
キャッシュのチューニングにより
待機時の消費電力も削減
もう1つは、キャッシュの構成をかなりチューニングしたことだ。2次キャッシュは容量を倍増させながら面積は67%増しに留めており、3次キャッシュは同容量のまま17%ほど面積を節約していることがわかる。その2次キャッシュの構造が下の画像だ。
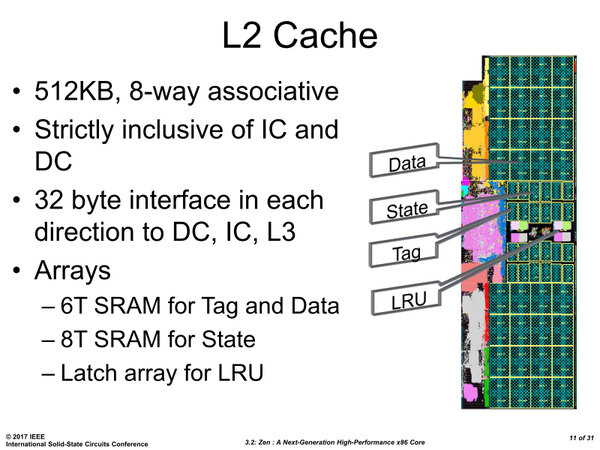
2次キャッシュの構造。タグは「どのメモリーアドレスのデータがキャッシュのどこに格納されているか」を保持するもの。言うなれば行先掲示板や住所録となる
データとタグについては、サイズと省電力を優先して6T SRAMで、ステート(状態)については安定性と高速性を優先して8T SRAMで構成されている。ステートはあまり見かけないが、これは2次キャッシュと3次キャッシュが排他で保持されることと関係する。
つまり2次キャッシュに入っているデータは3次キャッシュから落とされるし、逆に3次キャッシュに入っているデータは2次キャッシュには乗らない。これによりキャッシュを有効利用できる、というのはAMDの伝統的な技法である。
以前は1次~3次キャッシュまで全部排他関係であったが、Ryzenでは2次キャッシュ容量が大きくなったので、もはや1次キャッシュは排他にしなくてもそれほどメリットは大きくなく、むしろ排他制御に要するデメリットが減るという判断をした。
排他制御の場合は、あるアドレスのデータがそもそもどこにあるか(2次か3次かメモリーか)をきちんと管理しなければいけない。この管理のためにステートという領域が必要とされる。ただ全体としてみればそう大きい領域ではないので、ここは速度優先にしても問題ないと判断された模様だ。
一方の3次キャッシュであるが、こちらは大容量ということで、密度最優先で6T SRAMが用いられ、また一番省電力のトランジスタが利用されているようだ。
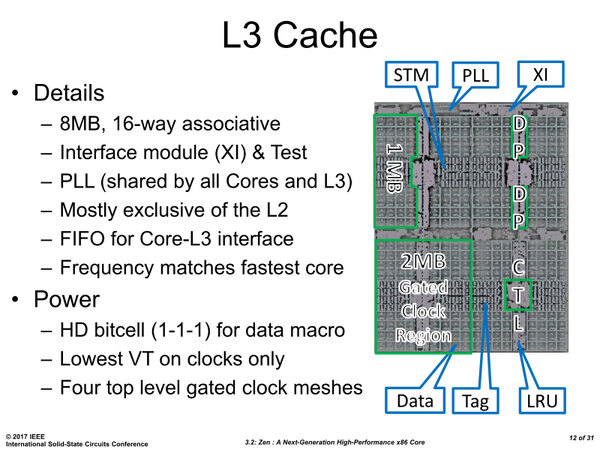
3次キャッシュの構造。実際には8MBの3次キャッシュは2MBづつ分割され、それぞれ別々にClock Gatingが行なわれる。また高速なトランジスタ(Lowest VT)は唯一クロック信号にのみ使われるとしている
おもしろいのは、3次キャッシュの速度も可変だが、それはコアの中でもっとも高速なものにあわせる構造になっていることで、これで待機時の省電力化が可能となっている。
さて、それよりおもしろいのが排他制御の方式である。先も書いたが、2次/3次キャッシュで排他制御しているため、毎回「どちらのキャッシュにデータが置かれているか、もしくは、どちらにもおかれていないか」を確認する必要がある。
これがボトルネックになって性能が上がりにくい、というのはK10などでは顕著だったのだが、それを高速化するための仕組みがShadow Tag Macroである。3次キャッシュの側に、2次キャッシュタグの1/4(おそらくはアドレスの先頭1/4)のコピーを保持しておくというものだ。
アクセス要求が出たら、まずこのコピーを参照して、そもそもヒットしそうかどうかを確認する(これがステージ1)。このレベルでヒットしないなら、2次キャッシュにはそのデータが存在しないということなので、あとは3次キャッシュにアクセスすれば良い。
一方ここでそのコピーとヒットするようであれば、「このデータは2次キャッシュに存在する可能性あり」と判断される。そうなって初めて2次キャッシュのタグにアクセスしてヒットするかどうかを確認する(これがステージ2)という仕組みだ。
この制御方式により、いきなり2次キャッシュTagにアクセスする場合に比べて76%の消費電力節約になったとしている。
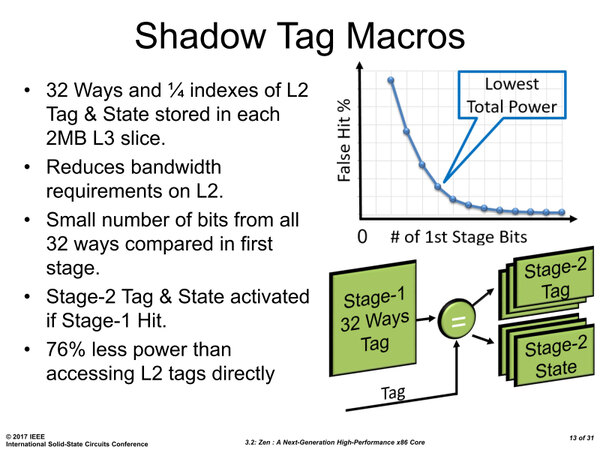
Shadow Tag Macroの構造。ここで1クッション入る分、若干レイテンシーは増える計算になるが、それよりも無駄に2次キャッシュタグを検索する分の消費電力を削減できる方が効果的と判断したのだろう
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ












