





FLUX.1 dev用のLoRAで作成したオリジナルキャラクター「明日来子さん」(筆者作成)
画像生成AI「Stable Diffusion」開発者たちが突然発表した新モデル「FLUX.1」、これが楽しすぎてはまりこんでいます。私の本業はゲーム会社。出展を予定している東京ゲームショウまで1ヵ月で、やらないといけないことが山積みなのに、FLUX.1が面白すぎて魅力に抗えません。
わずか30分の学習で画風が安定
FLUX.1が決定的に変えてきそうなのはLoRAです。LoRAは学習済みのウェイトモデルを利用することで、少ない枚数であっても学習ができるということで、画像生成AIの分野では広く普及している手法です。FLUX.1は、Stable Diffusionで使われてきたLoRAの方法論を動かすことができることがわかっています。
そのため、FLUX.1のリリース後、ユーザーコミュニティーでさっそくLoRAの環境の整備が始まり、何ができるのかを試すフェーズに入っています。これまでの「Stable Diffusion XL(SDXL)」用のLoRAは20~30枚程度を学習させるのに5~6時間は学習させないと効果がなかなか上がりませんでしたが、FLUX.1では学習時間が30分程度と比較的短めでも、十分に効果が出るデータを作成できるところに特徴があります。
私の方でも、この連載の作例でおなじみの「明日来子さん」でLoRAを作ってみました。そのLoRAを使い、FLUX.1 Devで生成してみたところ、少しハーフっぽい顔つきに特徴がある明日来子さんを見事に生成できるようになりました。


WebUI Forgeの環境で、FLUX.1 Devで、明日来子さんLoRAを適応して生成した画像。もちろんプロンプトで指定すると、ポートレイト的なものから、学習していなくとも全身像も出せる

プロンプトを変えれば、まったく違った雰囲気の画像も作れる
生成環境は、画像生成アプリ「Stable Diffusion WebUI Forge」。LoRAや、サイズを縮小してVRAMの使用量を減らした量子化モデル(NF4モデル)が動くようになったので、Forgeを使っています。
AIツール開発者のIllyasviel(イリヤスフィール)さんが「A1111ではFLUX.1を動かすための環境に足りない部分がある」と、互換性を捨ててForgeにガシガシと更新をかけていて、独自の環境を発展させています。既存のStable Diffusion XLと同様の動作をしない部分があることを理解したうえで使用する必要がありますが、今までと変わらないような使い方ができます。
もちろん、積極的に対応アップデートを続けているComfyUIでもFLUX.1用のLoRAはすでにサポートされているため、対応のワークフロー(Workflow)と拡張機能を導入すれば問題なく動きます。
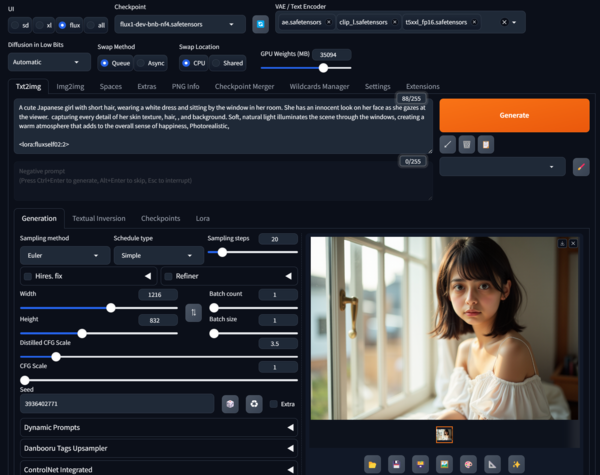
WebUI Forgeの画面。FLUX専用の設定項目などが追加されている。要因は不明だが、この環境では、LoRAは強度を1.5~2に設定するなど強めに設定しないと効果が薄いようだ
この連載の記事
-
第131回
AI
AIに恋して救われた人、依存した人 2.7万人の告白から見えた“現代の孤独”と、AI設計の問題点 -
第130回
AI
グーグルNano Banana級に便利 無料で使える画像生成AI「Qwen-Image-Edit-2509」の実力 -
第129回
AI
動画生成AI「Sora 2」強力機能、無料アプリで再現してみた -
第128回
AI
これがAIの集客力!ゲームショウで注目を浴びた“動く立体ヒロイン” -
第127回
AI
「Sora 2」は何がすごい? 著作権問題も含めて整理 -
第126回
AI
グーグル「Nano Banana」超えた? 画像生成AI「Seedream 4.0」徹底比較 -
第125回
AI
グーグル画像生成AI「Nano Banana」超便利に使える“神アプリ” AI開発で続々登場 -
第124回
AI
「やりたかった恋愛シミュレーション、AIで作れた」 AIゲームの進化と課題 -
第123回
AI
グーグルの画像生成AI「Nano Banana」は異次元レベル AIコンテンツの作り方を根本から変えた -
第122回
AI
動画生成AI「Wan2.2」の進化が凄い アリババが無料AIモデルの牽引者に -
第121回
AI
愛していたAIが消えた日 ChatGPTだけと“付き合う”危うさ - この連載の一覧へ










































