




連載205回でNVIDIAのロードマップを書いたばかりであるが、色々次が見えてきたので補足という意味も兼ねて、今回もNVIDIAのロードマップを解説しよう。
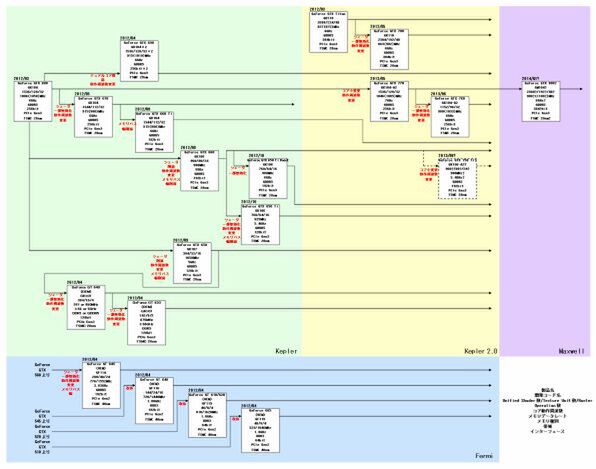
NVIDIA GPUロードマップ
前回はGeForce GTX 780とGeForce GTX 770がリリースした直後にお届けしたわけだが、その後のアップデートとしてNVIDIAはGeForce GTX 760を6月25日に発表した(関連記事)。

NVIDIAが6月25日にGeForce GTX 760を発表
当初この製品はGeForce GTX 760 Tiとしてリリースすると見られていたのだが、“Ti”を冠しない形でのリリースとなった。性能評価はベンチマークレビューを見ていただくとして、ポジション的には絶妙なのか微妙なのかにわかに判断しがたいところではある。
それはともかくとして、このGeForce GTX 760の発表に際してNVIDIAは2013年の製品ロードマップも明らかにしており、2013年に関してはこれ以上製品展開を行なわないことを明らかにした。

