍精度浮動小数点演算を8つ(MAC演算が可能なので、FPU1個あたり2演算相当)実行できるという、強烈な構成である。

Blue Gene/Qチップの全体像。A2コアとの間は256bit幅で接続され、倍精度浮動小数点(64bit)を1サイクルあたり4つづつ入出力できる。この規模も強烈だ
これを集積したBlue Gene/Qチップの全体が下の画像だ。360mm2のダイに、合計18ものプロセシングユニット(A2+QXP)を集約しており、このうち16個が計算、1個が通信管理などOSの作業に割り当てられている。

Blue Gene/Qのチップ。PowerENでは2次キャッシュは4コアあたり1つで共有されていたが、Blue Gene/Qでは冗長コアの扱いなどもあるためか、プロセシングユニットと2次キャッシュは独立しており、全体で2MB×16=32MB構成となっている
これでは合計17個になって数が合わないと思われるかもしれないが、1個は冗長コアとしてリザーブ扱いにされている。この冗長メカニズムを示したのが下の画像である。
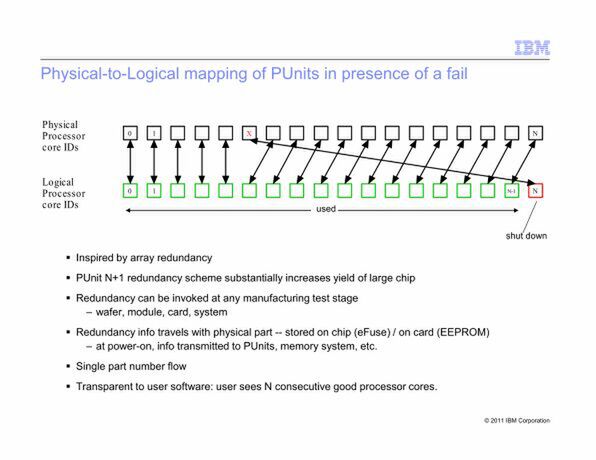
Blue Gene/Qチップの冗長メカニズム。コアの無効化は、製造後のテスト段階でチェックされるので、例えば稼働中に不良を起こしたら動的に排除するという話ではない
ソフトウェアから見ると、Blue Gene/Qは17コアのプロセッサーとして見えており、不良のコアがあることは見えない。実際にはある特定のコアに問題がある場合、そのコアは無効化されるようになっているわけだ。
このあたりは、PlayStation 3で利用されていたCellプロセッサーが、実際にはSPE(Synergistic Processor Element)が8つあるにも関わらず7つのみ有効にしていたのと同じ考え方である。
(→次ページヘ続く 「チップの性能はBlue Gene/Pの15倍」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












