




連載583回の最後でQualcommのCloud AI 100の話を少しだけした。この時には「Qualcommのことだからきっと量産を開始しても内部の詳細は公開しない気がするが」と書いてしまったが、意外にも(失礼)Hot Chips 33で内部構造をもう少し公開した。さらに9月22日にML CommonsがMLPerf 1.1の結果を公開したのに合わせて、実シリコンを利用しての詳細な性能も公開した。そこで、今回はこれを説明したい。
メモリーアクセスがボトルネックにならない設計
まず内部構造について。もともと1つのシリコンで最大16コアの構成になっていたが、その内部構造が下の画像だ。
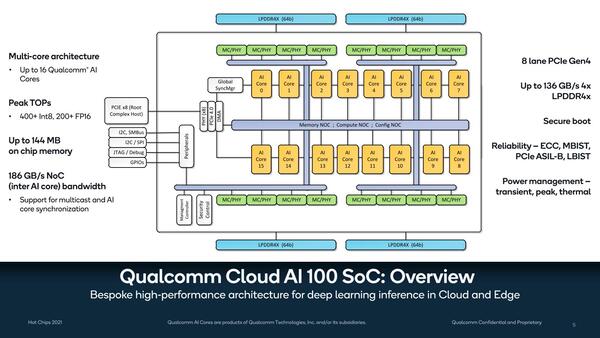
Cloud AI 100の内部構造。よく見るとメモリーコントローラーも16個あり、つまりメモリーアクセスはコアごとに独立して行なえることになる。コントローラーあたり16bit幅なので、LPDDR4X-4266だとすると8.5GB/秒の独立した帯域を利用できる計算になる
16個のコアがNOC(Network On Chip)でつながる構造になっており、メモリーコントローラーもNOCに直結している格好だ。メモリーがLPDDR4X-4266なら、合計で256bitなので合計帯域は136GB/秒超になるが、NOCそのものは全部で186GB/秒とこれを上回る帯域になっているあたりは、メモリーアクセスをしながら、さらにコア間の通信を行なってもボトルネックにならないように工夫されているものと思われる。
また信頼性でECCによる保護のほかにMBIST(Memory Built-In Self-Test)機能があるあたりまではわかるが、PCIeに関してはASIL-B(ISO26262 ASIL-B:自動車向けの機能安全規格)とLBIST(Logic Build-In Self-Test)機能が搭載されているあたりは、産業用やサーバー向けだけでなく、車載向けにも色気を見せている感じだ。
実際Qualcomm自身も自動車向けにけっこうソリューションを出しているので、長期的には自動車に搭載されることを見込んでの対策かもしれない。
ちなみにISO26262 ASIL-Bの場合、故障率が100FIT(平均故障回数が10億時間あたり100回)未満、つまり平均して1000万時間に1回未満の故障回数であることが求められる(ほかにもいろいろ要件があるが)。
しかも単にその故障率を達成するだけでなく、それを達成するための仕組みや、それが正しく実装されたことを証明するための手順書や履歴など、シャレにならない膨大なドキュメントを残す必要もある。このための手間とコストは、車載向けを当初から想定しない限り正当化できないレベルのもので、このあたりにもQualcommの本気さが伝わってくる。
個々のコアの中身は下の画像のとおり。メインとなるScalar Unitは4-way VLIW構成で、しかもマルチスレッドという構成。このマルチスレッドの制御がどうなっているのかは非常に興味あるところである。
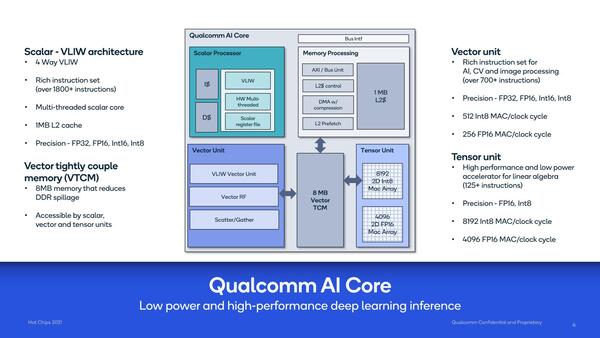
1800以上の命令とはあるが、VLIWの場合は単に順列組み合わせの可能性があるので、個々の演算ユニットレベルで言うとどこまで命令の種類があるかは謎だ
VLIWでマルチスレッドの実装例はけっこうあるが、Itaniumのように命令ユニットレベルでの並列動作をサポートしているケースは割とレアであり、ほとんどのケースでは例えばメモリーアクセス待ちが発生したらスレッドを切り替えるというメモリーアクセスの遮蔽にマルチスレッドを利用している。
これは命令ユニットレベルでの並列動作をやろうとすると、アウト・オブ・オーダーのプロセッサーのように命令ユニットの手前にスケジューラーが必要になり、機構が複雑になるためだ。
後述するが、Cloud AI 100の場合はメモリーアクセスを極力オンチップ(というより、オンコア)のキャッシュ+TCMでまかなうようにしている(そもそもメモリーアクセス待ちが発生したら効率が悪化する)ことを考えると、この方式だとマルチスレッドの効果が薄いようにも思われる。ただ残念ながらこれに関する詳細は説明がなかった。
演算の中心はこちらよりも、Vector UnitやTensor Unitと思われる。Vector UnitはやはりVLIW構成とされるが、Scatter/Gatherユニット(メモリーアクセスのように飛び飛びになっているデータをひとまとめにしたり、その逆を行なう仕組み)を搭載しているあたり、MIMDに近い演算ユニットのようにも思える。
Scalar Unitとの差は、おそらくScalarの方は制御命令などを含む一般的な演算や、特殊演算などもカバーした汎用的なもので、その代わり演算のスループットそのものはそう高くなさそうだ。
一方Vector Unitは複数個(FP32をサポートするあたり、同時に16個くらいは並んでいるかもしれない)の演算を同時に処理できるが、演算は多少限られる格好になるのだろう。
そしてTensor Unitの方はもう完全に積和演算に特化したもので、こちらはアクセラレーターのような扱いとなり、それこそ畳み込みだけをひたすら演算するような用途で利用されると思われる。
これをサポートするのが8MBのTCM(Tightly Coupled Memory)であるが、そのTCMと外部のメモリー(や、別のコア内のTCM)とのデータ交換を行なうのがMemory Processing Unitである。要するにDMAエンジンではあるのだが、ここにも1MBの2次キャッシュが搭載されている。コアごとにTCM+L2で9MB。これが16コアでトータル144MBのメモリーが搭載される形だ。冒頭の画像の“Up to 144MB on chip memory”がこれである。
VLIWプロセッサーをメインにしているあたりはあまり一般的ではないが、演算はVector Unitに逃がし、さらに特定の処理のみはアクセラレーターとしてTensor Unitを搭載するというあたりは比較的今風で、ヘテロジニアス構成の教科書に出てきそうな構成である。
コアあたり9MBというSRAMが十分かどうかはここまでの説明だけでは判断が難しいが、例えばTensor UnitはInt 8で毎サイクルあたり8K MAC演算が可能なので、データとウエイト、結果の格納で1サイクルあたり最大で24KB消費する。
ということは、MAC演算だけをひたすらやっている限りは、TCMだけで300サイクル以上をぶん回せる計算である。実際にはウエイトが毎サイクル変わることは少ないだろうし、結果をそのまま格納せずに総和を取ったりすることを考えると、倍程度のサイクルをこなせることになる。これだけ時間があれば、次のデータを外部メモリーから取り込むことは難しくないだろう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















