



最新のバックアップ技術はここまでおさえておこう
仮想化や新メディアの登場で大きく変わったバックアップ
2013年03月21日 09時00分更新

仮想化の台頭でデータ保護が変わる
バックアップのトレンドとして、確実に抑えておきたいのが、仮想化への対応だ。物理サーバーに依存しない仮想化の普及は、バックアップソリューションにも大きな影響を与えている。
基本的には、ゲストOS上でエージェントを動かせば、物理サーバーと同じようにバックアップをとれる。しかし、複数の仮想サーバーをホストサーバーに集約すると、バックアップ処理のための負荷が大きくなってしまうという弱点がある。そのためスナップショットにより、バックアップ処理を外出しし、ホストサーバーの負荷を減らす試みが行なわれてきた。
一方で、ホストサーバーから仮想サーバーのバックアップを丸ごと取得してしまうという方法もある。ハイパーバイザーから見れば、仮想サーバーをファイルとして扱えるため、モビリティ(可搬性)を確保できるというのが大きなメリット。つまり、VMDKなど仮想サーバー自体のファイルをバックアップすることは、OSやアプリケーション、データまで含め、システム自体を保護することを意味するわけだ。リカバリの際も、物理サーバーを意識しないで済むし、遠隔にコピーすれば災害対策として活用できる。
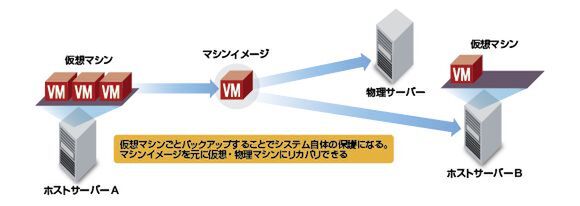
仮想サーバーごとバックアップをとれれば、システム保護になる
昨今は、こうしたモビリティを活用したユニークなバックアップソリューションが現われている。仮想マシンのイメージがあれば、リカバリは必ずしも特定の物理サーバー上に戻す必要はない。バックアップソフトを使い、仮想サーバーとして戻せるし、遠隔のデータセンターやクラウドにリストアすることも可能なわけだ。
データ爆発時代の救世主「重複排除」
もう1つの大きなトレンドは、やはり重複排除だろう。ブロックやファイルレベルで冗長なデータを削除し、保存する容量自体を減らす重複排除は、データ増大の著しい昨今のバックアップには必須の技術だ。データ量自体が減るため、ディスク容量を抑えることができ、バックアップにかかる時間も短くできる。特に仮想マシンを複数ホストするような環境では、重複排除の効果はきわめて大きく、ぜひ積極的に導入したい技術だ。
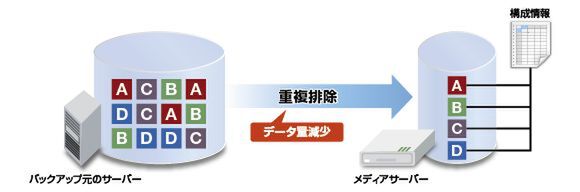
重複排除によるデータ量自体の削減
重複排除には、大きくストレージ側での実装と、バックアップソフトでの実装の2種類がある。
ストレージの場合、サーバーのバックアップを保存する際に、重複しているブロックを除外し、格納するデータ量自体を減らしてくれる。ストレージ側のCPUを用いて処理が行なえるため、サーバーでの負荷が小さいというメリットがある。

EMCの重複排除ストレージ「Data Domain」
一方、バックアップソフトで重複排除を行なう方法は、サーバーに負荷をかけてしまうが、ストレージを選ばないというメリットがある。また、ストレージに流れる前にデータを減らすことができるので、ネットワークに負荷をかけないというメリットがある。バックアップ対象となるデータの種類や量を考えて、適切なソリューションを選択しよう。
このように近年では、バックアップソリューションが大きく変わりつつあり、特にストレージとの連携が密接になっている点は見逃せない。 次回の特集3回目は、バックアップとセットで考える必要が出てきた災害対策(DR:Disaster Recovery)について詳細を解説する。
この連載の記事
-
第4回
サーバー・ストレージ
ストレージとクラウド活用でDRは導入しやすくなる -
第3回
サーバー・ストレージ
肝心な時に戻せない!バックアップはなぜ失敗するのか? -
第1回
サーバー・ストレージ
御社は大丈夫?バックアップがない企業はこうなる -
サーバー・ストレージ
今こそ見直したいバックアップとDR - この連載の一覧へ




