




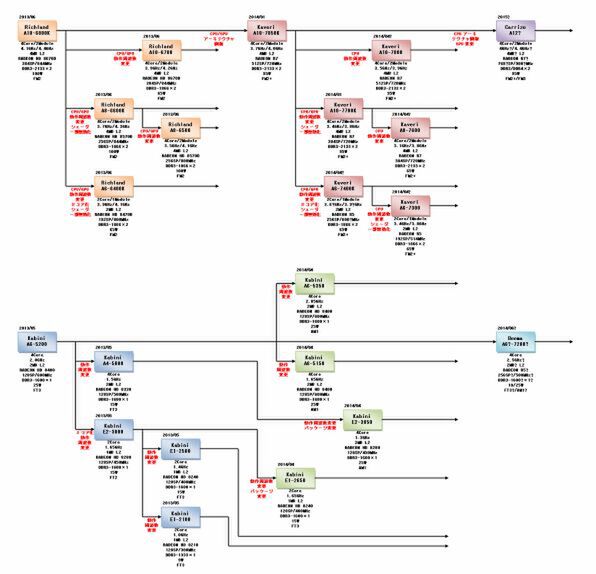
2013~2015年のAMD APUのロードマップ
CarrizoはKaveriと比べて
50%程度の性能/消費電力比改善になる?
次はKaveriの後継製品であるCarrizoの話だ。基本的な構成そのものは現在のKaveriと大きく変わらない。CPUコアはExcavatorに切り替わるが、4コア/2モジュール構成は変化がない。GPUコアが既存のGCNベースなのも同じであり、プロセスも引き続きGlobalFoundriesの28nm SHPを利用するものと思われる。
ここで、先ほど触れた28nm SHPの話をしよう。元々GlobalFoundriesは28nm SHPは計画になかった。ところがTSMCが28nm HPのさらなる開発を中断してしまい、28nm HPMに注力する方針を決めたことで、AMDは困った立場に追い込まれる。というのは28nm HPMでは最高でも2.5GHz程度までの動作周波数に向けたもので、4GHz超えのAPUでは使えないからだ。
これもあって、当初はなかったはずの28nm高速ロジックプロセスの開発をGlobalFoundriesに要請、これを受けてできたのが28nm SHPである。Kaveriが遅れに遅れたのは、単に物理設計のみならずプロセスの開発も一緒に行なっていたから、という側面があったわけだ。
幸いなことに、この28nm SHPは予想外に歩留まりが良く、順調に生産が行なわれている。このことそのものは喜ぶべき話なのであるが、この結果として「やや動作が遅いのでハイエンド向けには利用できないために、下位グレードに廻す」という製品が当初予定より少ないらしい。
またGlobalFoundriesで28nm SHPを使っているのは現在のところAMDだけであり、製造できるウェハー枚数はそれほど多くない。上位モデルを優先して出荷した結果として下位モデルは後回しになってしまった形だ。
4~5月と言われているのは、この頃には上位モデルの需要が一段落して、製造したダイを下位モデルに回すゆとりができるだろう、という話の模様だ。
そこで話をCarrizoに戻そう。GlobalFoundriesもTSMCも、20nm世代はモバイル向けのプロセスしか製造する予定がない。もともとGlobalFoundriesは20nm世代を半ばスキップする覚悟で14nm FinFETプロセス(14XM)に全力を注いでいる状態だから、20nm SHPプロセスを開発するような余地はない。TSMCはもうそうしたプロセスを製造するつもりが初めからない。
結果として、Carrizoは引き続きGlobalFoundriesの28nm SHPプロセスを使う以外の選択肢が事実上存在しない。というのはTSMCの16nm FinFETやGlobalFoundriesの14nm XMを選択した場合、量産出荷できるのが最悪2015年後半になるかもしれないためだ。2014年末~2015年頭までには次の製品を出荷するためには、14/16nmプロセスを使うのはリスクが高すぎるわけだ。
そのCarrizoであるが、こちらはパッケージがFM2+とFM3+の両対応になり、DDR3とDDR4のどちらも利用できるようになる模様だ。肝心のスペックや性能は現状一切不明である。したがって以下は筆者の推測である。
まずCPUコアは若干の動作周波数アップと若干の性能改善。一方GPUコアの方はシェーダー数の増強などにより、トータルでKaveriと比べて50%程度の性能/消費電力比改善を狙うあたりに落ち着くのではないかと思われる。もちろんこれを行なうとダイサイズは間違いなく肥大化することになる。
現在のKaveriのダイサイズが245mm2とされており、その6割ほどをGPUが占めているが、もしGPUのシェーダー数が1.5倍になると、他がなにも変わらなくても320mm2ほどに肥大化する計算である。

Kaveriのダイサイズは245平方mm。その6割ほどをGPUが占めている。Carrizoは320平方mmほどに肥大化する可能性がある
これは結構大きな数字ではあるが、法外なほど大きいわけでもない。TSMCの28nmではあるが、Radeon HD 7970およびRadeon R9 280シリーズ、要するにTahitiコアのダイサイズは365mm2に達しており、これよりは小さい程度でしかない。
