




22nmプロセスと比べ、2倍もの性能/消費電力比を実現
ここからはその14nmプロセスを使った製品の話である。下の画像は、リーク電流とスイッチング速度を比較したものである。
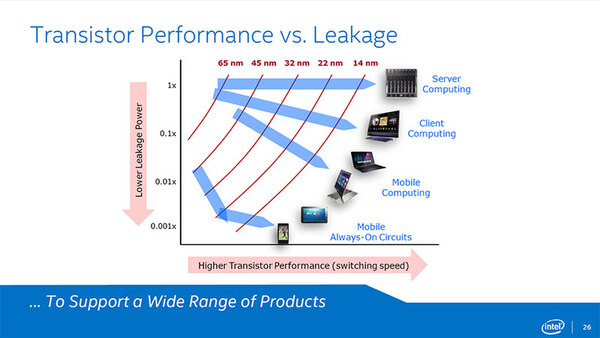
リーク電流とスイッチング速度を比較したもの。一番下、つまりスマートフォン向けでは、リーク電流は22→14nmでそれほど減らないという風にも読めるし、スマホにも性能が必要ということで多少スイッチング速度に振ったという風にも読める
まだインテルは具体的な内容を公開していないが、当初製造されるBroadwell-Yは、この図で言えばMobile Computingに属する部分で、しかもSoC構成ということで、ターゲットはMobile Computing~Mobile Always-On Circuitsを狙った部分となる。これがP1272ということになる。
Server Computing~Client Computingで一部Mobile Computing向けがP1273という形になると思われる。実際の製品では、ということでServer/Laptop/Mobileの3つのスキューにおける変化をまとめたのが下の画像である。
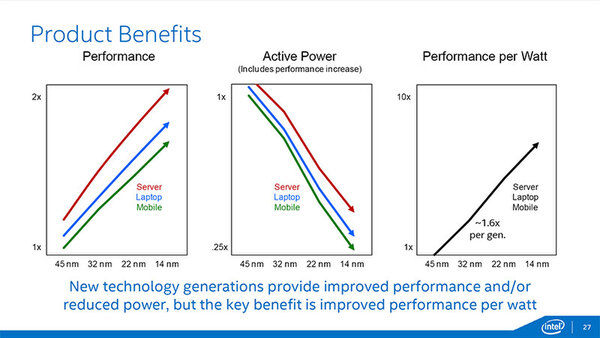
Server/Laptop/Mobileにおける変化。一貫して向上しているのは性能/消費電力比で、これが平均世代毎に1.6倍の改善を実現しているという
性能にしても消費電力にしても、22nmから14nmになって劇的に改善されているわけではないにせよ、着実に性能改善/消費電力低減が図られているとしている。そして、今回発表されたBroadwell-Yは、この1.6倍を超える2倍もの性能/消費電力比を実現したとしている。
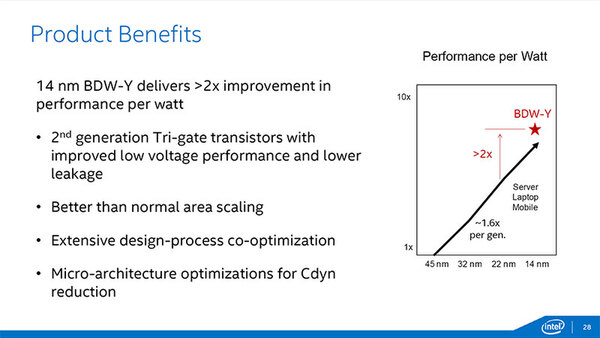
Broadwell-Yは2倍もの性能/消費電力比を実現。図はあくまでプロセスそのものの改善によるもので、これに加えてマイクロアーキテクチャーの変更などによってトータルで2倍の改善が成し遂げられたというものだ
次が、先ほども出てきた実装面積の話。ゲート幅×配線層の幅を掛け合わせた数字で言うと、インテルのプロセスは一貫して削減できているとしている。大雑把には、プロセスが一世代進むと密度が倍になるとされるが、これを14nmでも実現できたとする。競合するTSMCやSamsung/GLOBALFOUNDRIESに比べて実装密度が高いことをアピールしている。
