




Polaris世代の新機能は何か?
だいたいのスペックが分かったところで、次にPolaris(第4世代GCN)をアーキテクチャー面から眺めてみよう。SP64基とスケジューラー、やテクスチャーユニットなどで構成されたCompute Unit(CU)を並列配置、Asynchronous Compute Engine(ACE)でグラフィックタスクとコンピュートタスクを自在に混在できる、という基本設計に変化はないものの、随所に様々な進歩が見られる。主なものを紹介しよう。
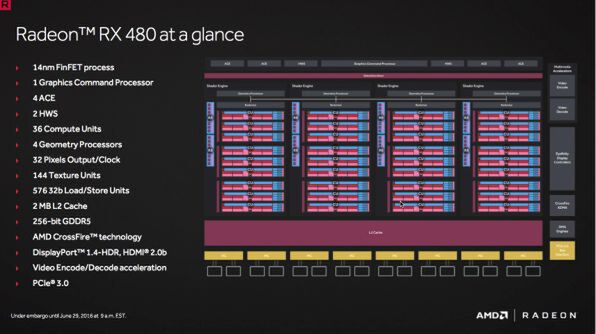
RX 480のブロック図。CUと書いてある小さなブロックに64基のSPやL1キャッシュなどが詰め込まれている
【1】ジオメトリーエンジンの強化
モデリングが複雑になるとジオメトリーの処理が重くなる。さらにテッセレーションで凹凸を増やせば、ジオメトリーの負荷はさらに増大する。これに対しAMDは2方向から解決を試みている。
ひとつは「Primitive Discard Accelerator」と呼ばれる機能だ。これはあるトライアングルを処理する際に、それが1ドットにも満たない大きさであると判断された場合は、そのトライアングルの処理をパイプラインの初期段階で捨てる機能だ。特にテッセレーションとMSAAと併用する場合に効果があるとしている。
そしてもう1つ、ジオメトリーはインデックスキャッシュに入れて再利用することも可能になった。繰り返し利用するジオメトリーが多いほどスループットが向上するというわけだ。
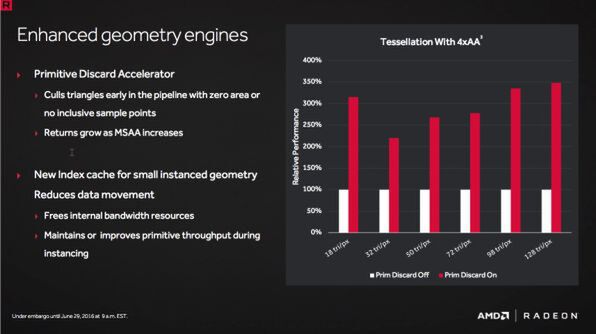
テッセレーションと4xMSAAを併用する状況では、特にPrimitive Discard Acceleratorが威力を発揮する。図ではトライアングルが1ピクセルあたり18~128個ある時のパフォーマンスの違いを図示したもの。おおむね2倍~3.5倍の向上が見込めるようだ
【2】シェーダーとメモリーバスの効率化
根本的な処理性能を上げるには、シェーダーそのものの処理効率を上げる必要がある。そこでPolarisではCUに命令プリフェッチを機能を搭載することで、処理の効率化を図っている。さらにCUの外側にあるL2キャッシュの容量を倍にし、キャッシュ効率も向上させた。
これにより色圧縮(最大8:1の高圧縮にも新たに対応)の効率も上がったほか、メモリーバスの利用頻度が下がることでGPU全体の省電力化につなげることに成功している。

命令プリフェッチやL2キャッシュの改善でR9 290よりもCU1基あたり15%も性能が向上しているとうたっている
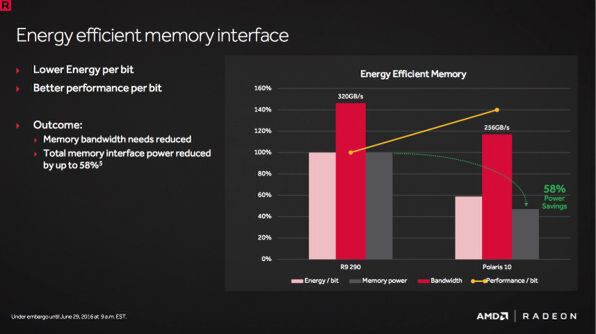
RX 480はメモリーバス幅が512bitのR9 290よりも純粋な帯域は狭くなったものの、メモリーインターフェースやL2キャッシュの改善などで実質的なパフォーマンス(黄線)は上がり、1ビットを送るのに必要な電力も低下。特にメモリーインターフェースの電力は最大58%低下したという
【3】Asynchronous ComputeとVRの強化
シェアではライバルに押されまくっているAMDだが、GCNアーキテクチャーが備えるAsynchronous Computeは非常に魅力的な機能だが、Polarisでまた一段階進化している。
特にVRではプレイヤーの視線の動きに合わせて画像を遅滞なくレンダリングすることがVR酔いを防ぐために必要だが、AMDはAsynchronous Computeを利用することで、いつでも必要な時にグラフィックタスクとコンピュートタスクを同時処理できるとしている。
ライバルのGeForceもPascalでようやく“プリエンプション”を実装し、タスクの素早いスイッチングを可能にしたが、同時処理の方がよりエレガントだ。とはいえこれまでの実装だと、コンピュートタスクはグラフィックに対し従の関係にあったがめ、コンピュートタスクを発行しても結果が希望する時間内に得られないこともある。