NVIDIAが示した2013年の製品ロードマップ
この結果として宙に浮いた形になったのが、GeForce GTX 750 Tiと目されていた製品である。もともとGeForce GTX 650 Ti Boostと性能面で被るだけに微妙な感じではあったのだが、後述する理由により、これ以上28nmプロセスで製品の手直しをしたくなかったのだろう。結果、Kepler 2.0世代はGK104-A2のみで終息することになってしまった。今後もし、なんらかの動向で新製品を出すことを決めたとしても、やはりGK104-A2ベースの製品になるだろう。
20nmプロセスの前倒しにより
「Maxwell」の投入が早まる
さて、ここからは今後の話だ。今年3月に開催されたGTC 2013においてNVIDIAはGPUロードマップとして2014年にMaxell、その後にVoltaというコアをそれぞれ用意していることを明らかにした。2014年のタイムスケールでは、Maxwellを投入する予定であるが、これは比較的早くなる見込みになっている。その理由はプロセスに関係している。
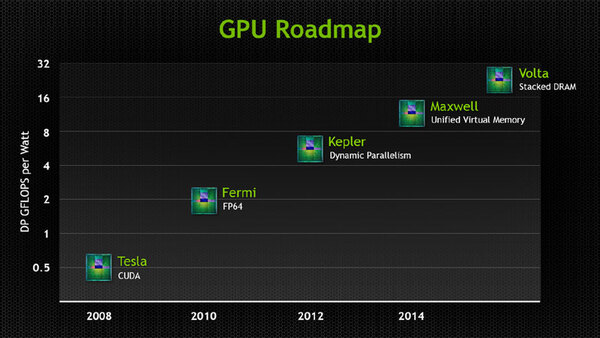
GTC 2013で示されたGPUロードマップ。縦軸はDP GFLOPS per Watt。つまり倍精度演算性能を引き上げるのだが、絶対性能ではなく消費電力あたりの性能であることに注意
NVIDIAはMaxwell世代に、TSMC(Taiwan Semiconductor Manufacturing Company Limited)の20nmプロセスを予定している。現実問題として現在の28nm世代でこれ以上の性能改善は難しいし、消費電力低減に関しても待機時の消費電力はともかく、稼動時の消費電力低減はかなり困難である。これはもう現在のトランジスターを使う限り無理である。
TSMCは、28nm世代でHP(High Performance)/HPM(High Performance for Mobile Application)/HPL(Low Power with High-K metal Gate)/LP(Low Power)の4種類のプロセスを提供しており(関連リンク)、Kepler世代はこの中で一番高性能なHPプロセスを利用している。
例えばこれをHPM、あるいはHPLといった「よりリーク電流/動作時電流の少ないプロセス」に置き換えると、消費電力あたりの性能は引き上げられるが、その代わり絶対的な動作周波数は低く抑えられることになる。
したがって同じ性能を出そうとすると、よりシェーダー数(CUDA Core数)を増やさないと辻褄が合わなくなり、これはダイサイズの大型化を余儀なくされる。するとコストが上がるわけで、今度は性能/価格比が悪化することになる。このあたり商品としてのバランスを考えると、やはり28nmのままどうこうするより、20nmにさっさと移行したほうが賢明という判断は当然ある。
その20nmプロセス(関連リンク)であるが、TSMCは20nm世代では1種類しかプロセスを提供しない。微細化しすぎてプロセスの諸々のパラメーターがあまりにクリティカルすぎるので、高速向けや低消費電力向けなどに作り分けが出来ないということであるが、TSMCによればこの20nmプロセスは28nmプロセスと比較して「30%高速で、1.9倍の回路密度で、25%消費電力が少ない」と説明している。もっとも「どの28nmプロセスと比較してか」が明確にされていないので、これも額面通り受け取るのは非常に難しい。
20nmプロセス(CLN20SOC)は、昨年のロードマップでは2013年中に量産に入るという話であった。
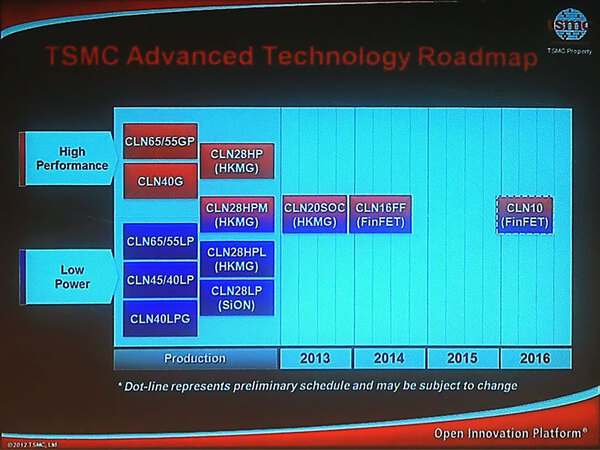
TSMCのロードマップ。これは2012年10月頃に公開していた資料だ
これに続き、配線は20nmプロセスのものを継承しながら、トランジスターだけFinFETという3次元構造にしたものを16nmプロセス(CLN16FF)として、2014年中に量産開始することを予定していた。ところが、今年前半にこのロードマップが大幅に前倒しになった。
TSMCは20nmプロセスを同社のFab12 Phase 6というファウンダリーで製造開始予定だったが、これに加えてFab14 Phase 5というファウンダリーも2ヵ月前倒しで操業を開始する模様で、この結果として、プロセスそのものに問題がなければ2013年中に量産出荷が開始になると見られている。
量産開始というのは、つまりチップの製造を開始するという意味で、量産出荷開始というのは完成したチップを工場から出荷できるという意味である。最近の先端プロセスの場合、この製造開始から完成までの間が数ヵ月(モノにもよるが、2~3ヵ月が当たり前)かかるから、これは大きな変化である。
この20nmプロセスを使うベンダー(NVIDIAだけでなくAMDやQualcommも該当する)は、当初こそ2014年初頭にサンプル品を完成させ、動作検証後に製造にかかるので、2014年第2四半期あたりに初期ロットが出荷という予定だった。
ところがこの20nmプロセスの前倒しにより、ほぼ1四半期出荷が前倒しが可能になる、というより1四半期前倒しにしないと競争に負けてしまうという事態に陥った。
AMDやNVIDIAが2013年後半の新製品投入をキャンセルした理由の1つは、もちろん28nm世代でこれ以上プロセスをがんばっていじっても性能が伸びないという理由もあるが、それよりも20nm世代の前倒しに備えて諸々の作業を先行させないといけないという事情の方が大きいと見られる。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ



































