




Power Challangeの後継となるOrigin
512ノード/1024プロセッサーを目指す
まずは元になるOrigin 200/2000のシステムについて解説する。この当時、SGIはMIPS R3000ベースで最大8プロセッサーのPowerシリーズ、MIPS R4000ベースで最大36プロセッサーのChallangeシリーズ、それとMIPS R10000ベースのPower Challangeシリーズという3種類のラインナップを持っていた。
OriginはこのPower Challangeの後継製品にあたる。Power ChallangeはChallangeシリーズ同様に最大36プロセッサーのシステムだったが、Originは最大で512ノード/1024プロセッサーを可能にすることを目指していた。
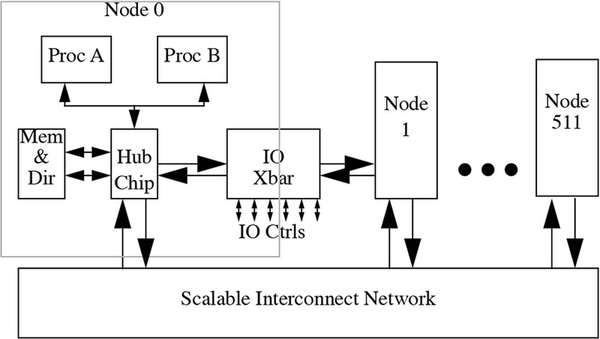
Originの構造。1ノードは2つのプロセッサーとハブノードからなる。I/O Xbar(クロスバー)は、複数のノードにまたがる形で設置される。資料は“The SGI Origin: A ccNUMA Highly Scalable Server”という論文から抜粋
上図からわかるとおり、メモリーシステムそのものは各ノードごとに配されており、システムもUMA(Unified Memory Address)ではなく、NUMA(Non-Unified Memory Address)方式である。
ただし各プロセッサーのキャッシュはシステム全体でキャッシュコヒーレンシーを保つということで、分類としてはccNUMA(Cache-Coherency Non Unified Memory Address)方式となる。
R10000プロセッサーそのものは下図に示すようなMIPS64ベースの、同時4命令実行のスーパースカラー構成を持つプロセッサーである。
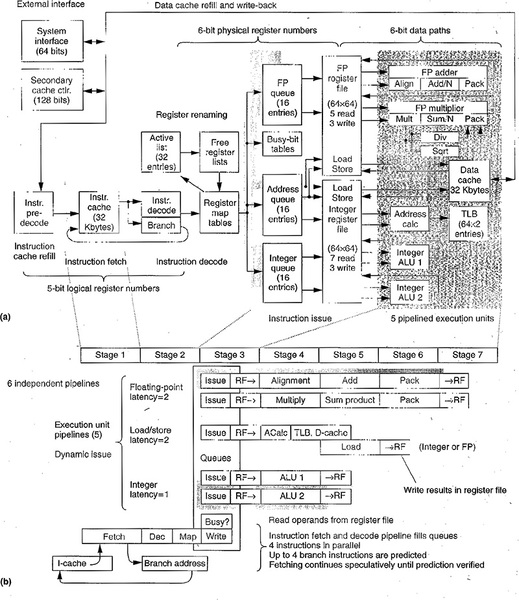
R10000プロセッサーの内部構造。IEEE Micro April 1996に掲載された“Tth MIPS R10000 Superscalar Microprocessor”という記事からの抜粋
製造プロセスは0.35μmで、ダイサイズは298mm2、トランジスター数は680万個(うち440万個は1次キャッシュ)、動作周波数は最大200MHzであった。
ちなみに製造はNECと東芝が行ない、後に0.25μmにプロセスを微細化し、250MHz稼動が可能になったバージョンも存在する。ただOriginそのものは195MHz動作とされており、0.35μmプロセスのものが利用されたと思われる。
1次キャッシュは命令/データともに32KBであり、外部には下の画像のように512KB~16MBまでの2次キャッシュを利用可能だった。OriginではCPUあたり4MBの2次キャッシュが装備されている。

Originのキャッシュ構造。クラスターバスと2次キャッシュが別々のI/Fで用意されているあたりは、Pentium IIなどと同様の構造である
