




MullinsとTemashは明らかに別のダイ
細かな省電力機構追加で性能アップ
ではどうして性能向上が可能になったのだろうか。下の画像がMullinsとTemashのフロアプランをそれぞれ示した資料である。
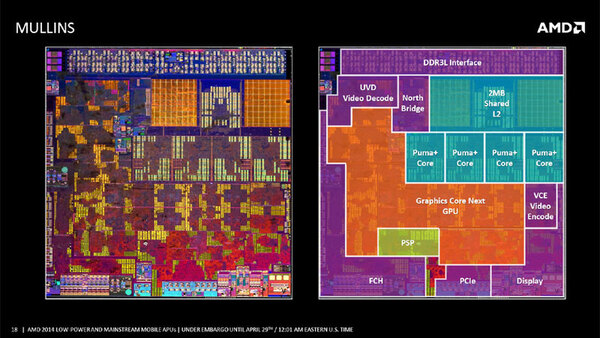
Mullinsのフロアプラン。これは2014年4月に発表されたもの。一応Mullinsとしているが、構成的にはBeemaも同じである
Temashのフロアプラン。これは2013年3月のKabini/Temash発表時のスライドだ
さらにこのフロアプランを並べてみたのが下の画像である。ダイサイズそのものが不明確でわからないので、とりあえず上の画像からそれぞれのフロアプランを並べた上で、同じ高さになるようにリサイズしたものだ。
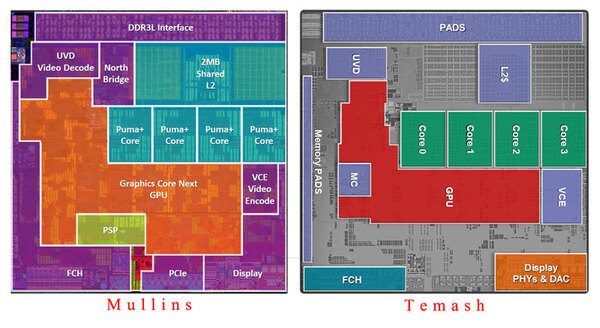
MullinsとTemashのフロアプランを並べた画像。Temashは上の画像を90度回転させている
この状態で比較するとまず横幅そのものがMullinsの方が3%ほど小さくなっている。CPUとL2キャッシュの配置はおおむね同じだが、強いて言えばMullinsの方がややCPUコアのサイズが小さくなっている。
厄介なのはGPUで、明らかにTemashはGPUとして囲われた領域が本来より小さい気がするのだが、それを加味すると面積そのものは同等といったところ。ただPSPが加わっている分、Mullinsの方がやや面積が小さいように感じられる。インターフェース周りのPadなどはだいたい同等で、Display PHY&DACやVCEなどもほぼ同等なようだ。
このように、ダイそのもののレイアウトはかなり似ているが、MullinsとTemashは明らかに別のダイである。ここからは筆者の推測である。Kaberi/TemashとBeema/Mullinsは、どちらも28nmプロセスで製造とされているが、確かにどちらも28nmプロセスで製造されているとはいえ、プロセスそのものが異なっていると考えられる。
AMDはファウンダリーをいまだに明示していないが、おそらくKaberi/TemashはTSMCのHPM(High Performance Mobile)で製造していると思われる。理由はGPUやVCE/ディスプレー関連の部分で、ここをやはりTSMCの28nm HPMで製造しているGPUからそのまま持ってきたと考えられるためだ。
これに対し、Beema/Mullinsは同じ28nmでもHPLに切り替えたのではないかと思われる。同じ省電力でも、28nm LPではさすがに2GHzオーバーはかなり厳しいが、28nm LPHならば可能な範囲だ。
TSMCによれば“The 28HPL process reduces both standby and operation power by more than 40%.”(28HPLプロセスは待機電力と動作電力のどちらも40%以上削減可能)だそうで、「なにと比較して」が抜け落ちているあたりが残念ではあるが、もしKabini/Temashから大きく構成を変えずに消費電力を落とそうとしたら、プロセスを省電力のものに切り替えるしかないし、事実そうしたのだと思う。ただしそのままだと当然動作周波数が下がる。これを補うためには内部構造に手を入れなければいけない。
やや話が飛ぶが、連載237回の「ロジック回路と同期/非同期」のところで、FO4(Fan Out 4)の説明をした。このなかでQualcommのKraitはFO4が20~25をターゲットにしていると解説したが、これをベースとしたKrait 300というコアは「Snapdragon 600」に搭載されている。
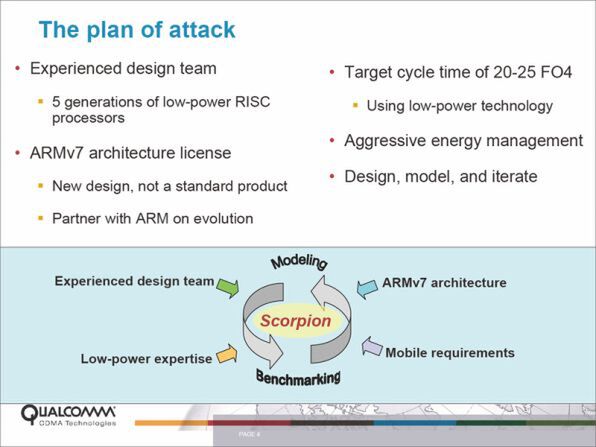
2007年のARM Developer ConferenceにおいてQualcommの発表した資料より。FO4のターゲットが20~25と示されているのがわかる
このSnapdragon 600はTSMCの28nm LPで製造されながら、動作周波数は1.9GHzに達している。もしPuma+コアが、やはりFO4を20前後になるように再設計したとすれば、28nm HPLを使えば十分2GHzは狙える数字である。繰り返しになるがこれは筆者の推定である。
動作周波数を上げながら消費電力を落とし、しかもプロセスノードを変えてないとすれば、これ以外に合理的な解が見つからない。実際、そうなると物理設計は全部やり直しになる。すると半年は簡単にかかるので、Kabini/Temashから1年後にBeema/Mullinsが出てくるのはスケジュール的にも辻褄が合う。
もっとも省電力は単にプロセスだけではなく、細かな省電力機構の積み重ねも貢献している。細かな省電力機構が追加されたことで、ついにBeema/Mullinsでは0.5Wのオーダーまで消費電力の削減が可能になった。
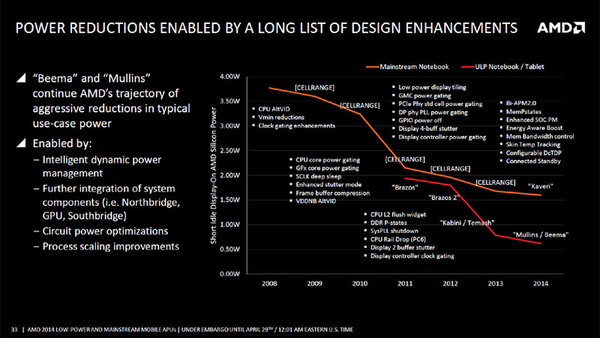
縦軸は待機状態におけるSoCの消費電力を示したもの
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

























