




強化による性能向上は意外に少ない?
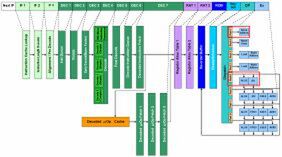
図1 Haswellの内部構造図。赤枠内がSandy Bridgeからの主な変更部分
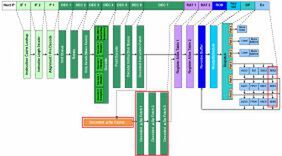
図2 Sandy Bridgeの内部構造図
これだけアウトオブオーダー部を強化したからには、性能もさぞかし上がるだろう……と思うところ。ところがHaswellについてIDFでの説明では、「最大で20~25%程度、同一周波数における性能比では10%程度」という話であった(20~25%は動作周波数の向上分も含む)。なぜかと言うと、インオーダー部に関しては今回ほとんど手付かずなようだからだ。
実際インテルも「パイプライン段数は同じ」「パイプラインは基本的に変えていない」と語っている。もちろん、Haswellで追加されるAVX2命令などで多少変更はあるものの、Simple Decoder×3とComplex Decoder×1という構成は変わらない。Decodeのプリフェッチサイズも、依然16byte/サイクルのままである。要するに、命令をメモリーから取り込む部分に関しては、Sandy Bridge世代からほとんど差がないわけだ。そのため、ここがボトルネックとなってしまうわけで、アウトオブオーダー部の性能をフルに生かすのは、「通常の状態」では難しい。
「通常の状態」とは、メモリー/1次キャッシュから命令をフェッチ/デコードして処理する、という意味である。だがSandy Bridge世代以降は、「通常の状態」ではないケースが存在する。それは「μOp Decoded Cache」から命令を取り込んで処理するケースだ。命令がμOp Decoded Cacheに乗っているならば、「IF1」~「DEC 6」は止まっていて、「DEC 7」以降だけが動作する。
この段階でμOp Decoded CacheからDEC 7のステージでは32byte/サイクルの帯域で接続されているので、投入できる命令数そのものが、「通常の状態」より多くなりえる。Haswellで追加された実行ユニットに、命令を供給するのに十分足りるということであろう。ようするに、繰り返し処理が発生したときだけは高速になるが、メモリーから命令を読み込んで処理する場合はSandy Bridge並みか少し改善する程度、ということになる。
この構成の理由は、例えば「Simple Decoder×4とComplex Decoder×1」のようにデコーダ部を強化するのは、非常に難しいからだそうだ。そうでなくてもデコード部は消費電力が一番大きい部分で、それゆえにNehalem以降では、Loop Stream Detector(LSD)やらμOp Decoded Cacheやらを使って、なるべくデコード部を動かさないですむ技術を採用してきていたわけだ。
もしHaswellでデコード部を強化するとしたら、単にデコード部だけではなくフェッチ部の帯域も引き上げないと、マッチしないことになる。言うまでもなく、これは大幅に消費電力が増える要因になる。その一方で、デコード部に単純にSimple Decoderを追加しても、デコード性能はそれほど改善されないかもしれない。もともと「Macro Fusion」などでかなり効率的にデコードができるようになっているから、このあたりから全部見直しをかける必要がある。効果的にデコード性能を引き上げるには機構的にかなり複雑になるだろう。
もしこれをやるとしても、22nmプロセスのままで行なうのはトランジスター数、ひいてはダイサイズの肥大化を招くことになり、あまりうまい方策ではないように思う。そのため仮にこれを実施するとしても、当分先であろう。インテルのロードマップでは今回が「Tick-Tock」のTock、つまり「プロセスを変えずにアーキテクチャーを変更する」番である。次のTickは、Haswellと同じ構造で14nmプロセスを使った「Broadwell」。さらにその先のTockで、同じ14nmを使いながらアーキテクチャーを変更する「Skylake」というロードマップになる。インオーダーに手を入れるとすれば、Skylake世代以降になる可能性が高い。
それならば、Haswellはなぜアウトオブオーダー部を改良をしたかと言えば、μOp Decoded Cacheがヒットしている間は確実に性能が上がるから。つまり性能/消費電力比の改善につながるからだ。μOp Decoded Cacheのヒット中はフェッチ~デコード部が止まっているから、もともと消費電力的にゆとりはあるし、ALUやStore Unitは単体ではそれほど大きな消費電力にならない。そのためこれらを追加すれば、性能/消費電力比を高めることになる。
その一方で、μOp Decoded Cacheがヒットミスした場合、この追加された実行ユニットは遊んでしまう公算が高い。しかし今ではクロックゲーティングや「Power Gating」により、遊んでいるユニットの消費電力を減らす仕組みが徹底しているので、性能/消費電力比はほとんど悪化しない。これにより、Sandy Bridgeよりも平均で10%ほど性能が改善するというわけだ。当然だが、プログラムによってどの程度性能が改善するかは、バラつくことになるだろう。
続く「分岐予測の強化」であるが、詳細はまだ明らかになっていないものの、Haswellの資料にはいろいろ「恐ろしいこと」が書いてある。資料によればこうだ。
- Initiate TLB and cache miss speculatively
- Handle cache misses in parallel to hide latency
- Leverages improved branch prediction
最初の項目は、TLBのミスやキャッシュミスを事前に予測して、これを避けるような方策がとられる、とある。2つ目がその方策で、複数のキャッシュミスを事前に予測して、並行してプリフェッチなどを行なうことにより、見かけ上のキャッシュミスによる待ちを最小限に留める仕組みが入った、としている。3つ目は詳細不明であるが、Sandy Bridgeの世代で大改造した分岐予測を、さらに強化したという。
というあたりで今回はここまで。Haswellの残りの改良点については次回に解説しよう。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



























