




ネットワークは3種類で構成
ノード間の通信は3次元トーラス構造
さて、次にネットワークの話をしたい。Blue Gene/Lはこのキャビネットを64個並べ、理論性能で367TFLOPSを実現しているわけだが、ノード数は65536に達しており、適切なネットワークで接続しないと性能が出ない。
そこで、Blue Gene/Lでは、複数種類のネットワークが組み合わされている。ノード間の通信の基本は、3次元トーラス構造である。これは下の画像の(a)のようにそれぞれのノードを3次元構造で接続するもので、Blue Gene/Lでは8×8×8が基本になる。
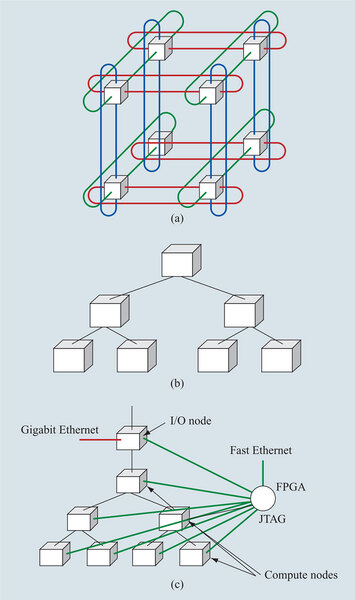
Blue Gene/Lのネットワーク。大別してこの3種類のネットワークが存在する
ノード数で言えば512で、ちょうどキャビネットの半分に相当する。なお、BlueGene/Lでは、これをmidplaneと称している。1ページ目で示したBlue Gene/Lのチップ構造の画像で、“Torus”と書かれたユニットがこの3次元トーラス構造用のリンクで、送受信それぞれ1.4Gbpsで接続される。
Blue Gene/L全体ではこのmidplaneが128個存在するが、Blue Gene/Lではこのmidplaneを1つのPartitionとして扱い、複数のmidplaneを利用する場合にはプログラム側でこれをハンドリングする(つまりmidplaneそのものを拡張したりしない)という形で制約を設けている。
これは、複数のシャーシにまたがって同期を取ったりすると、そこがボトルネックになりかねないので、あくまでも1つの処理は1つのmidplaneでこなすこととし、複数midplaneを使う場合は処理そのものをそれぞれ分割するというアプローチを取った。
midplane同士は、Link Chipと呼ばれる専用ASICを経由してケーブルで接続される。Link Chipの製造プロセスは130nmの「Cu-11」(関連リンク)を利用して製造されており、4種類の動作モードを持つ。
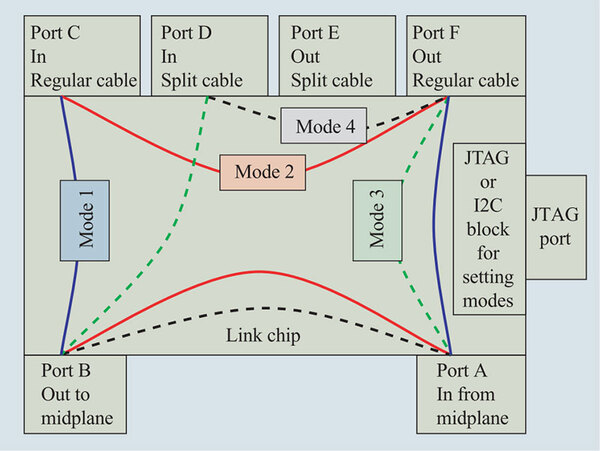
Link Chipの構造。これは要するにパーティショニングの際に、いちいち配線を繋ぎ変えなくても動作モードを変更することで、自身をそのパーティションに加えたり外したりするもの。ちなみに図ではPort Eが使われないことになっており、なにかか変だと思う
RegularとSplitという2種類のケーブルは、midplane間をつなぐものだが、通常の縦横高方向の配線がRegular、その規則から外れたものがSplitになる。
このLink Chip同士もまた3次元トーラスを構成する形になっているが、例えば下の画像のように1~8のユーザーがいて、それぞれ別々にパーティションを使いたいという場合、6~8のユーザーは横方向に全体を物理的につないでしまうとパーティション分けができないので、6/7/8の境のみ、横方向はSplitケーブルを用いて分離することになる。
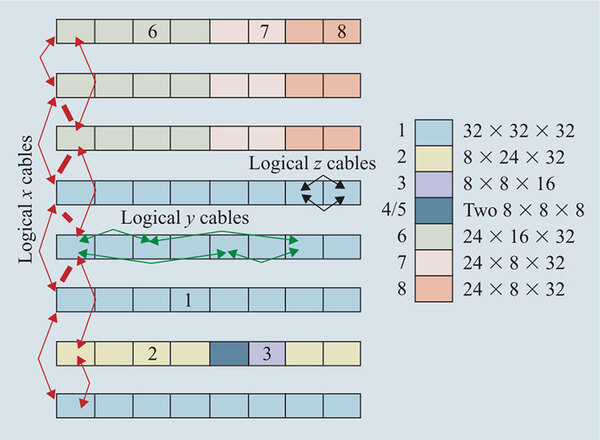
これはBlue Gene/Lのシステムを上から見た図。四角はそれぞれシャーシだと考えてほしい
ちなみにこの3次元トーラスの方は、1ノードあたり平均100ナノ秒のレイテンシーが必要である。なので、65536個の全ノードにデータを送信する場合、おおむねね6.4マイクロ秒ほど必要となる。
さて話を3種類のネットワークに戻すと、これとは別にCollective Networkと呼ばれるもの((b)の形態)がある。
Blue Gene/Lのネットワーク
こちらは全ノードへのブロードキャストを行なう場合などに使われるもので、帯域は2.8Gbps、レイテンシーは5マイクロ秒未満とされる。これが1ページ目で示したチップ構造の画像にあるCollectiveというユニットを利用する。
さらに、Barrier Networkと呼ばれるものも別途用意されている。これはシステムの同期を取る(各ノードが直ちに動作を止める)ためのもので、ノード数が65536であっても1.5マイクロ秒未満で同期を取れるように設計されている。
