




プロセスノードを上回るスピードで
微細化していくゲート長

ゲート長のロードマップ(前ページ掲載の表と同じもの)
次にゲート長のロードマップ表を見てみるが、こちらは2005年を境に数字が変わっているのがわかる。これはロードマップ中の表記の問題である。下の画像は2004年、さらにその下の画像は2005年のものだが、例えば2005年を比較した場合、MPU Physical Gate Lengthはどちらも32nmとなっているのに、MPU Printed Gate Lengthは2004年が45nm相当なのに2005年は54nm相当になっている。
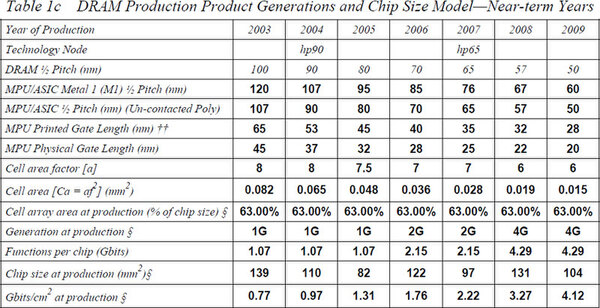
こちらはITRS 2004 Updateの“Overall Roadmap Technology Characteristics”からの抜粋
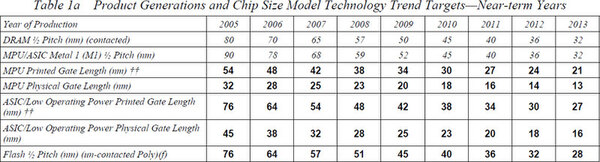
こちらはITRS 2005 Editionの“Executive Summary”からの抜粋
2005年から、ゲート長(Printed Gate Length)の表記に関するルールが変更になっており、この結果2005年を境にいきなり数字がずれている格好だが、実は2009年にもやはり同様の変更があり、数字そのものを比較してもよくわからなくなった。
ゲート長のロードマップ表ではこのあたりを勘案しながらそれぞれのゲート長がどう前倒しになっていったかを示したものだが、こちらもプロセスノード同様に前倒しが著しい。
さらには、ゲート長とプロセスノードが一致したのは350nm世代までで、その後は常にゲート長はプロセスノードを上回るスピードで微細化されている。これはなぜかといえば、「プロセスノードにあわせて微細化しても、それほど速度が上がらなかった」ことに尽きる。
前回、プロセスを微細化すればその分トランジスタが高速化されると説明したし、事実それなりには速度は向上したのだが、例えば350nm→250nmで40%微細化しても、トランジスタの速度は40%向上しなかったという話である。これを40%向上にするためには、ゲート長を200nmまで短縮しないとダメだったわけだ。以後、ゲート長はプロセスノードを上回るスピードで微細化に突き進むことになる。
ちなみに、少しだけ先の話をしよう。どこまでゲート長の微細化が突き進むかだが、ロードマップではそろそろ打ち止めになっている。これは表の2012年度の数字を見比べてみるとわかる。2012年の予測によれば、もうこの先の微細化の進み方は、プロセスノードと同程度でしかない。
「小さくするにも限度がある」わけで、その限度を2000年台に達成してしまった感がある。そのため、ロードマップは過去の延長から一応微細化の流れを描いているものの、どこまで現実的に実現できるかはITRSそのものも疑問に思っているようだ。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