そこでPolarisでは「Quick Response Queue」と呼ばれる機能を実装、グラフィックとコンピュートタスクに割り当てる比率を決定し、必要な時間内に結果を得られるようになった。
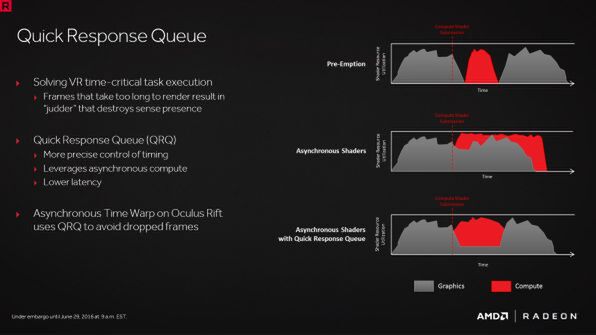
従来のAsynchronous Compute(真ん中のグラフ)はグラフィックタスク(グレー)の余力でコンピュートタスク(赤)を処理するため終了が長引く可能性があるが、Quick Responce Queueを利用することで一定の比率で2つのタスクを併存させ、必要なタイミングで結果を得られるようにしている
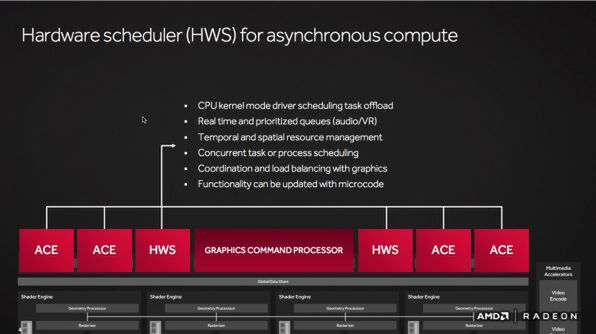
グラフィックとコンピュートの負荷を調整するのはHardware scheduler(HWS)。優先度の高いVRや音声(TrueAudio Next)処理等を決める部分だが、ここにマイクロコードを送り込むことで挙動を変更することができるため、負荷のバランスを外部から調整できるのも大きな強み
またAMDのVR環境「LiquidVR」では、CUの一部をオーディオ用として割当て、レイテンシーのリスクを負わずに高度なオーディオ処理「TrueAudio Next」が利用可能になる。GPUとレイトレーシングの技術を応用したVR向けオーディオ処理はライバルも取り組んでいるが、Quick Response Queueを利用することで音が遅れて出てしまうことを防止できる
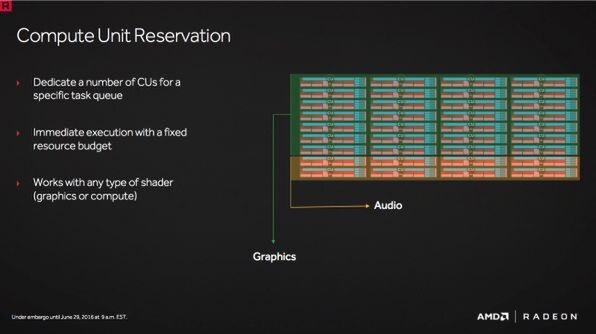
TrueAudio NextではCUの一部をオーディオ用に確保しておくことができる。突発的にサウンド処理が必要になっても、すぐに処理に入れるというわけだ
この連載の記事
-
第439回
自作PC
暴れ馬すぎる「Core i9-14900KS」、今すぐ使いたい人向けの設定を検証! -
第438回
デジタル
中国向け「Radeon RX 7900 GRE」が突如一般販売開始。その性能はWQHDゲーミングに新たな境地を拓く? -
第437回
自作PC
GeForce RTX 4080 SUPERは高負荷でこそ輝く?最新GeForce&Radeon15モデルとまとめて比較 -
第436回
デジタル
環境によってはGTX 1650に匹敵!?Ryzen 7 8700G&Ryzen 5 8600Gの実力は脅威 -
第435回
デジタル
VRAM 16GB実装でパワーアップできたか?Radeon RX 7600 XT 16GBの実力検証 -
第434回
自作PC
GeForce RTX 4070 Ti SUPERの実力を検証!RTX 4070 Tiと比べてどう変わる? -
第433回
自作PC
GeForce RTX 4070 SUPERの実力は?RTX 4070やRX 7800 XT等とゲームで比較 -
第432回
自作PC
第14世代にもKなしが登場!Core i9-14900からIntel 300まで5製品を一気に斬る -
第431回
デジタル
Zen 4の128スレッドはどこまで強い?Ryzen Threadripper 7000シリーズ検証詳報 -
第430回
デジタル
Zen 4世代で性能が爆上がり!Ryzen Threadripper 7000シリーズ検証速報 -
第429回
自作PC
Core i7-14700Kのゲーム性能は前世代i9相当に!Raptor Lake-S Refreshをゲーム10本で検証 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























