




CRAYに対抗するための超並列マシン
「FPS T」シリーズ
FPS-164をもう一歩進めて超並列構成のマシンを作れないか、ということで同社が1986年に発表したのがFPS Tシリーズである。
FPS Tでは、同社はプロセッサーを外から購入した。下の画像が各々のノードの構成だが、まずControl ProcessorとあるのはInmosのT400シリーズ(おそらくT414の15MHz)である。
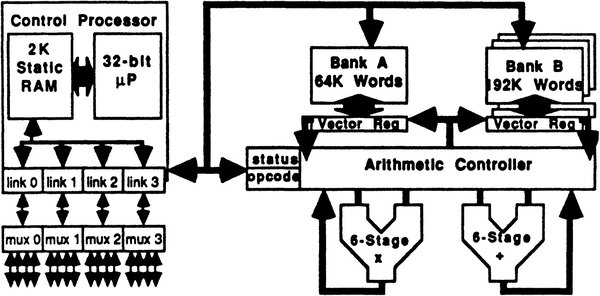
FPS Tシリーズのノード構成
これは32bitプロセッサーであり、内部に2KBのSRAMを搭載するとともに、内部に4本のプロセッサー間双方向リンク(5/10/20MHzで1bit幅)を搭載するという、やや独特な構成である。
このトランスピューターの構成は、連載284回で紹介したnCUBEのnCUBE 10を彷彿させるものがあるが、登場時期で言えばこちらの方が先である。
性能は、T400シリーズ世代は0.5MIPS/MHzということで、15MHz駆動のT414で7.5MIPSということになるが、もともとこちらは上の画像にもあるようにControl Processorで、アクセラレーターとの命令/データのやり取り、それとホストや隣接ノードとの通信のみなので、それほど高い性能は不要と判断されたようだ。
一方その右にあるArithmetic Controllerの実体はWeitekのFPUである。正確な型番が不明なのだが、資料によれば32bit/64bitの演算を125ナノ秒毎(8MHz)に実行可能で、ピーク性能は16MFLOPSながら、実際にはオーバーヘッドがあり12MFLOPSとされる。
このスペックに一番近く、また登場時期を考えると一番可能性が高いのはWeitekのWTL2264/2265あたりではないかと思うのだが、正確にはわからない。
ちなみにWTL2264は乗除算のみ、WTL2265が乗除算以外の演算になっており、2つのチップで対になって利用される。このT414とWTL2264/2265の間を、1MBのDual Port RAMが繋ぐ形になっている。
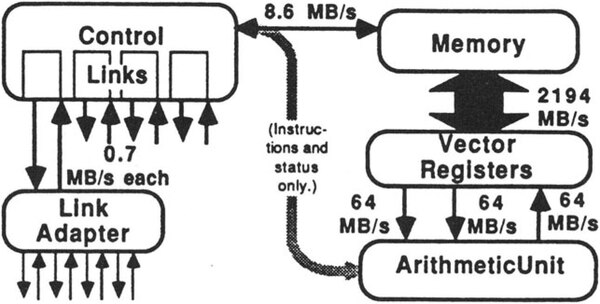
Arithmetic Controllerの実体はWeitekのFPU。こちらはWTL2264/2265用のメモリーとも言うべき扱い。MemoryとVector Registerとの間の帯域が異様に大きいのは、MemoryとVector Registerが複数のバンクに分かれているからで、これらのアクセス帯域を合計するとこの巨大な値になる
資料を読む限りでは、Control Processorからも自由にメモリーにアクセスできるのだが、ここにプログラムを置いて実行できる構造になっているかは不明である。
おそらくプログラムはT414内部の2KBのSRAMに格納し、データだけが外部の1MBメモリーに格納される構造になっているのであろう。
この各々のノードがどう構成されるのか、が下の画像だ。基本的な構造はN=4のTesseractで、これを仮想的に2D/3D MeshやRing/FFTなどの任意の構造にマッピングすることが可能なのも特徴であった。
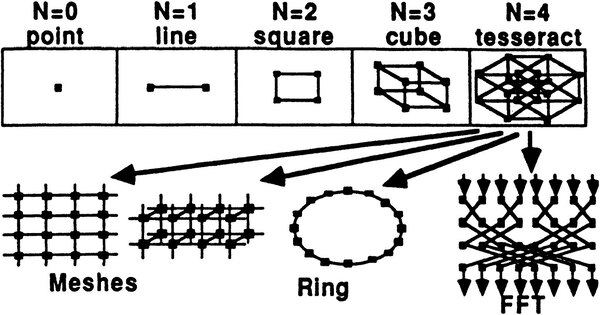
ノード構成。「アプリケーションに最適な構造を自由に」といっても、それを設計するのがまた難しい
※ここまでの画像出典は、FPSのD.A.Tanqueray氏の“The Floating Point Systems T Series”という1988年の論文。
ちなみに1つのノードは1枚のボードに搭載され、ノード8つをまとめて1つのモジュールと呼ぶ。このモジュールにはディスクも接続され、また外部I/Fも用意された。2つのモジュール(つまり16ノード)で1つのキャビネットを専有し、このキャビネット1つが上の画像で言うところのTesseractを構成できる最小構成となる。