以上の3つがアプリケーション用のネットワークだが、他にGbE、それとデバッグ用のJTAGが別途ネットワークとして用意されている。上の画像の(c)がこれだ。
複数の施設に納入し
商業的にも成功を収める
こうした工夫によってBlue Gene/Lは高い性能を発揮した。Blue Gene/Lの最初のシステムはローレンス・リバモア国立研究所に納入されたが、まず4キャビネット(8192コア)が稼動した段階で11.68TFLOPSを発揮してTOP500の4位を取り、16キャビネット(つまり定格の4分の1)が稼動した2004年11月には70.72TFLOPSを発揮してTOP500の1位を地球シミュレータから奪い返す。
半数が稼動した2005年6月には実効性能136.8TFLOPS、フル稼働した2005年11月には実効性能280.6TFLOPSを発揮、以後2007年11月まで1位の座を維持し続けた。
ちなみに、このフルスペック構成では理論性能367TFLOPSに対して280.6TFLOPSなので効率は76.5%とそう悪くないし、性能/消費電力比で言えば280.6TFLOPSを1433KWで実現しているので、191.5KFLOPS/Wという計算になり、QCDOCと比較しても3.8倍ほど性能/消費電力比が改善している。
この後ローレンス・リバモア国立研究所は、シャーシを104個まで増強してピーク性能を596TFLOPSまで引き上げたほか、より小さなシステムが各所に納入されている。
例えば2006年11月のTOP500リストを見るとローレンス・リバモア国立研究所以外に、100位以内だけで14システムも納入されている。
| TOP500で100位以内にランキング入りしたBlue Gene/L | ||
|---|---|---|
| 順位 | コア数 | 所在 |
| 3 | 40,960 | IBM Thomas J. Watson Research Center |
| 17 | 12,288 | ASTRON/University Groningen, Netherlands |
| 21 | 8,192 | Computational Biology Research Center, AIST |
| 22 | 8,192 | Ecole Polytechnique Federale de Lausanne, Switzerland |
| 23 | 8,192 | High Energy Accelerator Research Organization /KEK |
| 24 | 8,192 | High Energy Accelerator Research Organization /KEK |
| 25 | 8,192 | IBM Rochester, On Demand Deep Computing Center |
| 42 | 6,144 | UCSD/San Diego Supercomputer Center |
| 61 | 4,096 | EDF R&D, France |
| 61 | 4,096 | EDF R&D, France |
| 62 | 4,096 | Harvard University |
| 63 | 4,096 | High Energy Accelerator Research Organization /KEK |
| 64 | 4,096 | IBM Almaden Research Center |
| 65 | 4,096 | IBM Research, Switzerland |
| 66 | 4,096 | IBM Thomas J. Watson Research Center |
なかにはKEKのように3システム(MOMO/Sakura/Ume)を運用しているところもあり、商業的にも成功した部類に入るとみなしていいかだろう。
このBlue Gene/Lの成功を受け、次にBlue Gene/Pの開発が始まるとともに、これに影響を受けてBlue Gene/CことCyclops64の開発も2004年に始まったが、これはまた別の機会に説明しよう。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ



































