




配線層も微細化し、実装密度を向上
14nmでは、トランジスタ層の上に位置する配線層に関しても微細化を進めたとしている。これは高密度にトランジスタを実装する場合、必然的に配線も細かくしなければいけないわけで、当然の対策である。
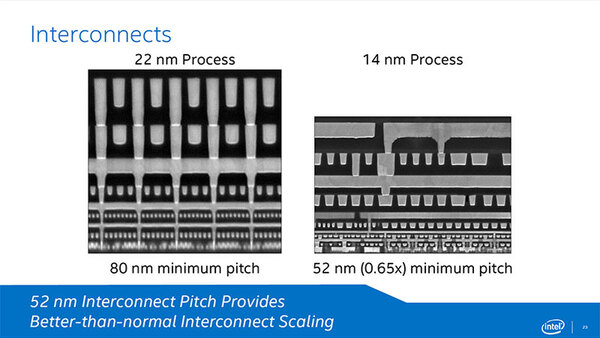
トランジスタ層の上にある配線層も微細化。写真で見る限り、M1~M4あたりが80nmや42nmで、その上はもっと広く太い配線になる
おもしろいと思うのは高さ方向も密度が詰まっていることだ。80nmや52nmというピッチは、写真では水平方向の密度である。高さ方向は微細化には直接関係してこないのだが、14nmプロセスではかなり密度を詰めることに成功した。
ちなみに高さ方向に関しては、可能ならば薄く抑えたほうが総配線長が減るわけで、これはレイテンシーの削減と消費電力の削減の両方に効く。ただその一方で配線の形成などはある程度の高さがあったほうが作りやすいし、また配線間の絶縁や電磁干渉などを避けるには、厚めに作る方が効果的である。
実際はこのあたりを勘案しながら高さを決めるわけで、これには配線層の絶縁物となるLow-K材料になにを使うかも関係してくる。おそらく14nm世代で高さ方向が大幅に圧縮されたということは、Low-K材料に何らかの改善があったのではないかと思われる。
結果としてSRAMがどう構成されたか、というのが下の画像である。SRAMそのものはレジスターやキャッシュ、TLB(Translation Lookaside Buffer)などに幅広く使われており、CPUの構造上欠かせないコンポーネントである。SRAMの面積が直接CPUの面積に比例するわけではないにせよ、CPUの小型化の指標になりえるものだ。
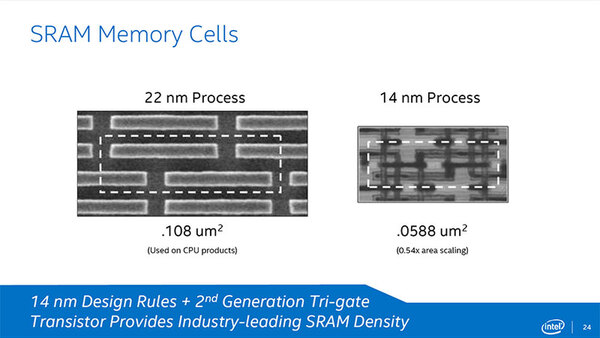
SRAMの構成。「実際のCPUに使われている」とするが、どこに使われているものかは不明
細かい話をすると、CPU内部のレジスターおよび1次キャッシュ/1次TLBに関しては速度優先(なにしろCPU全体と同じ動作周波数で駆動するし、レイテンシーも最小限である)な一方、容量そのものはそう大きくないため相対的に面積削減への要求は高くないし、消費電力削減も「あくまで性能を満たした上で」可能ならばという程度である。
対して3次キャッシュになると、なにしろ大容量なのでまず面積削減と消費電力削減に対する要求が非常に厳しい反面、性能面ではレジスター/1次キャッシュほど高い要求はない。
1次キャッシュは1~2サイクルでアクセスできるのに対し、2キャッシュでは4~8サイクル、3次キャッシュでは10サイクル以上必要になるのは、性能よりも面積や消費電力への要求の方が高いからである。
ということで、このSRAMセルの構成はどこに向けたものかは、いまひとつハッキリしないが、ほぼ同じ構成を14nmプロセスで実現すると、面積をほぼ半減できたとしている。
インテルがTSMC、あるいはSamsung/GLOBALFOUNDRIESの16/14nm FinFETプロセスと比較して有利な点として示していることの1つが実装密度の向上である。どちらのプロセスも配線層は20nmと同じでトランジスタのみ改良するため、実装密度は20nmの時と差がない。
したがって、これらのファウンダリーの16/14nmプロセスと比較した場合、インテルの14nmプロセスは同じダイサイズならより多くのロジックを実装でき、同じロジックサイズならダイサイズをより小さくできる。それもあってか、後に出てくるプレゼンテーションではこの優位性を誇示したものが目立つ。
→次のページヘ続く (22nmプロセスと比べ、2倍もの性能/消費電力比を実現)
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



























