




























【デモあり】ELYZA、商用利用可能な70億パラメータの日本語LLM「ELYZA-japanese-Llama-2-7b」を一般公開
株式会社ELYZA
Llama 2をベースに開発、日本語の公開モデルでは最高水準
言語生成AIの社会実装を進める東京大学松尾研究室発・AIスタートアップの株式会社ELYZA(代表取締役:曽根岡侑也、以下ELYZA)は、Meta Platforms, Inc.(以下Meta)が開発した大規模言語モデル(以下LLM)である「Llama 2」に対し日本語による追加事前学習を行ない、商用利用可能な70億パラメータの日本語LLM「ELYZA-japanese-Llama-2-7b」を開発し、一般公開しました。本モデルは公開されている日本語のLLMとしては最大級の規模です。また、研究および商業目的での利用が可能なモデルとしての公開となります。性能評価の結果、1750億パラメータを有する「GPT-3.5 (text-davinci-003)」に匹敵するスコアが算出されており、日本語の公開モデルのなかでは最高水準の性能となっています。

モデルの詳細は、技術ブログにて扱っています。
https://note.com/elyza/n/na405acaca130
また、本モデルを用いたchatUI形式のデモもHugging Face hub上で公開しております。
https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-7b-instruct-demo
https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct-demo
※アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。
■ニュースサマリ
・ELYZAが「Llama 2」ベースの日本語LLM「ELYZA-japanese-Llama-2-7b」を一般公開
・国内の言語生成AI開発をリードすべく、日本語LLMの研究開発を加速する目的
・2023年8月現在公開されている日本語のLLMとしては最大級の規模
・研究および商業目的での利用が可能
・性能は「GPT-3.5 (text-davinci-003)」に匹敵、日本語の公開モデルのなかでは最高水準
・chatUI形式のデモ、推論用コード、性能評価用のデータセットと具体的な評価結果シートも合わせて公開
■「Llama 2」とは
「Llama 2」は、2023年7月18日にMetaが公開した英語ベースの大規模言語モデルです。先に公開された「LLaMA」が研究用途に限定されていたのに対し、「Llama 2」は商用利用も可能となっています。公開されているモデルとしては非常に性能が高いことから、OpenAIの「GPT-4」やGoogleの「PaLM」などのクローズドなLLMと競合する形で、英語圏では既にオープンモデルのデファクトスタンダードとなりつつあります。
サイズは70億、130億、700億の3種類となっており、いずれのモデルも教師ありファインチューニング(Supervised Fine-Tuning、SFT)及び、人間からのフィードバックに基づいた強化学習(Reinforcement Learning from Human Feedback、RLHF)を施したchatモデルを同時に公開しています。
■今回のモデル公開に込める願い
現在日本では、複数の企業が独自に日本語LLMの開発に取り組んでいますが、2兆トークンものテキストで学習されたMetaの「Llama 2」などと比較すると、まだまだ小規模なものに留まっているのが現状です。
その背景には、計算リソースの不足や、日本語で利用できるテキストデータの少なさなどがあります。また、一からLLMの事前学習を行うには膨大なコストがかかるため、研究を行えているのは一部の大企業や研究機関のみとなっています。
そのようななかELYZAでは、英語を始めとした他の言語で学習されたLLMの能力を日本語に引き継ぎ、日本語で必要な学習量を減らすことで、日本語LLMの研究開発を加速させることができるのではないかと考え、多言語LLMの日本語化に注目してきました。
今回はそのプロジェクトの成果の一つとして、Metaの「Llama 2」をベースに日本語の能力を向上させたモデルの開発に成功したため、その一部を公開することとしました。また、近日中に公開予定の技術ブログでは、「Llama 2」を日本語化する中で得られた知見やノウハウについての詳細を共有する予定です。
既に130億、700億パラメータのモデルの開発にも着手しており、それらのモデルについても公開を検討しています。ELYZAでは、モデルやノウハウの公開を通して、研究室やスタートアップ、個人などでも日本語LLMの研究開発に取り組める土壌を整えることで、日本語LLMの研究を加速させることを目指しています。
■今回のモデルについて
「ELYZA-japanese-Llama-2-7b」はMetaの「Llama-2-7b-chat」に対して、約180億トークンの日本語テキストで追加事前学習を行ったモデルです。学習に用いたのは、OSCARやWikipedia等に含まれる綺麗な日本語テキストデータです。複数のバリエーションがあり、ELYZA独自の事後学習を施した「ELYZA-japanese-Llama-2-7b-instruct」や、日本語の語彙追加により高速化を行った「ELYZA-japanese-Llama-2-7b-fast-instruct」が存在します。
70億のパラメータ数は、公開されている日本語のLLMとしては最大級の規模となります。
また、ライセンスはLLAMA 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能です。
性能について、ELYZA独自作成の性能評価の結果、1750億パラメータを有する「GPT-3.5 (text-davinci-003)」に匹敵するスコアが算出されており、日本語の公開モデルのなかでは最高水準の性能となっています。
図1 日本語の公開モデルのなかで最高水準

図2 1750億パラメータを有するGPT-3.5 (text-davinci-003)にも匹敵
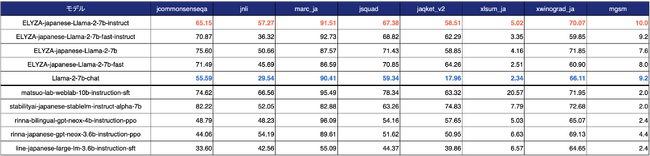
※ELYZA独自作成の「ELYZA Tasks 100」による性能評価。データセットの詳細と具体的な結果についても技術ブログにて公開。
その他、技術ブログにて以下内容を詳しく扱っています。ぜひご覧ください。
https://note.com/elyza/n/na405acaca130
・公開モデルの全バリエーション
・開発時に用いた推論用コード
・性能評価結果(ELYZA Tasks 100、ならびにlm-evaluation-harnessによる)
・性能評価に用いたデータセットと具体的な評価結果シート
また、本モデルを用いたchatUI形式のデモも公開しております。ぜひお試しください。
https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-7b-instruct-demo
https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct-demo
※アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。
■今後の展開
今回公開した「ELYZA-japanese-Llama-2-7b」シリーズは、「Llama 2」の最も小さいサイズである70億パラメータのモデルをベースに開発したものです。「Llama 2」には130億、700億パラメータのモデルも存在しており、ELYZAではそれらのモデルの日本語化にも既に着手しています。近いうちによりパワーアップしたモデルをお届けできるよう、開発を進めてまいります。さらに「Llama 2」での取り組みに限らず、海外のオープンなモデルの日本語化や、自社独自の大規模言語モデルの開発に継続して投資をしてまいります。
今後もELYZAは、国内の言語生成AI開発をリードすべく、国内の言語生成AIのリーディングカンパニーとして、日本全体のLLM活用やLLMの技術力向上を加速する目的で、得られた成果について商用利用可能なかたちでの公開、または企業案件を通じて社会に還元してまいります。
■ELYZA会社概要
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当て、企業との共同研究やクラウドサービスの開発を行なっております。先端技術の研究開発とコンサルティングによって、企業成長に貢献する形で言語生成AIの導入実装を推進します。
社名 :株式会社ELYZA
所在地 :〒113-0033 東京都文京区本郷3-15-9 SWTビル 6F
代表者 :代表取締役 曽根岡侑也
設立 :2018年9月
URL :https://elyza.ai/