




世界最速の演算を実現した
並列処理の仕組み
CRAY-1のプロセッサーそのものは64bit構成(アドレスは24bit)となっており、当初の動作周波数は80MHzであった。
レジスターの幅も演算器の幅も64bitなので、1つのベクトルユニットあたりの性能は最大で80MFLOPSという計算になるが、実際には2つのユニットが連動して動くことで、160MFLOPSの性能が実現できた。
これはどういうことかというと、たとえばY=A×X+B (XとYがベクトル型計算機)という演算をする場合、普通にやると以下の手順になる。
- Xレジスターに元データを入れる
- Y'=A×Xをベクトル演算(Y'もベクトル型計算機)
- Y =Y'+Bをベクトル演算
つまり、まず乗算の演算をいったん終わらせ、ついで加算を行なう必要があった。ところがCRAY-1ではChainingという技法をサポートしており以下の処理ができる。
- Xレジスターに元データを入れる
- A×Xをベクトル演算し、その結果をそのまま加算にまわしてY=A×X+Bを計算する
ややわかりにくいかもしれないので、時系列にしてみたのが図1だ。縦方向が時系列で、たとえば0サイクル目にVector X(0)の値をロードしてA×Vector X(0)の計算を行なう。
この結果は1サイクル目に中間レジスターのVector Y'(0)に書き出され、その一方でVector X(1)から次の値を読み出して計算が始まる、という具合だ。
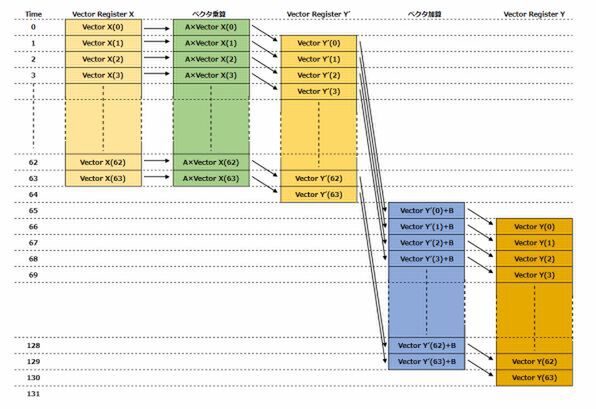
図1 通常の処理で、Y=A×X+Bという演算を行なうときの過程
このケースでは、まず乗算を64回連続して行なってから、次に加算を64回回すわけで、トータルとして131サイクル目にやっと全部の結果がVector Yに書き込まれることになる。
では、Chainingを利用するとどうなるかというのが図2である。0サイクル目は図1と同じであるが、異なるのは1サイクル目からである。
1つ目の乗算の結果が、すぐ加算器に渡されて、ここで加算が乗算と平行して行なわれるため、2サイクル目には最初の乗加算の結果が格納される。
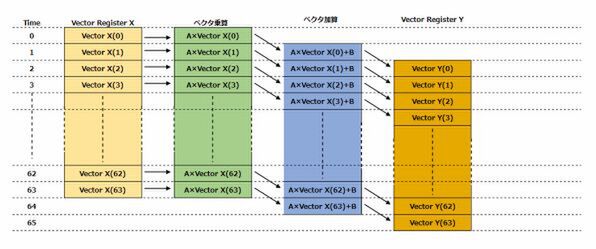
図2 Chainingを利用する場合の過程
最終的には65サイクル目にすべての演算が終わることになり、図1と比較して半分の所要時間で済むことになる。
このChainingそのもののアイディアは、IBM 360/195の“data forwarding”など先例があるが、当時の論文によれば「360/195はスカラーのみだがCRAY-1はベクトルでこれが行なえる。また360/195では、data forwardingはプログラムコード内で明示的に指定するか、もしくは“name tags”を指定する必要があるが、CRAY-1はこれを自動で行なう」と、その違いを説明している。
もちろん、この性能を生かすためにさまざまな工夫が凝らされた。単にベクトルユニットやスカラー、アドレスユニットなど合計で12の実行ユニット(CRAY-1ではFunctional Unitsと呼んでいる)が搭載され、これが並行して動作する。
レジスターは64Word(1Word=64bit)のベクトル(V)レジスター×8以外に、24bitのアドレス(A)レジスター×8、24bitのアドレスセーブ(B)レジスター×64、64bitのスカラー(S)レジスター×8、64bitのスカラーセーブ(T)レジスター×64と、この当時としては信じられないくらい大量のレジスターが搭載されていた。ちなみにいずれのレジスターも6ナノ秒という高速アクセスが可能としている。
→次のページヘ続く (CRAY-1の内部構造と後継機)
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























