
8コア16スレッドのIntel 「Broadwell-E」の性能を上回る
一方省電力に関しては、従来の28nm SPPから14nm LPPに切り替えたことでより省電力動作が可能になっているが、これに加えていくつかの工夫によって更に省電力化を進めたとしている。もう少し細かく説明しよう。
Clock Gatingは不要なブロックのクロック供給を止めて待機状態にする(ことで消費電力を下げる)仕組みで、これを複数レベルのRegionで実施しているとする。おそらくは(不要ブロックの電源供給をもカットする)Power Gatingも複数レベルで実装されているだろう。
またμOp-Cacheを搭載したことで、ここにヒットしている間はデコードを止められる。昨今のプロセッサーの場合、ユニット単位で言えば間違いなくデコードが一番電力を喰っているので、これを止められる効果は大きい。

これはあくまで論理実装レベルでの工夫という話と思われる。もっともClock Gatingは論理実装レベルなのか物理実装レベルなのか、判断が難しい
Stack EngineはK10世代のSideband Stack Optimizerと同じものなのか、あるいは例えばBranch Predictionとなにか連携するような仕組みなのかは不明だが、いずれにせよなにかしら実装がなされているようだ。
Sideband Stack Optimizerと同じだとすれば、スタックの操作の際にALUを動かさずに専用回路で処理することで消費電力を減らせる(ついでにALUを空けられる)というメリットがあり、主に省電力に効果的である。
次のMove eliminationは、Mov命令(データを指定の領域あるいはレジスターにコピーする)を愚直に実行するのではなく、Register Renamingの段階で実施してしまう方法だ。これはある意味古典的な技法であるが、ALUを動かさずにRenamingの段階で処理が終るので、やはり省電力に効果的である。
ちなみに今回のスライドにはなかったが、AMDはBristol Ridgeの世代でAVFS(Adaptive Voltage Frequency Scaling)や信頼性トラッキング、BTC(Boot Time power supply Calibration)といった消費電力最適化技法を導入している。
さらにZenと同じく14LPPを利用するPolarisではこれに加えてMBFF(Multi-bit flip-flop)というテクニックを採用して省電力化を進めている。おそらくはこうした技法も当然Zenに搭載されていると思われる。
こうした工夫の結果、Zenコアは消費電力はExcavatorコアと同等のまま、IPCを40%程度改善できた、としている。
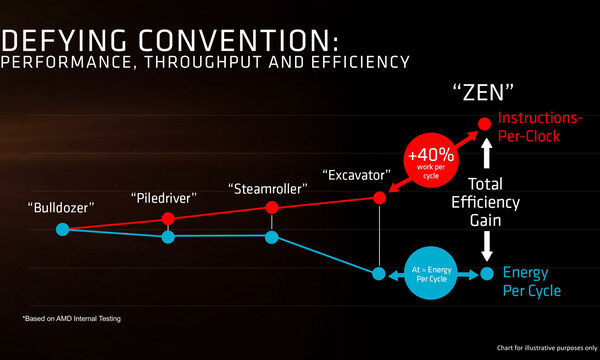
普通に考えれば回路規模が巨大化したり大容量キャッシュを搭載した分消費電力は増えるが、これをプロセス変更や、さまざまな省電力メカニズムで帳消しにできた、ということと思われる
この「Excavatorと同レベル」というのは、なにもしなくてもモバイル向けのPower Profileを実現可能という意味で、当初はデスクトップ、次いでサーバーになるが、モバイルにも十分入れられる実力はあることになる。
またZenに続き、Zen+が投入されることも明らかにされた。Zen+の投入はおそらく2017年末~2018年になるであろう。

当然ながらZen+に関する詳細な説明はなかった
ちなみに性能であるが、発表会では3GHz駆動で8コア/16スレッドのSummit Ridgeのエンジニアサンプルと、同じく3GHz駆動で8コア/16スレッドのBroadwell-Eを並べ、BlenderのCPU Rendering性能を比較するというデモを実施している。下の動画の1:30あたりからがそれだ。
これだけで性能云々を語るには情報が少なすぎるのだが、比較的良い勝負になるとAMDが考えていることは明らかになった。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ