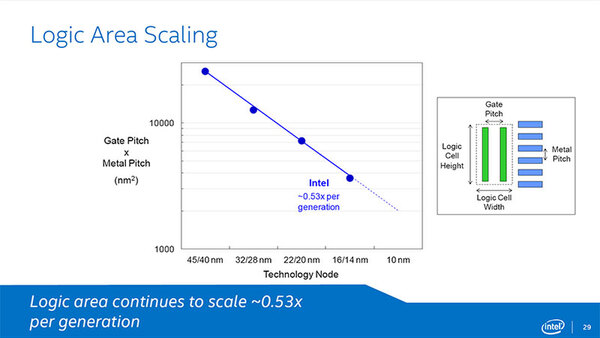
インテルのプロセスは一貫して実装面積を削減できているとしている。縦軸は対数なので、22nm世代がおおむね7000平方nm、14nmが3700平方nm程度と思われる
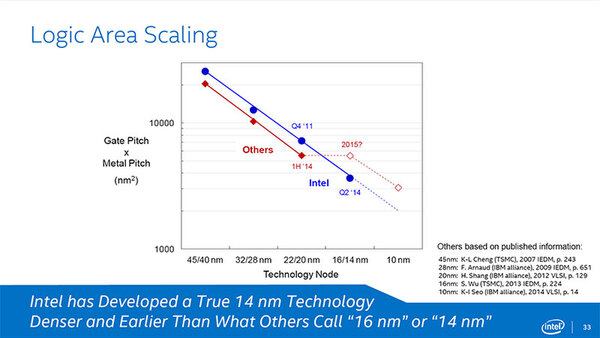
22nm世代まではむしろTSMCやSamsung/GLOBALFOUNDRIESの方が配線密度が高い。14nm世代で比較した場合、インテルが3700平方nm、その他が5500平方nm程度で、確かにインテルの方が有利ではあるが、実はそう大きな差ではない
実装面積の削減により、実装コストが引き続き順調に下がっているというのがインテルの主張である。正確には、1mm2あたりのプロセスコストそのものは順調に引きあがっている。ところが、これを遥かに上回る勢いで1mm2あたりに実装できるトランジスタ数が増えているため、トランジスタ1個あたりのコストは順調に下がる、というわけだ。
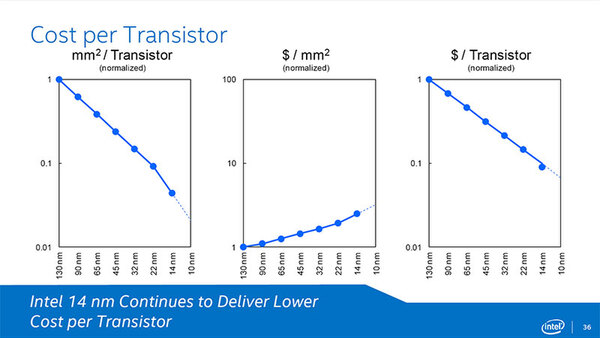
実装コストが下がっているというインテルの主張。正規化した数字で言えば、14nmのウェハー製造コストは、130nm世代のほぼ3倍あたりであろう
最後に、これを利用したBroadwell-Yの歩留まりに関してのまとめが出ている。やはりというべきか、立ち上がりは22nmに比べてかなり低かったようで、歩留まりを引き上げるために2~3四半期ほど努力してきたのがよくわかる。
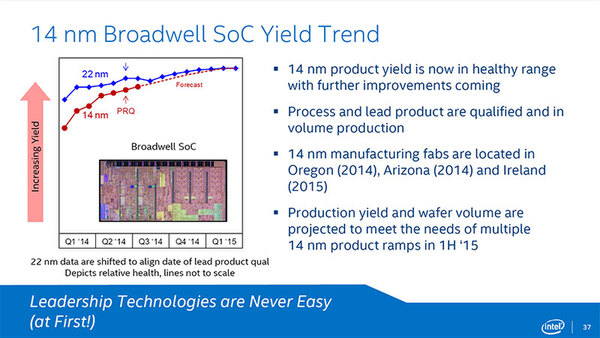
Broadwell-Yの歩留まり。興味があるのは、“Multiple 14nm product”に、AlteraのFPGAが含まれるかどうかだ。なんとなくインテル製品のみの話で、その他の製品は後送りになっていそうな気がする
インテルの予定としては、今後は22nm世代と同等の歩留まりが確保でき、2015年前半には大量の14nmプロセス製品が出荷できるとしている。現在はオレゴンのD1C/D1D、それとアリゾナのFab 32が14nmを量産しており、2015年にはアイルランドのFab 24も量産を開始するというのが現状の予定だ。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























