




1536ノードを接続したASC Purple
ネットワーク構成はASCI Qに酷似
前ページで解説したとおり、System P5 575は8P構成のSMPマシンで1ノードとなるわけだが、これを1536ノード接続したのがASC Purpleとなる。
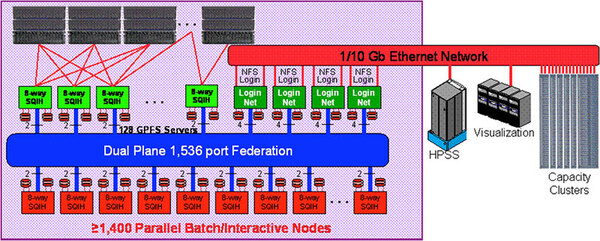
IBM System P5 575を1536ノード接続したものがASC Purpleである。ノード数自体は1548+2で1550個存在する。ローレンス・リバモア国立研究所のTom Spelce氏の論文より抜粋
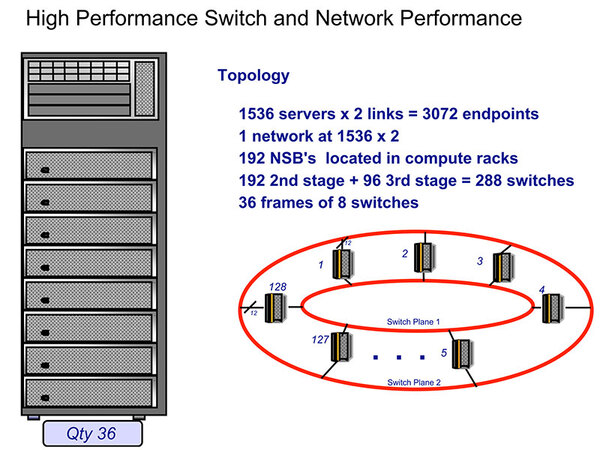
さすがに単一スイッチで1536ノード分はカバー仕切れないので、実際には3レベルのツリー構造という、どこかで聞いたような構成である。
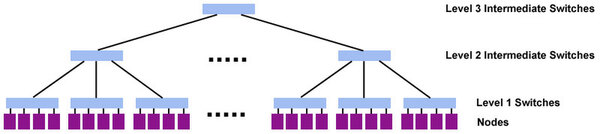
3レベルのツリー構造となるネットワークの概念図
もっともASCI Qは単なるFATツリーであったが、ASC Purpleはomegaネットワークの構成なので、単純にレベル数が同じでも同一には比較できない。またASC Purpleの場合、2Uユニット1枚に1ノードが収まる関係で、1つのシャーシに12ノード分を収めることができた。
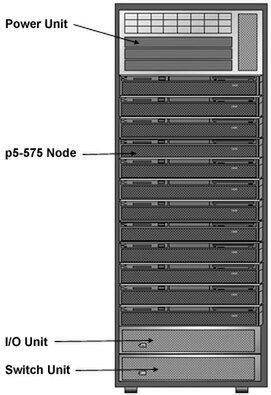
1つのシャーシに12ノード分を収められる。電源部が最上段というのが面白い。これもASC Purple解説ページより抜粋
ゆえに、前述のネットワークの概念図におけるLevel 1 Switchはシャーシの下部に納められ、配線の短さも相まって高速に接続された。下の画像がLevel 1 Switchの内部構造で、4×4のSwicthを使って32ポートのスイッチが構成されている。
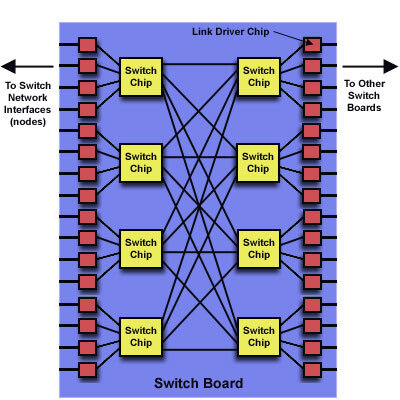
スイッチユニットの中身。1つのスイッチのレイテンシーは59ナノ秒なので、同じシャーシ内部の他のノードとの通信は118ナノ秒+α(配線遅延分)で通信できることになる。解説ページより抜粋
このうち16ポートがノードに割り当てられ、残る16ポートが他のフレームとの接続に利用される。Level 2以上に関しては、そもそもネットワークが二重化されており、Level 2が192、Level 3が96のノード数となる。
Level 3でもまだ96ものノード数というあたりが、3レベルでのツリーであってもそれほどレイテンシーを増やさずに済む要因だったのであろう。
スイッチの仕組み。ASC Purple本体以外のシステムもあり、これもあってスイッチはシャーシ192本分が用意されている
Tom Spelce氏の論文では、最大8192ノードまでの範囲で帯域やレイテンシーの測定を行なっているが、帯域では(通信メッセージや送信方法によるが)おおむねね目標である「理論帯域の45%」という効率に近い数字を達成している。
また、レイテンシーではマルチプロセッサーシステムで利用されるMIP_Allreduceという関数を実行するための所要時間が8192ノードの場合で150マイクロ秒前後に抑え込めていることを発表している。
目標の100TFLOPSに近い数値を達成
しかし莫大な消費電力が問題に
次に、納入システムである。ここまで説明してきた通り、ASC PurpleはPOWER5をベースとしたシステムであるが、これが公式にリリースされたのは2005年のことであり、そこから納入を始めてもアプリケーションの対応などが間に合わない。
そこで、まず2003年から2004年にかけて、EDTV(Early Delivery Technology Vehicles)として、POWER4ベースのIBM pSeries p655をベースとしたUM及びUVというシステムが導入される。これはどちらも8P構成の1.5GHz POWER4マシンを128ノードつないだ小規模なシステムである。
これに続き、2004年末から2005年にかけて、UP(Unclassified Purple)というSystem P5 575が108ノード構成のマシンと、1536ノードのPurpleが並行してインストールされ、2005年7月22日に利用可能となった。

ローレンス・リバモア国立研究所に納入されたASC Purple
このうち1280ノード(10240コア)を利用してLINPACKを実行した結果は63.4TFLOPSで、理論性能の77.8TFLOPSの81.5%に達して、2005年11月のTOP500で3位に入る。翌2006年6月には、1526ノード(12208コア)で75.8TFLOPSを叩き出し、引き続き3位の座を確保することに成功する。
効率も81.7%とやや改善しており、2010年11月19日にサービス終了までほぼ100TFLOPSに近いプラットフォームとして活用されてきた。もっとも、絶対性能はともかくとして、システム価格や運用コストがやはり問題視されることになった。
運用コストで問題になったのは主に電気代で、システムは7.5MWの電力を消費し、さらに発熱は毎時160万BTU(British thermal unit:英熱量)に達したため、冷却コストも馬鹿にならなかった。
そうしたこともあり、この後IBMはPowerPCベースのMPPの方向に推移することになる。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")





























