




Knights Coveで時間を稼ぎ
その次のKnights Runが本命
ではどうするのか? というのが次の話。今のところインテルはKnights Hillに代えてKnights Coveという次の製品を2019~2020年の段階でまず投入、次いでKnights Runという製品を2022年までに投入し、これがAurora用になると言われている。

Xeon Phi
まずマイクロアーキテクチャーだが、Knights Hillは基本的にKnights Landingのプロセス微細化版と目されていた。Knights Landingは14nmプロセスを利用し、Silvermont(つまりAtom系列)の整数パイプラインにAVX512エンジン×2を組み合わせたコアを最大72個搭載する。
AVX512エンジンはDP(64bit)の値を8つ同時に扱え、しかもFMAD(Fused Multiply and Add:積和演算)処理が可能なので、1サイクルあたり16FLOPS相当になる。ハイエンドの「Xeon Phi 7290F」の場合、72コアで1.5GHz駆動なので、16(FLOPS/サイクル)×72(コア)×1.5GHz=3456GFLOPSという計算である。
これがKnights Coveでは、コアがIceLake-SP(Skylake-SPの10nmプロセス版)に32GBのHBM2を搭載したものになると、もっぱらの噂である。コア数は38ないし44だそうで、こちらもSkylake-SPに1つのコアにAVX512エンジンを2つ搭載したものになる。仮に動作周波数が3GHzと仮定すると以下の性能になる。
- 38コア:16(FLOPS/サイクル)×38(コア)×3GHz=3648GFLOPS
- 44コア:16(FLOPS/サイクル)×44(コア)×3GHz=4224GFLOPS
というあたりで、Knights Landingから微増というあたりでしかないが、おそらくこれはポイントリリーフで、次のKnights Runではもっと多数(~88コア程度?)のコアを集積したものになるとみられる。そうでないと1EFLOPSが実現できないからだ。
仮にAuroraの規模を維持する(5万ノード)と仮定すると、1ノードあたり20TFLOPSほどが実現できないとまずい。1ノードにXeon Phiを2つ、Xeon SPを1つという構成だとすると、Xeon Phiが88コア/3GHz動作、Xeonが38コア/3GHz動作ならだいたいノードあたり20.5TFLOPSほどが出せる計算になる。
時期的にはKnights Runや、これと対になるXeon SP(こちらはコード名がIce Ageだそうだ)は7nmプロセスを使ったものになるだろうが、あとはこの7nmがどこまで消費電力を抑えられるかということに尽きそうだ。
ところで、なぜKnights CoreでいきなりXeonコアを使うかだが、Knights Landingのチーフアーキテクトを勤めたAvinash Sodani氏が2016年9月にCavium Inc.に転職しており、Xeon Phiのチーム自身も現在弱体化していると噂されている。
すでに命令セットはAVX512でXeonとXeon Phiは共通化されており、Xeon-SPコアをHPC向けにローカルキャッシュを強化(このためにHBM2を利用)する程度でお茶を濁さざるを得ないということだろう。このあたりもなかなかインテルの苦しい事情が透けて見える。
ちなみに今年のSC17では、そのCaviumは下記のプレゼンテーションを出しており、インテルとやる気満々である。もっともそのCaviumもMarvell Semiconductorに買収されるというニュースが今月に入って流れているので、この先どうなるのか不明ではある。
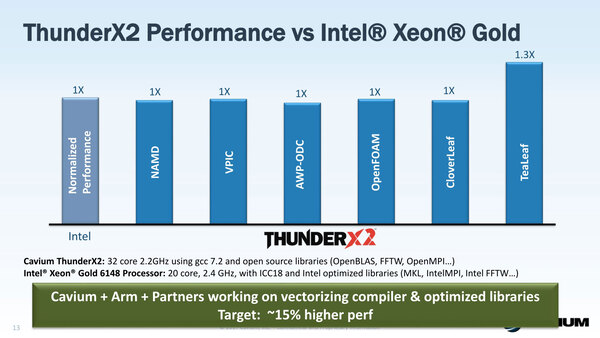
主要なアプリケーション性能をXeon Gold 6148と32コアのThunder X2で比較したもの。もっともARMv8といっても拡張命令そのものはNEONレベルなので、このThunder X2ベースのスパコンを提供するCrayにしても、計算処理そのものはNVIDIAのGPUを使っている。当面はこういう使い方が主流だろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












