




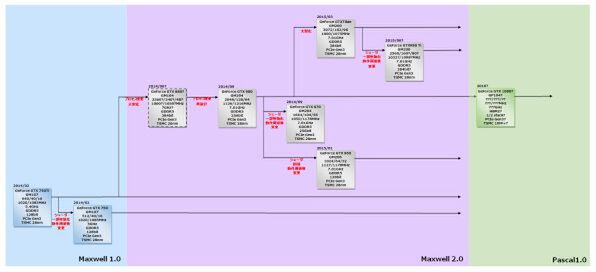
2014~2016年のNVIDIAロードマップ
単精度に特化したGPU
GeForce GTX TITAN Xを投入
話をロードマップに戻すと、GeForce GTX 970/960に続いて、今年3月のGTC 2015において、GM200コア搭載のGeForce GTX TITAN Xが発表された。

GeForce GTX TITAN X
これはけっこう意外な話で、GM204が最後の28nm世代製品と考えられていたが、もう一段中継ぎが投入された形だ。要約するとGM204の構成を1.5倍に増量したものである。ダイサイズは600mm2を超え、CUDA Core数は3072というお化けチップとなった。
性能は現時点のシングルGPUカードとしては間違いなくハイエンドである。なぜこれが投入されたかといえば、16nm世代がもうすこし時間がかかるからというのもあるが、それよりも戦略の変更があったことが見逃せない。
今年のGTC 2015の基調講演はひたすらにDeep Learning(深層学習)という話は塩田氏の記事をご覧いただくとして、そのDeep Learningには必ずしも倍精度演算が必要ないということが基調講演の中で明らかにされている。
Maxwellのアーキテクチャーは倍精度演算ユニットを持たないため、倍精度演算は複数の単精度演算ユニットを組み合わせて実施している。この結果、倍精度演算のスループットが単精度演算の32分の1程度とされており、実際GeForce GTX TITAN Xは単精度演算こそ7TFLOPSだが、倍精度だと0.2TFLOPSの性能しかない。
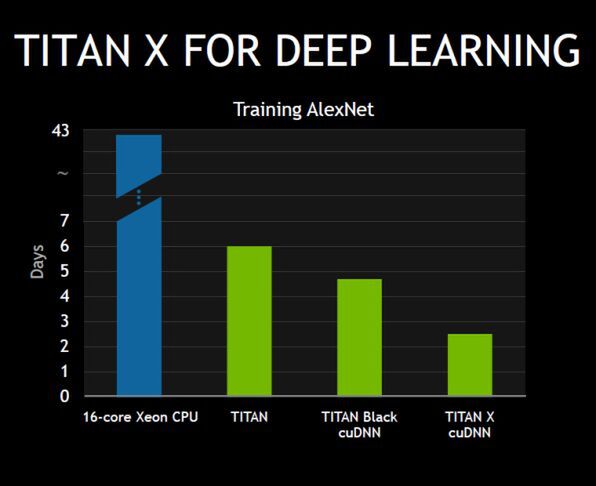
TITAN Xでは、Deep Learningの処理性能が前世代(TITAN Black)の2倍あるという
これは従来科学技術演算に使われてきたTesla系のGPGPUカードにはあきらかに不十分(GK110コアを搭載するTesla K20Xは倍精度演算で最大1.31TFLOPSを叩き出す)で、このためMaxwellコアをTeslaに利用する可能性はなく、大きなダイサイズを持つコアを作っても元が取れないと判断されたわけだ。
ところがDeep Learningなどの用途であれば倍精度はいらず、単精度あるいは半精度(16bit)でも使い物になる、というのが基調講演の中で示されたストーリーである。

基調講演でTITAN Xを披露するジェンスン・ファンCEO
Maxwellコアの場合、SIMD演算のように単精度演算ユニットで2つの半精度演算を同時に行なえる。この場合の演算性能はさらに倍増することになる。
要するに戦略の変更とは、単精度に特化したGPUの使い方をこれまで以上に追求することで、ここで新しい市場を開拓することである。
この考え方をさらに進めたのが、やはりGTCの基調講演で発表されたPascalである。以前はPascalがなく、Maxwellの次にVoltaが来るはずだった。
ところがその後NVLinkのサポートが付け加わったものがPascalとして示されたため、PascalとはVoltaにNVLinkを加味したものだと理解していたのだが、PascalとVoltaは別のもの、というよりVoltaとは別にPascalが追加され、その分Voltaが2018年にずれた格好だ。
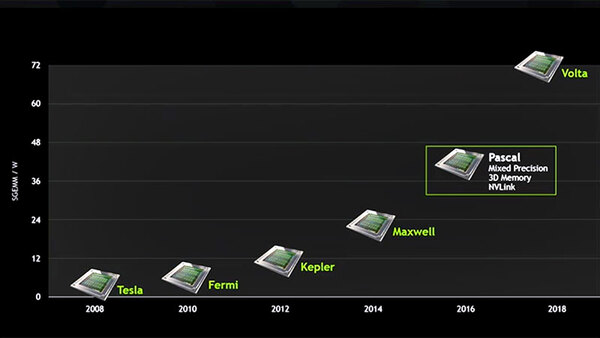
NVIDIAのGPUロードマップ。Voltaとは別にPascalが追加され、その分Voltaが2018年にずれる。画像はGTC 2015におけるジェンスン・ファン氏の基調講演より
→次のページヘ続く (2016年に投入予定のPascal)
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























