




10nmではトランジスタ密度を2.7倍に増すことで
14nm世代の倍近いと言われるコストを下げる
こうした細かな積み重ねによって、トランジスタ密度を2.7倍にできた、というのがインテルの主張である。ちなみにこのトランジスタ密度であるが、インテルによる数え方は下の画像の通り。

トランジスタ密度の計算式。言ってみればライブラリの両極端のセルを抜き出して、そこに重み付けを掛けた形。“more accurate estimate”(より厳密な推定)というからには、おそらく実際の回路と比較して検証した結果であろう
当然Cell Libraryの種類によってトランジスタ数が異なるわけで、インテルでは2入力NANDとScan FlipFlopの2種類のトランジスタ密度を6:4の比で重み付けしたものを利用する、としている。
トランジスタ密度が増すことで、SRAMのサイズもどんどん小さくなる。最近は大容量キャッシュの搭載などで、ダイの上に占めるSRAMの比率がだんだん増えつつあるので、SRAMの面積は重要なメトリックとなる。
14nm世代では0.0588μm2と発表されていたが、10nm世代ではHP(高速・高消費電力)が0.0441μm2、LV(低速・低消費電力)が0.0367μm2、HD(高密度)が0.312μm2と説明されている。
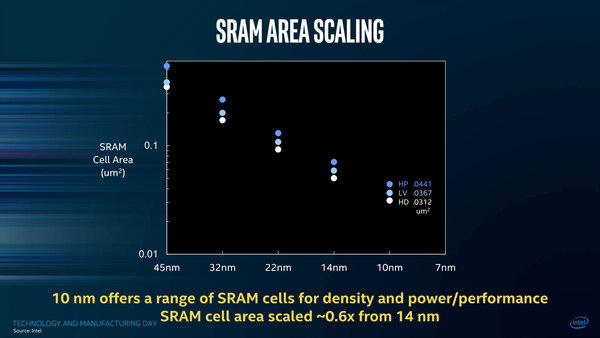
SRAMのサイズ。ちなみに14nm世代の0.0588μm2はLVで、HPでは0.0706μm2、HDだと0.0499μm2と発表されている
面積比で言えば60%前後(58~62%)ということで、2.7倍にはやや遠いものの、かなり密度が上げられることがわかる。
この結果として、例えば45nm世代では100mm2だったダイを、回路そのままで微細化すると7.6mm2まで縮小できる、というのがインテルの主張である。なぜこれを強調するかといえば、要するにコストの問題である。

ダイエリアのサイズ。22nm世代までは世代毎に62%程度に面積を縮小していたのが、14nm世代以降は43%ほどに縮めているということで、14nm以降がHyper Scalingとされるわけだ
インテルの主張は一貫して「プロセスを微細化することで、トランジスタコストは下がる」であり、これを実現するためにはプロセスコストそのものの低減とあわせて、よりトランジスタ密度を上げる必要がある。
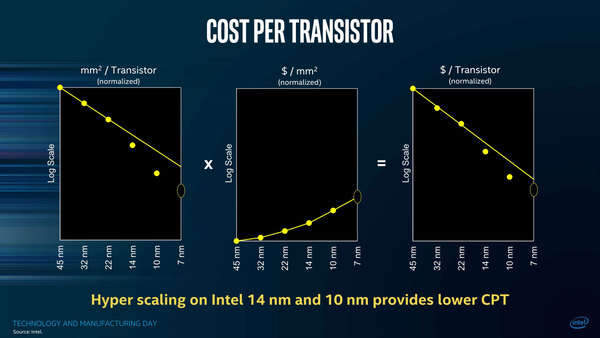
トランジスタのコスト。ついに7nm世代がこの図に載ってくることになった
特にファウンダリービジネスを全力で推進する以上、コスト競争力は絶対的に必要になる。そうでなくてもインテルのファウンダリーは「性能はともかくコストが高い」という評判がずっと変わっておらず、この評判を払底するためにも、そして自社の製品の競争力を高めるためにも、トランジスタあたりのコストを下げていかないといけない。
上の画像の真ん中の図を見ていただくとわかるように、絶対的なコストは確実に上がっている。図は「単位面積あたりのコスト」という単位だが、ウェハーのサイズは300mmで変わらないので、結局これが絶対コストとほぼ同義語になる。
縦軸が対数であることを考えると、10nm世代のコストは14nm世代の倍近いと推察され、ところがトランジスタ密度を2.7倍にしたからトータルでは14nmより割安になる、という主張はインテルが絶対に崩せないものらしい。
もっとも現実問題としてインテルの製品を見ると、ダイサイズ一定でむしろ機能を詰め込む(コア数を増やす、3次キャッシュを増やす、シェーダーの数を増やすなど)方向になっており、そうなると製造原価は上の画像にある中央のように次第に上がっていく傾向にあるわけで、インテルのファウンダリーを使う顧客がこの状況をどう思っているのか、聞いてみたいところではある。
話を戻すと、この10nm世代についても、10nmと10nm++についての性能の指標が一応出ている。10nmは14nmと比較して25%の性能アップ、ないし45%の消費電力削減が実現できるとするが、10nm++はこの10nmと比較しても15%の性能アップ、ないし30%の性能実現が可能ということになる。
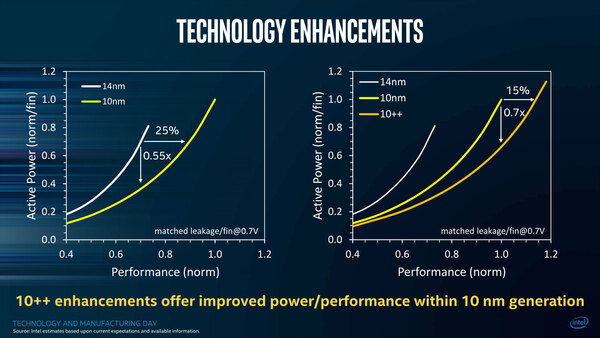
なぜ10nm+が入ってないのかはよくわからない。10nm+は10nmより若干性能は改善すると見られる。とはいえ、14nm++ほどではないと予測されるためだろうか?
ただ、性能改善率は14nmと比較すると大きいが、14nm+と比較するとさほどではない。Kaby Lake世代と比較した場合、あまり動作周波数の改善は期待できないだろう。
2018年中に利用可能になる(=製品投入は2019年になると思われる)10nm+を利用した製品は、14nm++より多少落ちる程度まで性能が改善しそうなので、そこまで辛抱するしかない。実際それもあってインテルはCannon Lakeはモバイルのみにしたのだろう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