GlobalFoundriesの28nm SHPはおそらくウェハーの製造コストは現在はTSMCの28nmプロセスより若干高めであろうとは想像されるが、2015年の段階だと製造装置の償却などもある程度終わって値段が下がることが期待できるため、Kaveriと同程度か、プラスα程度の原価で製造できるようになることも考えられる。
以上のことから、まだスペックは不明だが、上手く開発が進めば2014年末までにはCarrizoベースの製品が投入されるかもしれない。
さて、見えている話としてはこれで終わりだが、最後に謎の話を1つしよう。AMDが公式に公開している“Software Optimization Guide for AMD Family 15h Processors”というマニュアルがある(関連リンク)。筆者が参照しているのは2014年1月の日付のRevision 3.08なのだが、これの197ページにこんな説明がある。
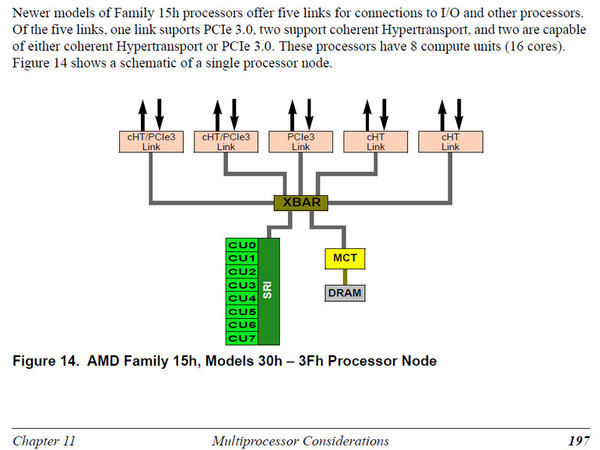
AMD Family 15h, Models 30h - 3Fh Processorというのは、Kaveriなどに使われているSteamrollerコアのこと
これを読む限り、Steamrollerをベースにした16コア/8モジュールの製品が存在するように見える。さてこれはなんだろうか?
AMD自身これについて一切コメントをしていないので不明なのだが、筆者の推察としてはこれは特定顧客向けのカスタムCPUではないかと考えている。
技術的には、こうしたものを作ることはそれほど難しくない。前述のとおり、Kaveriのダイサイズの半分以上はGPUで、CPUコアは4コア/2モジュールで大体3割ほど。ダイサイズにすれば73.5mm2程度である。16コア/2モジュールにすれば、これが4倍になるわけで294mm2ほど。DRAMコントローラやHTLinkなどを全部込みにしても350mm2程度で収まる。
大きな3次キャッシュを搭載するとまた話は別だが、そうでなければ製造そうは難しくない。また、このプロセッサーを製造するために必要な回路技術やIPは全部AMDが所有しているから、そうした問題もない。
その一方で、いまさらこの製品を出したところでマーケットが取れる可能性は非常に乏しい。まずパッケージがどう考えても既存のものとは異なる(インターフェースが違う)から、現在のOpteronのプラットフォームをそのまま使うわけにはいかない。
また、AMDはプロセッサー間接続に、既存のHyperTransportに換えてFreedom Fabricと呼ばれる高速スイッチを使う方針を定めており、これを使うためには外部にわざわざFreedom Fabricのコントローラーが必要になる。しかも、それらを解決したとしても、すでにXeonにほぼ独占されているマーケットをいまさらひっくり返せる可能性は非常に少ない。
しかし、カスタムチップとなると話は別だ。現在AMDをはじめ、多くのベンダーが、スケールアウトサーバー向けに64bit ARMベースの製品を準備しており、これに対抗してインテルがAtomベースのAvoton/Rangelyという製品を投入した。
大口顧客の中には「今すぐソフトウェアをARM向けに全面刷新するのは無理」というところは多い。長期的にはそうした方向に乗り換えるにしても、とりあえず今はx86/x64ベースのソフトウェアが動かないと困るというところがほとんどだ。
そうしたメーカーの中には、必ずしもインテルのAvoton/Rangelyでは満足できないところもあろうし、その結果としてAMDがSteamrollerベースで最大16コアの製品とかをカスタム品としてリリースするのは理屈にあっている。
この推測が事実かどうかは不明だが、インテルもすでに大口ユーザー(Google、Facebook、Amazon、Twitterなどの、自社で数十万~数百万台のサーバーを所有している企業)向けにカスタムチップを提供していることを公式に認めている。
AMDはカスタムチップビジネスを実際に行なっている(Xbox OneとPS4がその良い例だ)から、考慮すべき可能性の1つだとは思う。ただこれが事実だとすれば、おそらく普通のユーザーがこれを使う機会はないであろう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























