




1 BeatでMAC演算が可能だが
システム的には2命令/サイクル扱い
命令を解釈するハードウェアであるが、全体像は下の画像のような感じである。内部はInteger Unit(I0~I3)、Floating-Point Unit(F0~F3)、Memory Controller(M0~M7)、I/O Processor(IOP0~IOP1)、それとGlobal Controller(GC)から構成される。
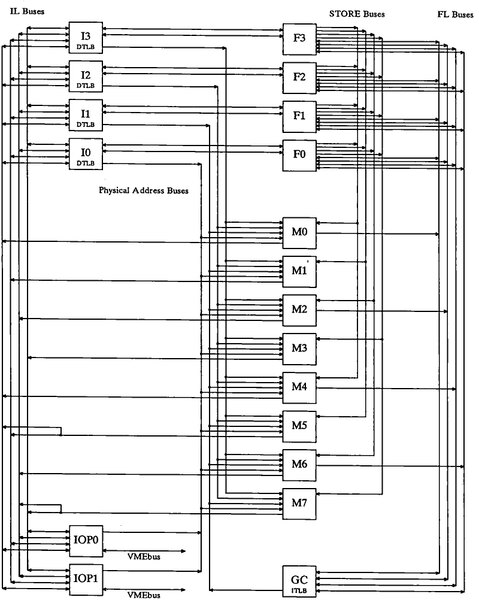
システム構造。1980年代後半なので、もちろん各々のモジュールは別々の基板になっている
画像の出典は“Multiflow Technical Summary”
Integer UnitとFloating-Point Unitは8000ゲートの2μmゲートアレイで構成され、それ以外の部分はTTL ICで構成された。
全体としての動作サイクルは130ナノ秒(7.7MHz)だが、実際にはこの半分の65ナノ秒(15.38MHz)のクロックが出ている。TRACE /200ではこれを“Beat”と称する。TRACE /200のALU/FPUのスループットは2命令/サイクルとされるが、これは少し話がややこしい。
下の画像がALUとFPUの内部構造であるが、どちらも2つの実行部が内部に含まれているのがわかる。
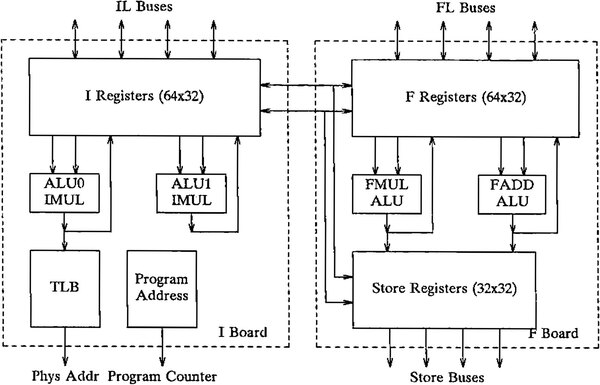
ALUとFPUの内部構造。実質的にはALUが8つ、FPUが8つあるような形と考えればいい
画像の出典は“Multiflow Technical Summary”
TRACE /200の場合、1 BeatでMAC演算(乗算と加算)が可能であるが、例えば1 Beatの最初の半分の時間で加算、残りの半分で乗算というオペレーションが可能になるためで、先の命令フォーマットの画像で“Early Beat”や“Late Beat”という表現が出てくるのがこれを示している。
つまり内部的には実質1命令/Beatで処理は行われるのだが、システム的に見ると2命令/サイクルと扱われるという話だ。
ちなみに整数演算に関してはパイプラインディレイは存在しないが、浮動小数点に関してはパイプラインディレイが命令によって変化する。資料によれば、64bitの倍精度の加算では6 Beat(390ナノ秒)、乗算では7 Beat(455ナノ秒)を必要とする。
メモリーコントローラーはそれぞれ4枚のメモリモジュール(DRAM)を接続できる。どうも1枚のメモリーモジュールそのものが2wayのインターリーブ構成が可能なようで、システムにフル実装した場合は64wayインターリーブ構成となり、1Mbit DRAMを利用してトータルで512MBの容量となる。
