




好きな服装、好きなポーズが指定可能に
専用LoRAを開発することで多様な一枚絵を使えることがわかってきたことで、応用範囲はさらに広がってきました。
Kohyaさんは5月8日に、“開始画像”にキャラと衣装を並べて、それっぽいプロンプトで生成すれば、勝手に参照して衣装を変えてくれるのではないかと予想。実験をしたところ、低確率ながら、それが実現できることを発見しました。さらに5月21日、マスクで覆うことで変化してほしいところを指定する方法(furusuさんが考案)を利用することで、その部分だけ衣装を変えることに成功します。それが、ヒントとなり実際の実装になったのです。
FramePackで開始画像にキャラと衣装を並べて、それっぽいプロンプトで生成すれば、勝手に参照して衣装を変えてくれるんじゃね……と思ってやってみたら、成功率すごく低いけどできた。左の列がstart画像、中央と右の列がFramePackの1フレーム推論画像。最上段は参照画像を入れない例。 pic.twitter.com/XZ6aa7rP5Y
— Kohya Tech (@kohya_tech) May 8, 2025
FramePackで背景と衣装の同時変更できた。キャラの立ち絵を開始画像にしてlatentを顔部分のみにマスク、メイド服とキッチンを両方history latentとして参照して、二枚目画像を生成。
— Kohya Tech (@kohya_tech) May 21, 2025
ちょっと構図が変なのと、ザラザラしちゃう。 pic.twitter.com/NPUp2nNE8P
とりにくさんは翌週の5月28日、1枚絵の画像を出力することだけを目的とした「Framepack_imgGEN」を発表。起動するだけでインストールに必要なことをすべてやってくれるので、アプリが導入しやすくなりました。
これは、FramePackに様々な機能を追加したirvashさんによる改造版を使って、Codeさん(x_ai_code)が多機能化を施した「FramePack-eichi(叡知)」を使っています。それをさらに改造して、1枚絵の作成専用にしたものです。前述の回転機能「rotate_indoor」と同様のこともimgGENで実行可能です。1回目の生成にはモデルを読み込むために時間がかかるのですが、2回目以降はかなり短時間で生成できるようになりました。
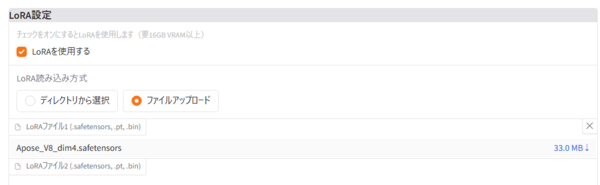
Framepack_imgGENでミスをしやすい点として、LoRAを指定する場合は「ファイルアップロード」を通じてドラック&ドロップをする必要がある。「ディレクトリから選択」は機能していないようだ。また動作させる際には、それぞれのLoRAごとにプロンプトの指定が必須なので、作者の指定の確認が必要
とりにくさんはその後も次々に専用LoRAを発表しています。まず、Kohyaさんと協力しながら、任意のキャラクター画像を「Aポーズ」(棒立ち)画像に変換できるLoRAを公開。次に、Aボース画像があれば、任意のポーズに変えるLoRAや、写真を二次元ポーズの参考として使えるLoRAなど、次々に新しいLoRAを公開しました。

AポーズLoRA(Apose_V8_dim4)の作例。右画像からAポーズを作成した。解像度640を指定した場合には全身像が出なかったが、解像度960を指定すると全身像が出力されが、常にではなく、シード値によるランダムのよう

素体ポーズLora(body2img_V7_kisekaeichi_dim4)の作例。Aポーズ画像を使っての画像変更例。ポーズ集はとりにくさん公開のものを利用。かなりうまくポーズがそのまま生成されている

写真を参考にするLoRA(photo2chara_V6_dim4)の例。AポーズLoRAで作成した画像を、右側の写真画像(Midjouneryで作成)を参照して生成したもの。特に下は難しいものを意図的に選んだがかなり正確に捉えている
これらの技術は、マスクで指定しなくても、FramePack用のLoRAを使えば着せ替えを実現できることの発見につながり、冒頭で紹介したLoRAの開発につながっていくのです。
6月1日には、さわらさん(xhiroga)が、ComfyUI向けの動作環境「ComfyUI-FramePackWrapper_PlusOne」を発表。kisekaeichi関連技術は、より汎用的な環境で動作するようになりました。
Kohyaさんは、FramePackでkisekaeichiが動作する仕組みを解説する記事を発表されていますが、「LoRAは恐らく、FramePackのモデルが元々持っている動画生成モデルとしての知識を、特定の条件でうまく引き出すためのトリガーとして働いている」と説明しています。
また、「LoRAを適用してもそれだけでは推論がうまくいかず、適切なプロンプトを指定する必要がある、プロンプトの記述によりLoRAの効果が異なる」といったまだまだ性質として不明点があることも触れられています。まだまだ、完全にコントロールするためには不明点も多く試行錯誤が続いているのです。
この連載の記事
-
第130回
AI
グーグルNano Banana級に便利 無料で使える画像生成AI「Qwen-Image-Edit-2509」の実力 -
第129回
AI
動画生成AI「Sora 2」強力機能、無料アプリで再現してみた -
第128回
AI
これがAIの集客力!ゲームショウで注目を浴びた“動く立体ヒロイン” -
第127回
AI
「Sora 2」は何がすごい? 著作権問題も含めて整理 -
第126回
AI
グーグル「Nano Banana」超えた? 画像生成AI「Seedream 4.0」徹底比較 -
第125回
AI
グーグル画像生成AI「Nano Banana」超便利に使える“神アプリ” AI開発で続々登場 -
第124回
AI
「やりたかった恋愛シミュレーション、AIで作れた」 AIゲームの進化と課題 -
第123回
AI
グーグルの画像生成AI「Nano Banana」は異次元レベル AIコンテンツの作り方を根本から変えた -
第122回
AI
動画生成AI「Wan2.2」の進化が凄い アリババが無料AIモデルの牽引者に -
第121回
AI
愛していたAIが消えた日 ChatGPTだけと“付き合う”危うさ -
第120回
AI
ラフさえ描けばイラスト作品ほぼ完成 画像生成AI「FLUX.1 Kontext」LoRAが示す制作の未来 - この連載の一覧へ










































