




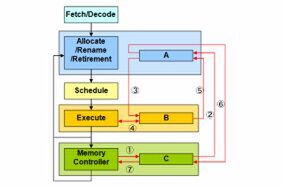
図3 Nehalem世代までのパイプライン
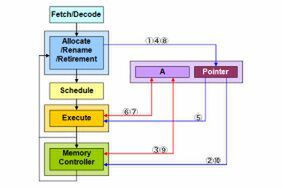
図4 Sandy Bridge世代のパイプライン
「そんないい方法ならば、なぜ今まで実装してこなかったのか?」というと、実装そのものが非常に難しかったからだ。図3で言えば、バッファ「A」はレジスタファイルの数だけ必要だが、「B」と「C」は各ユニットにひとつずつで済む。回路上で物理的に近接した場所に配置できるから、高速にアクセスできる。
ところが図4の方式だと、実行ユニットやメモリーコントローラーとPhysical Register Fileの場所が、物理的に近接しているとは限らないので配線が長くなりがちで、その分レイテンシも増えやすい。さらに、Physical Register Fileの割り付けを管理するポインタへのアクセスが余分に入るから、処理そのものも増える。
これまではこうしたデメリットを考えて採用しなかったわけだが、Sandy Bridgeではこうしたデメリットよりも、消費電力を減らすほうが重要と判断したわけだ。
レジスタのクリアも効率化
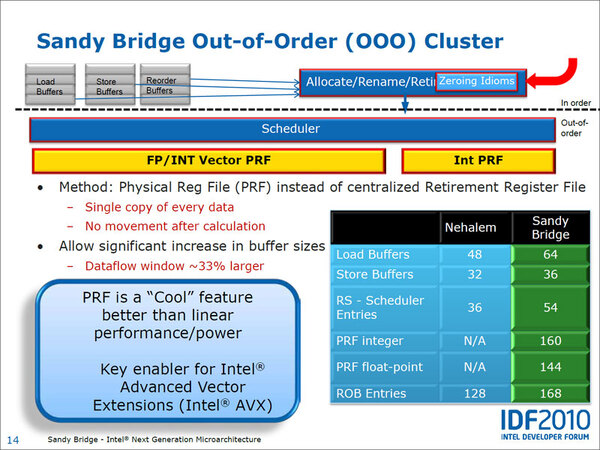
右の表がNehalemとSandy Bridgeのさまざまななバッファサイズの違い。Physical Register Fileの採用により無駄が省けた分、バッファの数を増やすことが出来るようになった
なお、Physical Register Fileの実装に合わせて、さまざまなバッファの数も増やされているのも、Sandy Bridgeにおける改良のひとつである。これに合わせて搭載されたのが「Zeroing Idioms」である。これは何かと言えば、「レジスタをクリアする命令を効率化する仕組み」とでも言えばいいだろうか。
x86の場合、レジスタをクリアするために以下のような命令を多用する。
- XOR EAX,EAX
Nehalemまでは、こうした命令を馬鹿正直に実行ユニットで処理していた。しかし、目的はEAXレジスタを「0」にできればいいのであり、XOR命令を実施したいわけではない。そこでこうした命令を「RAT 1」~「Rdy/Sch」の間に検出して、命令を発行せずに直接Physical Register Fileを操作して済ませてしまうのが、Zeroing Idiomsの役割である。これも命令処理の効率化と、消費電力削減に効果的である。
★
以上がSandy Bridge世代の主な改良点である。厳密に言えば64bit命令の効率化(Macro Fusionの対象となる命令の拡充)や、64bit OSの普及に合わせて大量のメモリーを搭載した場合のアクセス性の改善なども図られているが、これらは大きな違いというよりも細かな改良というべきだろう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

