実際にはより大きな構成も可能とされており、同社の試算では4キャビネットでのピーク性能は768MFLOPSに達するとしており、最大構成では256キャビネットで49GFLOPSの性能が確保できると説明していた。
基本設計はそのままに改良を加えた
第2世代FPS Tシリーズ
この最初のFPS Tシリーズは不評だった(なぜかは後述)のだが、そこであきらめずに同社は1988年に第2世代のFPS Tシリーズを発表する。第1世代との違いは以下のとおり。
- Control ProcessorをT414からT800に変更する。T800はInmosの第2世代プロセッサー(初代がT400)で、動作周波数を最大30MHzまで引き上げたほか、オンチップメモリーを4KBに増量、さらに64bitのFPUも搭載した。ところが、FPS TシリーズではこのT800のFPUは使っていなかったようだ。実際に利用したのはT800-20MHzで、性能は10MIPSとされている。
- コントロールプロセッサーに外付けで256KBのプログラムメモリー(DRAM)を追加搭載。やはり2KBのSRAMだけではメモリー量が絶望的に不足していたらしい。
- FPU用のメモリーを5ポート/4MBに強化。
- ベクトルプロセッサーに外付けでμシーケンサーを搭載。
- FPUそのものは引き続きWTL2264/2265が利用されたが、若干動作周波数が引き上げられた。
- 最大ノード数を16384まで引き上げた(初代は16ノード×256キャビネットで4096)。
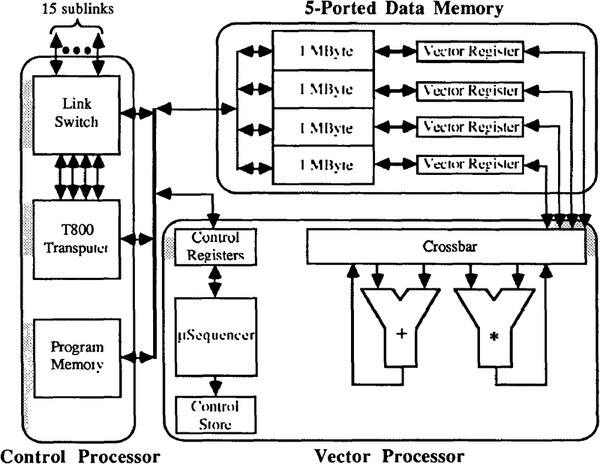
第2世代のFPS Tシリーズ。マイコンではあるまいし、いくら超並列とはいえ2KBのSRAMでプログラムが収まるとは思えなかったのだが、案の定である
基本的なアーキテクチャーは変えずに、ハードウェア的にボトルネックになっているところに手を入れた、という感じである。ちなみにそのベクトルプロセッサー部の内部構造が下の画像である。
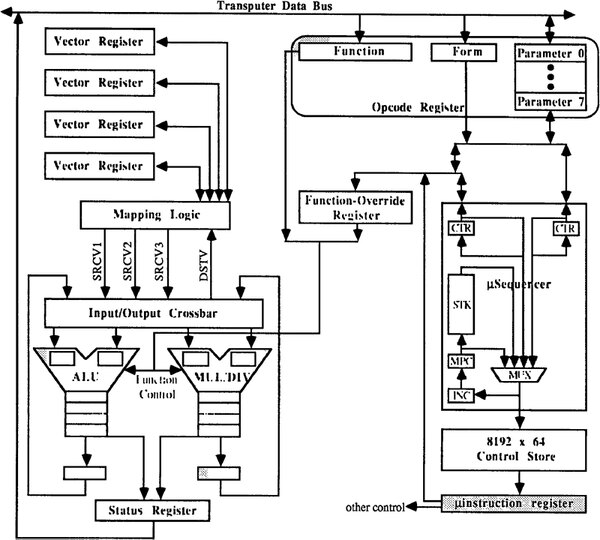
第2世代のFPS Tシリーズに搭載されたベクトルプロセッサーの内部構造。Sequencerというのは「シーケンス(手順)を与えるとそれを忠実に実行してくれる」というもので、CPUとよく似ているが、もう少し機能が少なく、その分高速かつ軽量である
この画像の場合、T800からあらかじめシーケンスをTransputer Bus経由でμSequencerに与えると、そのシーケンスがControl Storeに蓄えられる。あとはT800からどのパラメーターを使うかの指定だけを行なうと、μSequencerはそのパラメーターに該当する手順をControl Storeから抜きだしてWTL2264/2265に送りつけて処理を行わせる仕組みと見られる。
もともとWTL2264/2265はとにかくレジスターに値が書き込まれたら、それをベースに計算して結果を出力する「だけ」のチップなので、外部で動作制御を行なう必要がある。
初代はこれをT414が直接制御していたのだが、これでは間に合わなかったのだろう。μシーケンサーが別に用意され、これが最終的にWTL2264/2265のファンクションコントロールを制御する形になっている。
初代のFPS Tがノードあたり平均12MFLOPSに対し、第2世代ではノードあたり19MFLOPSとされ、加えて最大ノード数が増えたことで、理論上は311GFLOPSものマシンが構築できることになる。
(→次ページヘ続く 「幻と消えた第2世代FPS T。原因はソフトウェア」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ









































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