ちなみにこのページの最初にある画像の構成は、Trace 28/200のシステムである。モジュール式なので個々のモジュールは簡単に増減可能であり、これを組み合わせて3種類のシステムが用意された。これをまとめたのが下表であるが、プロセッサーの数に応じて命令長も増える、というあたりがなかなか斬新ではある。
| Trace /200シリーズの性能 | ||||||
|---|---|---|---|---|---|---|
| 名称 | TRACE 7/200 | TRACE 14/200 | TRACE 28/200 | |||
| ALU数 | 1 | 2 | 4 | |||
| FPU数 | 1 | 2 | 4 | |||
| 命令幅(bit) | 256 | 512 | 1024 | |||
| 処理性能(ops/cycle) | 7 | 14 | 28 | |||
| 命令キャッシュ容量(KB) | 256 | 512 | 1024 | |||
| VILW MIPS | 53 | 107 | 215 | |||
| MFLOPS(単精度) | 30 | 60 | 120 | |||
| MFLOPS(倍精度) | 15 | 30 | 60 | |||
| メモリバス幅(MB/sec) | 123 | 246 | 492 | |||
| メモリ容量(MB) | 32~512 | |||||
しかし、これはマシンの構成によって命令フォーマットが変わるという話でもあるし、そもそもVLIWの発想は(Itaniumなどがそうであるように)プロセッサー内部の動作制御を全部ソフトウェア側で行なうことでハードウェアを簡潔化しつつ高性能を実現しようというものだから、ソフトの開発は大変になる。
Multiflowはこれに向け、3フェーズの開発環境を提供した。第1フェーズではまずFortranとC言語を、TRACE向けの機械語に変換する。
第2フェーズではこれの最適化が行なわれる。内部ではコードをグラフ展開し、データ依存性の排除やループ除去、動的変数の確認などをしたうえで最適化する。
第3フェーズでは実際のマシンモデル、つまりALU/FPUやメモリーコントローラーがいくつあるかなどを参照しながら曖昧性の除去や、実際のマシン上での実行スケジューリングなどを行ないつつ、最終的にマシンの構成にあわせた幅の命令を生成するというもので、なかなか手間がかかる作業になる。
実際のコード生成時間などは、利用するVAXの性能にもプログラムのサイズや複雑さにも依存するため不明だが、決して高速ではなかったようだ。
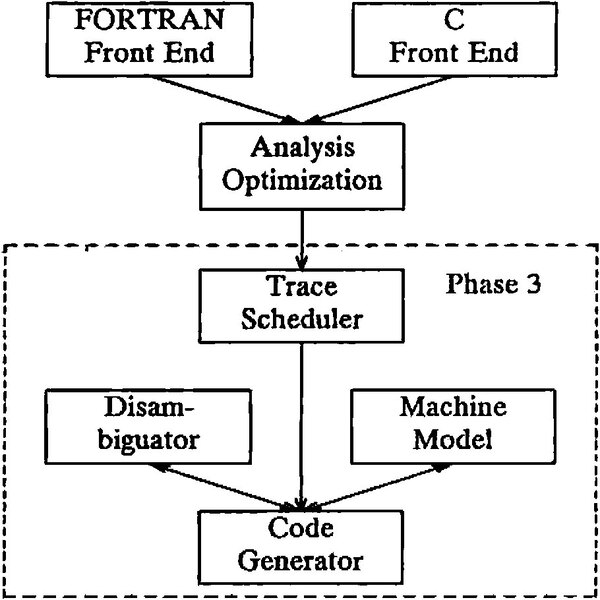
このコンパイラというか開発環境は、VAX/VMS上で動いていた模様
画像の出典は“Multiflow Technical Summary”
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























