




回路の微細化が進むと
光の波長を短くする必要がある
さて、基本を簡単に説明したところで、今度は問題点について解説しよう。現在の露光の最大の問題は、「回路を微細化しすぎて、光の波長より短い寸法での製造が必要になっている」ことである。もともと光源として使われてきたのは高圧水銀ランプのg線と呼ばれるものだった。
高圧水銀ランプは、例えばウシオ電機の製品のスペクトル図をみると、436nmほどのところにまず大きなピークがあるのがわかる。これを利用することで、500nmあたりまでのプロセスの露光は問題なく実現できた。
もう少し微細化を進めると、これでは都合が悪いということで、次に同じ高圧水銀ランプのi線(357nm)を使って露光することにした。350nmプロセス、頑張ると280nmプロセスまではこれで実現できている。
ただこれより微細化しようとすると、そろそろ高圧水銀ランプでは無理があるということで、KrF(フッ化クリプトン)のエキシマレーザーと呼ばれるものを利用するようになった。このKrFエキシマレーザーは比較的広く利用されているもので、安定して十分な出力が得られる。波長も248nmと高圧水銀ランプより短い波長が得られるということで、高圧水銀ランプからKrFエキシマレーザーへの移行はスムーズだった。
このKrFエキシマレーザーは248nmほどの波長で、180nmプロセスあたりまで利用可能だ。頑張れば150nmプロセスも利用できたが、それより微細化するのはやや辛かった。そこで新しい光源としてArF(フッ化アルゴン)エキシマレーザーが利用されるようになる。こちらは波長が193nmとやや短く、130nmや110nmまでは問題なく利用できた。
さて、ここで線幅と波長の関係である。最初は光の波長よりも線幅が広い必要があったのに、なぜ途中から光の波長より短い線幅が可能になったかといえば、もちろん技術が進化したからであるが、これは物理のお勉強になる。一般論としてステッパーの解像度は、以下の公式で計算される。
解像度=K(プロセス係数)×λ(光源の波長)÷NA(レンズの開口数)
レンズの開口数というのは、要するにレンズの明るさのことである。Kは一定の値なので、λ以下の解像度を実現したければ、NAを改善すればいい。このレンズを改善することで、より微細化したプロセスでの製造が可能になったというわけだ。
もっとも、だからといって無限にレンズを改善できるわけではない。さすがに2000年頃には、そろそろ限界が見えてきつつあった。この時点で一番有力視されていたのはF2(フッ素)エキシマレーザーで、これは波長が157nmとさらに短いので、非常に有望視されていた。
1999年頃、インテルもF2エキシマレーザーの採用を一度表明したことがある。ところが、これを使ってもせいぜいプロセスを1~2世代先に進める程度の効果しかなく、おまけにF2エキシマレーザーの開発にずいぶん手間取った。
その間に登場したのが液浸(Liquid Immersion)という技術である。先ほどのASLMの動画で、もうすこしウェハーのそばに寄ったのが下の動画である。
ウェハーの上に液体の層が設けられ、これを通して露光が行われているのがわかるだろう。構図としては下図のような形だ。ちなみに下図ではレンズとウエハーの距離が大きいが、実際にはレンズとウェハーがもっと接近している。
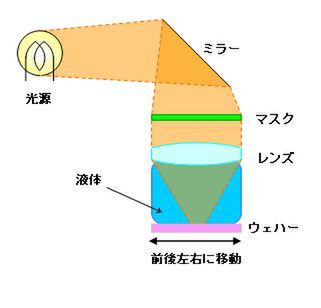
液浸の仕組み。ウェハーの上に液体の層が設けられ、これを通して露光が行われる
そもそもNAは、空気中ではいくら頑張っても1.0以上にはならない。ところが液体の中だと屈折率が上がる関係で、NAの値が1.0以上になる。この理屈を使うことで、光源はArFのまま90nmプロセス向けの露光に成功する。例えばニコンは量産対応ArF液浸ステッパーの開発に関するプレスリリース(関連リンク)を2004年に出しているし、TSMCは2004年12月に液浸を利用しての90nmプロセスを利用したチップの製造に成功している。
光の波長だけでなく
マスクの微細化も必要
さて、この次はマスク側の改善である。高校あたりの物理の授業で、スリットを使った光の干渉の実験をやったことを覚えておられるかもしれない。こうした光の干渉を使い、より微細化を進めるという技法が色々採用された。
例えばここまでの話では、マスクは光を通す(透過)か通さない(不透過)かのどちらかしかない。これをバイナリーマスクなどと呼ぶが、これ以外に若干光を通す部分を設け、ここを通過した光と透過部を通過した光の間で干渉を起こさせることで微細化を実現するハーフトーンマスクといった技法、あるいは光の位相を一部シフトさせ、これとシフトしていない光を干渉させることで微細なパターンを作り出すフェーズシフターなどがこれにあたる。
また、微細化を進めると露光後のパターンが甘くなるという傾向がある。そこで、甘くなることを前提に、角に突起を余分に付ける補正を行なうことで露光後のパターンを望みのものにしようというOPC(Optical Proximity Correction:光近接効果補正)も開発され、これによりさらなる微細化が可能になった。
ただこうした方法を使っても、やはり限界があることに変わりはない。そこで考え出されたのがダブルパターニングやトリプルパターニングである。これについてはこれまでも何度か触れているので詳細は割愛するが、もう配線をマスク一発で製造するのが不可能なので、複数枚のマスクに分割して製造する、あるいはまずテンプレートと呼ばれる最終的なマスクに当たるものを露光→エッチングで製造し、次にこれを使って改めて露光→エッチングするなど、さまざまな技法が開発されている。
現状の最先端プロセスは、液浸にこのダブル(場合によっては3回繰り返すトリプル)パターニング、それにさまざまなマスクの補正機能のあわせ技でなんとか凌いでいるのが現状である。実のところ、このあわせ技で14nmの製造はすでに可能になっており、次の10nm世代もほぼ実現できるめどは立っている(ただしトリプルパターニングで済むかどうかは微妙なところだ)。
さて、こうしたArF+マルチパターニングの最大の問題はコストである。本来なら露光→エッチング1回で済むものを、何度も露光→エッチングを繰り返す必要があるし、その分マスクも増えるわけで、それはコストが上がるのも無理ないところ。
TSMCなどのファウンダリーでは、40nm世代だとウェハー1枚のコスト(ウェハ代+加工コスト)がおおむね30万円台で済むのが、28nm世代だと60~70万円まで跳ね上がるのは、単に製造装置の高騰により減価償却分が多めにのせられている以外に、このマルチパターニングに要する手間がバカにならないことも大きい。これが20nmとか16nmになると、さらにコストが跳ね上がると予測されている。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")





























