




黒歴史扱いのGeForce GTX 480だが
GPGPUとしては高性能
GF100では内部構造を大幅に変更した。下の画像がGF100の全体の構造だが、4個のGPC(Graphics Processor Cluster)から構成され、各々のGPCは4つのSM(Streaming Multiprocessors)から構成される。

GF100の構造。総トランジスタ数32億個。TSMCの40nmプロセスを使い、ダイサイズは529平方mmに達した。以降の資料はNVIDIAのGF100のホワイトペーパーより抜粋
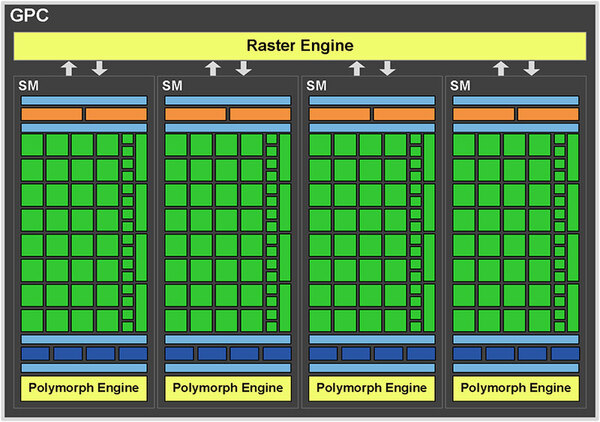
GPCの内部構造。4つのSMから構成されるこのGPCが4つ集まってGF100になる
Raster Engine、つまり描画はGPCあたり1組が用意されるが、こちらはGPGPUにはあまり関係がない。そのSMの内部構造が下の画像で、SMあたり64個のCUDAコアと16基のLoad/Store Unit、さらに4つのSFUから構成される。
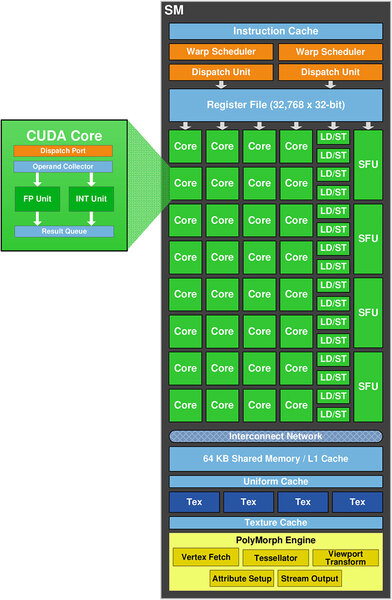
SMの内部構造。SPAの構造と比較するとわかるが、テクスチャーユニットの位置が変更になっている
CUDAコアと呼ばれているものは、SP(Streaming Processor)と呼んでいたものが改名された形だ。ただ、単に名前を変えただけではなく多くの改良点もある。
まず大きいのは倍精度浮動小数点演算のサポートで、単精度の半分の性能での計算が可能になっている。また共有メモリーは64KBに増やされ、同時に実行できるWarp(NVIDIAの用語で、32本のスレッドを一塊にしたプログラム制御の単位)を倍増。さらに内部のアドレスを64bit化して4GBを超えるメモリーも扱えるようになり、整数演算についても一部64bit幅に拡張がなされている。
そのうえGigaThreadと呼ばれる新しいタスク制御用のエンジンを搭載し、コンテキストスイッチングを10倍高速化したり、同時に複数アプリケーションを動かしたり、あるいはスレッドのOut-of-order実行を可能にするなど、G80~GT200世代で問題とされていた項目に対して一定の回答を行っている。Atomic処理に関しても専用の機構を搭載した。
そもそもシェーダー数が多いうえに動作周波数も高くなっているため、当然ながら性能も引きあがる。コンシューマー向けのGeForce GTX 480の場合、16個あるSMの1つを無効化して15SM構成になっていたが、シェーダーの動作速度は1.4GHzに達しており、演算性能はFloatの場合で1.4×15×32×2=1344GFLOPS、Doubleの場合でも半分の672GFLOPSに達しており、これは登場時点でのいかなる製品と比較しても十分に高性能だった。
ただこのGF100をベースにしたGeForce GTX 480は黒歴史扱いされるにふさわしいほど問題の多い製品だった。ピーク性能さえ出れば許容されるコンシューマー向けですら酷評だったわけで、より長時間に渡って高い負荷をかけ続けるHPC向け用途には極めて厳しいものだった。
同じGF100でもTeslaは高評価
NVIDIAがGF100を発表したのは、GeForce GTX 480の発売の4ヵ月ほど前となる2009年11月のこと。TOP500でおなじみSC09の開催にあわせ、ここでTesla C2050/C2070の製品発表を行なった。

Tesla C2050のリファレンスカード
ただしこのC2050/2070(と、後にC2075も追加)はいずれもSMが448基とされ、SMの数が14しかない計算になる。動作周波数は1150MHzに抑えられ、一般出荷は2010年5月まで伸びた。
もっともTeslaの場合、広く一般売りというよりは特定の研究機関や大学と契約して随時導入になるので、出荷日そのものはあまり意味を成さない。出荷日前に出荷され、システムに組み込んで評価をしたりソフトウェアの移植を始めたりするからだ。
TeslaのHPCマーケットでの反応は悪くなかった。2010年6月のTOP500で2位に入った中国NSCS(National Supercomputing Centre in Shenzhen:国立スーパーコンピュータセンター深セン)の星雲(Nebulae)というシステムは、「Xeon X5650」×4にTesla C2050を1枚組み合わせたマシンを4640台、Infinibandでつなぐという力技構成で1271.0TFLOPSを実現している。
もっとも理論性能は2984.3TFLOPSなので効率は42.6%とかなり低いし、システム全体の消費電力は2580KWで、性能/消費電力は0.49GFLOPS/Wに過ぎないため、効率はお世辞にもよくない。
ただ、続く2010年11月のTOP500を見ると、TOP5のうち3システムがTesla C2050を使っているほどである。そしてその数はこの後次第に増えていくことになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












