




ビッグデータ活用を進めるために、ストレージ基盤は“データの大きな湖”になるべきだ――。EMCジャパンは11月28日、記者説明会を開催し、ストレージ領域の新コンセプトである「データレイク」とは何か、どう実現していくかについて説明を行った。

EMCジャパン マーケティング本部 アイシロン担当 シニアマーケティングマネージャーの大川博史氏
ビッグデータから得られる価値を先に考えるのは「無理がある」
説明を行ったEMCジャパンの大川博史氏はまず、ビッグデータ活用に対する企業の意識調査の結果から話を切り出した。同社が今年9月に行ったオンラインアンケートでは、およそ8割の企業がビッグデータ活用に関心がある、もしくは活用中だと答えた。ただし、過半の企業は、関心を持ちつつも「具体的には検討は未着手」(全体の45%)だという。
ビッグデータ活用や検討を進めるうえで、何がネックになっているのか。回答を見ると「費用対効果が不明」「何から着手してどう進めればよいかわからない」が上位に並ぶ。「そもそもビッグデータ活用にどんな価値があるのか、そのためにどんなデータを集めればいいのかわからない、という声が多い」(大川氏)。
こうした顧客の声に対し、EMCでは“逆”からのアプローチを勧めていると、大川氏は説明する。
「『ビッグデータの活用法』や『そこから得られる価値』を先に考えようとするから無理があるのではないか。すでにさまざまなデータを持っているのだから、ひとまずはそれを一カ所に集めましょうと、そう顧客に提案している」(大川氏)
そして、これがデータレイクというコンセプトにつながると大川氏は語る。
データレイクの定義とは
「データレイク(data lake)」を最初に提唱した人物は、オープンソースBIツールを開発する米PentahoのCTO、ジェームズ・ディクソン氏のようだ。つまり、データレイクは“ビッグデータの側から考えた”理想的なデータストア/ストレージ環境である。
データレイクの定義について、大川氏は「確立された定義があるわけではない」としながらも、Web辞典での定義を引用し、おおむね次のようなコンセプトだと説明した。
――『ビッグデータ』の保管に適した(比較的)安価なコンピュータハードウェア上で構築される大規模、かつアクセスの容易なデータリポジトリ(Wiktionaryより)
「EMCの立場から付け加えると、『一つの場所に集約する』という点も重要になる。たとえるならば、ばらばらの“水たまり”や“池”ではなく、1つの大きな“湖”にさまざまなタイプのデータが集まって、しかもきちんと管理されている状態。さらにさまざまな手段でデータを読み書きできることも重要だ」(大川氏)
旧来のような、業務/アプリケーションごとにストレージが分断、サイロ化されている状態(“水たまり”“池”)では、相互のデータアクセスは容易ではない。ビッグデータとして活用し、そこから知見を得るためには大きな手間と時間がかかる。
「特にビッグデータをHadoopで処理する場合には、データを1カ所に集約してHDFS(Hadoopファイルシステム)に変換する手間が発生する。ある医療関連のIsilon顧客のケースでは、分析のためのデータ準備だけで23時間もかかっていた。これでは迅速なデータ分析ができない」(大川氏)
ストレージ管理統合の側面からメリットを訴求
ストレージベンダーとしてEMCの考える「データレイクのメリット」は、その範囲をビッグデータ活用に限定していないのがポイントだ。前述のとおり、先にビッグデータ活用のメリットや費用対効果を考えようとしても、なかなか話が先に進まない。まずはあらゆるデータを統合管理することのメリットに重点を置いて考え、段階的にビッグデータ活用の可能性を探っていくことが肝要だと、大川氏は説明する。

EMCの考えるデータレイクの要件と利点
具体的には、スケールアウト型NASのIsilonを中心に据え、NFSやSMB、HTTP/REST、そしてHDFSなどさまざまな形(プロトコル)で直接読み書きできる環境を提供する。これにより、エンタープライズクラスの高い拡張性や管理性、セキュリティも備えたデータレイクが実現する。
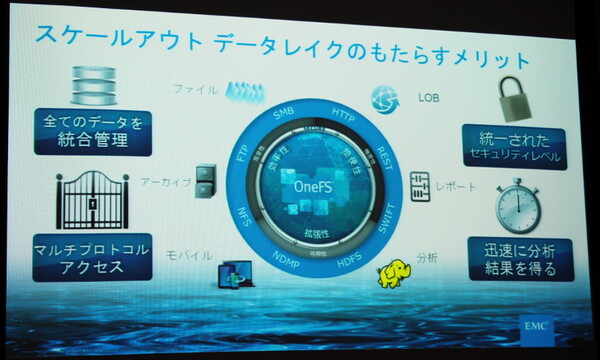
Isilonによる“スケールアウトデータレイク”のメリット
「Isilonは、単一のファイルシステムで最大2万TB(20PB)まで拡張できる。ここにさまざまなデータを放り込めば、(HDFSを介して)直接Hadoopで分析にかけられるようになる点がポイント。先ほどの医療関連の顧客の例だと、データの用意に費やしていた23時間が丸々不要になる。分析結果を得るまでの時間が大幅に短縮される」(大川氏)
大川氏は、IsilonストレージがHDFSを直接理解する(HDFSに対応している)こと、Hadoopのネームノードやデータノードを内蔵する形になるためHadoopクラスタのサーバー台数を削減できること、データノード間のデータコピーも不要になること、Isilonの備えるデータ保護機能も適用できることなどのメリットを挙げた。
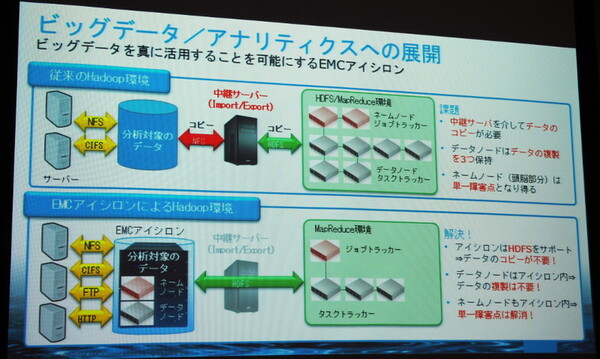
HDFSネイティブ対応のIsilonをHadoopクラスタと統合することで、ネームノードやデータノードのサーバーが不要になり、Hadoopクラスタの堅牢性も高まる
「(ストレージ市場では)先にサイロ化したストレージを統合し、1つにすることで管理コストを削減しましょう、という流れがあった。そこにビッグデータという追い風が吹いている。『せっかくデータが溜まってきたのであれば、何か(分析や活用が)できるかも』と」(大川氏)
(→次ページ、ビッグデータ分析導入の第1ステップとしてデータレイク構築を )




