




プロセッサーの性能が大きく進化
さて、話をプロセッサーに戻そう。浮動小数点演算性能で言えば、各々のプロセッサーノードは128MFLOPSの性能と512MB/秒のメモリー帯域を持つとされた。
32bitの浮動小数点では128MFLOPS=512MB/秒になるため、ちょうど一致する数字だ。もっとも実際には元の数字×2の読み込み+演算結果の書き込みになるので、512MB/秒では足りない。
しかし、一般的にDRAMの書き込みは遅く、2倍くらいの帯域を用意しないと帳尻が合わないのだが、あわせて4倍の帯域を確保するのは無理があったのだろう。
CM-5の最小構成ではこれが32個だから、4GFLOPSと16GB/秒の帯域という計算になる。これは1991年当時の性能としては、それほど高いものではない。ただCM-5の場合は、理論上これを最大16384nodeまで拡張することが可能だった。
もっともこれはキャビネット間のインターコネクトが理論上対応できる数字という意味でもあり、実機はもっとnode数が少ない。
それぞれのキャビネットは(正確な資料が見つからなかったのだが)最大256nodeまで搭載できたようで、さらに複数のキャビネットを上から見ると稲妻状で、段違いに接続することで最大1024nodeまでが用意されていた。この1024nodeの場合、ベンチマークで700GFLOPSを超える性能を発揮できるとしていた。
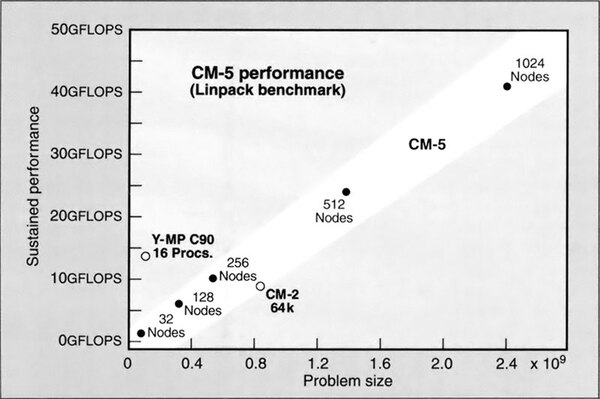
1024nodeの場合、ベンチマークで700GFLOPSを超える。“THE CM-5 Connection machine:A scalable supercomputer”より抜粋
この後継として比較的すぐ登場したのがCM-5E、ないしCM-5 Scale 5である。名称の由来がはっきりしないのだが、大きな違いはプロセッサーをSPARCからSuperSPARC(SuperSPARC I)に切り替えたことだ。
プロセッサーのアーキテクチャーはSPARC V7からSPARC V8になり、動作周波数が向上したほか、ハードウェアの乗除算命令が追加、さらには2次キャッシュもサポートされるなど大分整数演算性能が改善されている。ただ浮動小数点演算周りは特に変更がなかったようである。
ちなみに同社のカタログによれば、512node構成のCM-5 Scale 5の場合、ピーク演算性能は83GFLOPS/83Gops(Giga Operation Per Second)とされている。
このCM-5の出だしは順調とは言いがたかった。1994年6月にオランダで開催されたInternational Conference on Massively Parallel Processing Applications and Developmentという学会で発表された“A data parallel implementation of the TRFD program from the Perfect benchmarks”という論文ではいくつかのシステムでTRDF(Time-Resolved Fluorescence Depletion)を実行した結果が示されている。
| TRDFを実行した結果 | ||
|---|---|---|
| システム | プロセッサー数 | 最適化性能(MFLOPS) |
| Cray 2S/4128 | 4 | 52.2 |
| Cray X-MP/416 | 4 | 206.2 |
| Cray Y-MP/832 | 8 | 496.4 |
| CM-5 | 256 | 14.0±0.5 |
| CM-200 | 1024 | 61.0±0.7 |
この時はCM-5はまだβ版のソフトを使っており、またCM-5そのものが占有ではなくTime Shared(他のユーザーと時分割で共用していた)という話なのでそのままの実力とはいえないが、それにしてもやや数字が低い。
あるいは2004年のSystemics, Cybernetics and Informaticsに掲載された“Micro-mechanical Simulations of Soils using Massively Parallel Supercomputers”(関連リンク)という論文では、CM-5を使ってnode数を増やしたときどれだけ性能が改善されるかを比較した数字が出ている。
| node数を増やした際の性能 | ||
|---|---|---|
| node | 403spheres | 1672spheres |
| 1 | 1.0倍 | 1.0倍 |
| 32 | 1.6倍 | N/A |
| 64 | 2.8倍 | N/A |
| 128 | 4.4倍 | N/A |
| 256 | 6.5倍 | 5.0倍 |
| 512 | 7.9倍 | 8.7倍 |
といったところで、512nodeの性能は1node(厳密に言えばコントロールプロセッサーだけで実行)と比較して、たかだか8倍にしかならないとされている。
もちろんこうした超並列のマシンでは、どれだけ問題の並列度を上げられるかで性能の上がり方が大きく変わるため、この数字だけでどうこうということは言いがたい。
実際、1993年の6月には、59.7GFLOPSという数字を出してトップ500のナンバーワンに躍り出ている(関連リンク)ため、うまく解くべき問題の並列度を上げるかが性能を引き出す解になる。
1994年に同社が作ったコマーシャルビデオがYouTubeに上がっているが、多くの大学教授や研究者が、非常に大規模なシミュレーションなどにCM-5が最適であることを説明しており、こうしたマーケットに活路を見出すつもりだったことがわかる。
→次のページヘ続く (CM-5の売り込みより食堂のレシピ本作りに注力?)
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



























