



ハイパースケールデータセンターを実現する次世代のサーバー&ストレージ 第2回
メニーコアプロセッサーで「手のひらスパコン」を実現!
ビッグデータを変える!Xeon Phi搭載サーバーの可能性
2013年09月03日 09時20分更新


|
|---|
既存のデータ解析とビッグデータの大きな差である処理速度や解像度。このギャップを埋めるには、既存のサーバーアーキテクチャでは難しい。インテルのXeon Phiを搭載したNECのメニーコアサーバーは果たしてどれだけの実力を持っているのか?
最大520スレッドを1Uで実現するビッグデータサーバー
前回説明したのは、「もっと大容量に、より高速に」という要件を満たすデータセンターの重要性だ。スマートデバイスやソーシャルメディアの普及、クラウドへのデータの集約化、多種多様なデータをビジネスで積極的に活用するビッグデータの台頭など、現在起こっているあらゆるトレンドが、データ量の爆発的な増大を誘発している。さらに、データが膨大になっていくということは、データの容量だけではなく、おのずと処理能力が必要になるということだ。つまり、これからのデータセンターは、今までに比べて桁違いのキャパシティと処理能力を有した“ハイパースケールな拡張性”が必要になるわけだ。
こうしたハイパースケールな拡張性を実現すべく、NECが他社に先駆けて開発したのがインテルの「Xeon Phiコプロセッサー製品ファミリー(以下、Xeon Phi)」を搭載したメニーコアサーバー「Express5800/HR120a-1」である。

NECのXeon Phi搭載メニーコアサーバー「Express5800/HR120a-1」
Xeon Phiは、超並列処理を実現するHPC(High Performance Computing)向けのコプロセッサーユニットだ。最大61のプロセッサーコアとローカルメモリをPCIボードに搭載し、メインCPUからの処理をオフロードするコプロセッサーとして動作する。演算能力やメモリ容量にあわせて、7100/5100/3100の3つのシリーズが用意されている。
Express5800/HR120a-1では、2基のインテルXeonプロセッサーに加え、このXeon Phiを最大2つまで搭載できる。Xeon Phiの搭載により、一般のサーバーの約10倍以上になる最大520スレッドという超並列処理が可能になる。
メニーコアサーバーでどのようなメリットが得られるのか? まず従来、大量のサーバーによって処理していたシステムをメニーコアサーバーに集約することで、サーバーの台数を大幅に削減し、設置スペースや消費電力を大幅に削減できる。NECの試算では、一般的な2ソケットサーバー120台を用いていた処理を、1/10の台数で行なえるという。また、設置面積は約1/3、消費電力は約1/6に削減できる。さらにXeon Phiの採用によって、独自の開発環境やスキルが不要となるため、アプリケーションの移行コストも大幅に削減することが可能だ。
こうしたメニーコアサーバーの適用用途としては、さまざまなものが考えられる。たとえば、古い映像データを修復するリマスター処理や、膨大な動画・画像データの圧縮や変換、撮影したデータとマッチングする画像検査システム、あるいは監視カメラの映像を元にした画像検査システム、不審者や危険物の発見を行なうセキュリティシステムなどが想定される。超並列処理の能力を活かし、学術機関や研究機関でのHPC領域だけではなく、一般企業が導入を検討するビッグデータなどの処理をより効率的に行なえるわけだ。
1テラフロップスのスパコンが手のひらに
もともとXeon Phiのようなメニーコアプロセッサーは、クラウドにおけるさまざまなワークロードに最適化されたCPUを開発する過程で生まれたものだ。インテル クラウド・コンピューティング事業本部 データセンター事業開発部 シニア・スペシャリストの田口栄治氏は、「研究機関やサービスプロバイダーなどに試作品を使っていただいた結果、大量のデータを超並列で処理していくのには、やはりメニーコアが最適ということです。将来のエクサスケールHPCを実現するためには、2倍の電力で100倍の性能といった高い性能を得る必要があることも、インテルにとっては大きな課題でした」と開発の背景を語る。HPCでの超並列処理を想定し、開発されたインテル初のMIC(Many Integrated Core)アーキテクチャ採用のプロセッサーがXeon Phiというわけだ。

インテル クラウド・コンピューティング事業本部 データセンター事業開発部 シニア・スペシャリスト 田口栄治氏
Xeon Phiの最大の特徴は、IAアーキテクチャのプロセッサーがそのままメニーコア化されていることだ。つまり、マルチコアCPUであるXeonプロセッサーとの本質的な違いは、並列度の違いのみ。そのため、同じ命令セットでそのままスケールできるというメリットがある。
この特徴は開発効率に直結している。HPCの世界ではGPUに演算処理を分散するGPGPUが普及しつつあるが、GPGPUの場合、CPUとGPUでそれぞれ異なるプログラミングが必要になる。並列化させるコードを抽出し、GPUのハードウェアに依存した言語とツールでプログラミングしなければならない。これに対して、Xeon Phiでは、Xeonと共通のプログラミング環境でより簡単に処理の超並列化が可能だ。
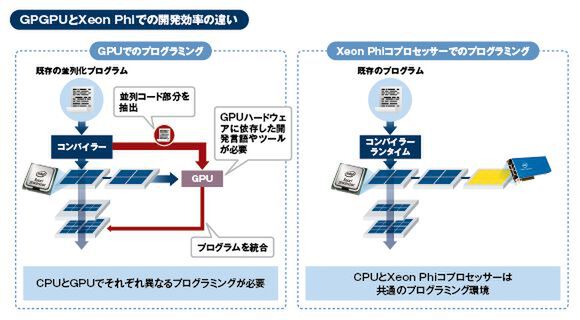
GPGPU(左)とXeon Phi(右)での開発効率の違い
「コンパイラが賢いので、処理を複数のコアに自動的に割り当ててくれます。ユーザーはアプリケーションに簡単な命令セットを追加するだけで“超並列処理の世界”に踏み出せるんです」と田口氏はアピールする。開発環境はもちろん並列度を調べるアナライザやスレッドチェッカーなどの開発支援ツールも充実しているという。
田口氏が「手のひらに載るスパコン」と呼ぶXeon Phiのインパクトは、従来のHPCでなければ実現できなかった超並列処理を容易に、しかも安価に利用できるという点だ。「Xeon Phiのユニット1つで1テラフロップスの処理能力を手に入れられます。高価で大規模なHPCシステムがなくても、“イノベーション”を起こせるということです」(田口氏)とのことで、超並列処理のコモディティ化に期待する。
(次ページ、単にXeon Phiを載せただけではない「HR120a-1」)
この連載の記事
-
第3回
サーバー・ストレージ
性能と安定性でさくらが選んだNECの「iStorage M300」 -
第1回
サーバー・ストレージ
HPCとビッグデータは融合!ハイパースケールなインフラへ -
サーバー・ストレージ
ハイパースケールデータセンターを実現する次世代のサーバー&ストレージ - この連載の一覧へ