CPUとキャッシュはHIMM(Horizontal In-line Memory Module)と呼ばれるカードに搭載され、これが下の画像のようなボードに装着されて1つのノードを構成した。
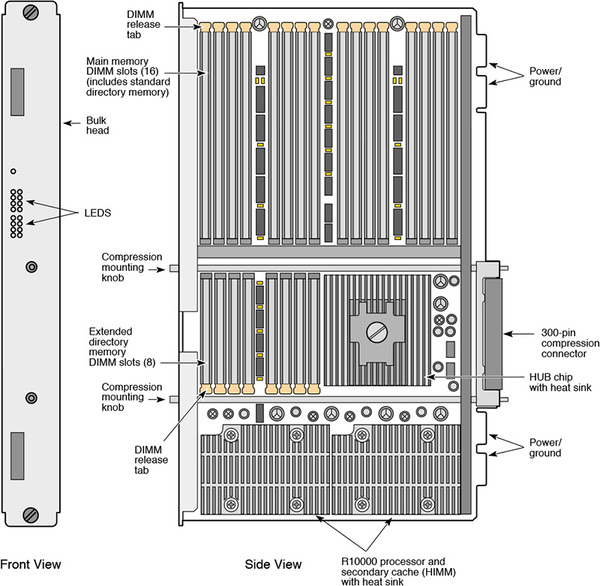
ボードそのものの大きさは16×11インチ(40.64×27.94cm)で、PCのATXマザーボードより二回りほど大きい程度
ちなみにR10000そのものは、FPU命令を1サイクルあたり2命令(ADD/MUL)実行できるので(レイテンシーは2サイクルだがリピートレートは1サイクル)、200MHz動作なら400MFLOPSとなり、512ノード/1024プロセッサーでおおむね400GFLOPSとなる。
したがって3TFLOPSならば7.5システムをクラスター接続すれば足りる計算になる。ただしそのためには、各ノードが無駄な待ちを行なわずに協調動作できる必要があり、つまりインターコネクトがどう動くかという話になる。
先の「Originの構造」を示した画像でScalable Interconnect Networkと記述されている部分だ。この中身であるが、実は一種のハイパーキューブである。
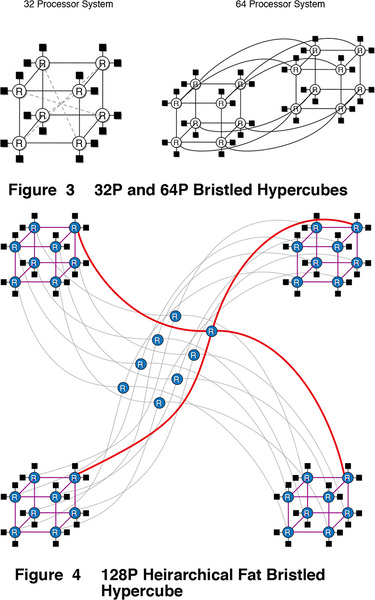
Scalable Interconnect Networkの中身は、2つのノードに1つづつルーターが配される形で、16ノード(32プロセッサー)が最小単位となる。この32プロセッサーのハイパーキューブを広域に接続する形だ。ノード数が増えるとハイパーキューブではなくFat Treeが使われる
下の画像は32~128プロセッサーのケースであるが、最大構成となる1024プロセッサーではこの128プロセッサー構成のシステム8つをさらにハイパーキューブ式につなぐ形になる。
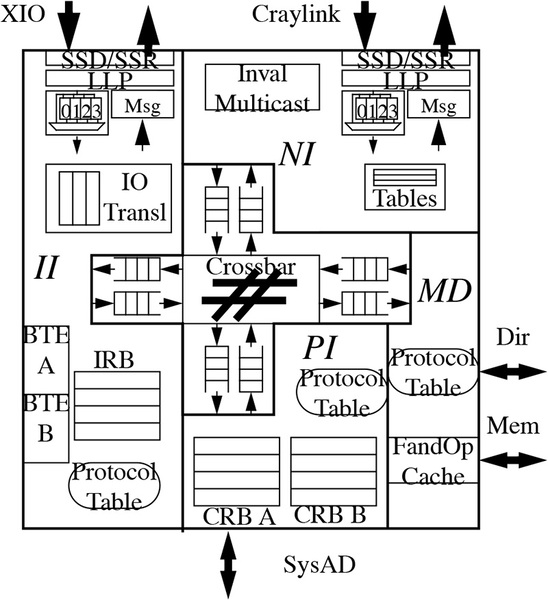
ハブそのものは中央のクロスバーで、PIがProcessor Interfece、IIがI/O Interface、NIがNetwork Interface、MDがMemory Interfaceである。総ゲート数は808KGateと発表されており、かなりの規模である
ルーターはSpiderと呼ばれるSGI独自設計のASCIチップで、各ノードに入るハブもやはり独自設計のASICが用いられる。キャッシュコヒーレンシーの確保にはスタンフォード大で開発されたDASH(Directory Architecture for Shared Memory)をベースに拡張したものが用いられた。
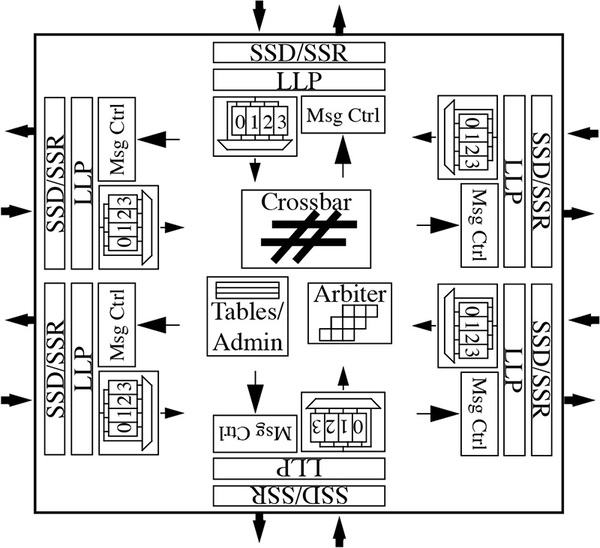
Spiderはpin-to-pinのレイテンシーが41ナノ秒とかなり高速で、物理チャネル1本あたり4本の仮想チャネルをサポート、またグローバルアービトレーション用のバッファも内蔵するという高機能なものだ
(→次ページヘ続く 「順次ボックスを追加していったBlue Mountain」)
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























