




AVX導入に合わせて帯域幅を256bit化
そのからくりとは?
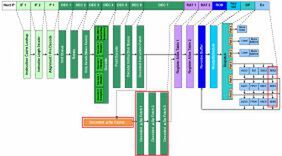
図1 Sandy Bridgeの内部構造図。赤枠内がNehalemからの主な変更部分
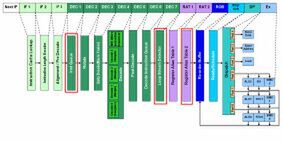
図2 Nehalemの内部構造図
第2の特徴はAVX命令と256bit化である。インテルはSandy Bridgeの世代で、256bit幅のSIMD命令であるAVX命令を実装した。なお「AVX命令とは何ぞや」については3年前の記事を参照していただきたい。
AVX命令は256bit幅となるため、データを1サイクルあたり256bit読み込めないと、せっかくの256bit幅が生かせなくなる。AVXにあわせて旧来のSSEレジスタは、すべて256bit幅に拡張されている。だが実行ユニットそのものまで256bit幅のものを搭載するのは、さすがに難しいと判断したのであろう。実行ユニットそのものは128bitのままながら、各ポートごとにユニットを追加して、これらをALU/FPU/SSE/AVXで使いまわすという方法をとった。
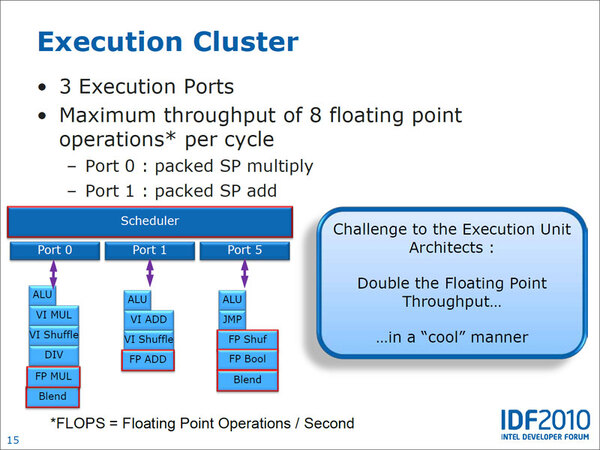
Nehalemの実行ユニットの図だが、ALUやJUMP、Vector Shuffle(VI)などはそのままに、赤く囲われた部分がSandy Bridgeで拡張された
どうやって実行ユニットを使いまわしたのか? まずALUとSSE Int、SSE FPUに関しては、データパス(データ転送を行なうバス)をそれぞれ別に用意して処理する。一方AVXに関しては、SIMD INT用とSIMD FP用の両方のデータパスを使うことで256bit分の処理を可能にした。
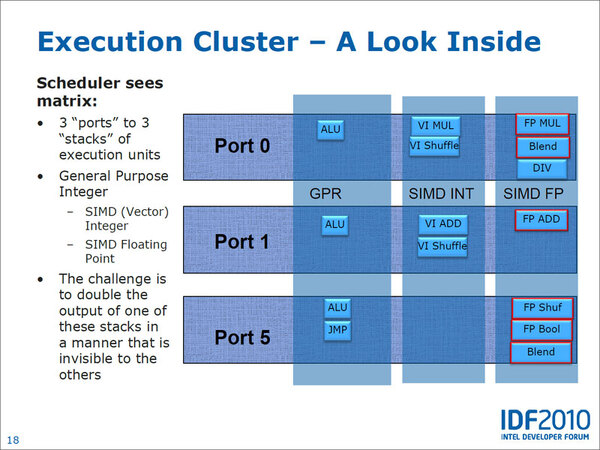
命令処理の仕組みを示す図。横軸は命令ポートで縦軸はデータパス。SSEのAdd(加算)命令の場合、命令は「Port 1」、データパスは「SIMD INT」(2列目)が使われて「VI ADD」が処理される。同様にSSEで浮動小数点演算を処理する場合、「SIMD FP」(3列目)のデータパスが使われて「FP ADD」が処理される
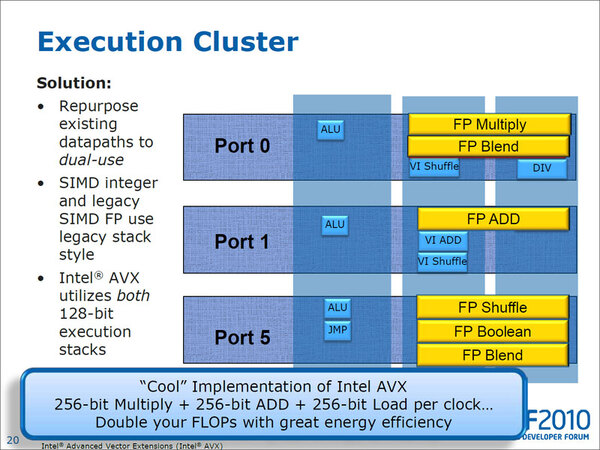
AVX命令の場合。AVXでAddを行なう場合、「SIMD INT」(2列目)と「SIMD FP」(3列目)の両方のデータパスが動き、それぞれが128bit分のデータを供給することで、トータル256bitになる
データパスの256bit化の次は、入出力の256bit化だ。面白いのが、CPUコアと1次データキャッシュ間は256bit化されているにもかかわらず、1次命令キャッシュとCPUコアの間は、128bit幅のままとなっている点だ。「IF 1」~「DEC 3」までのx86命令の解釈部は、引き続き16byte/サイクル(=128bit幅)で、最大4命令/サイクルのx86命令をデコードする「Merom」(Core 2)の構成から変っていない。
AVX命令になっても、命令長そのものが256bit幅になるわけではない。しかもAVXに関しては、Sandy Bridgeの世代では1命令/サイクルでしか処理できないから、128bit幅あれば十分だ。ALU/FPU/SSEは128bit幅で十分であることがMerom~Nehalem世代で確認されているから、結果としてロードストアユニットと1次データキャッシュの間のみが、256bit化されるに止まったわけだ。
ロードストアユニットは、使用するポートは引き続きPort 2~4のままながら、LoadとStore Addressを多重化することにより、「16byte/サイクル×2のリード」と「16byte/サイクルのライト」を同時に行なえるようになっている。P6世代から長らく変わらなかった部分であるが、ついに256bit対応ができるようになったというわけだ。
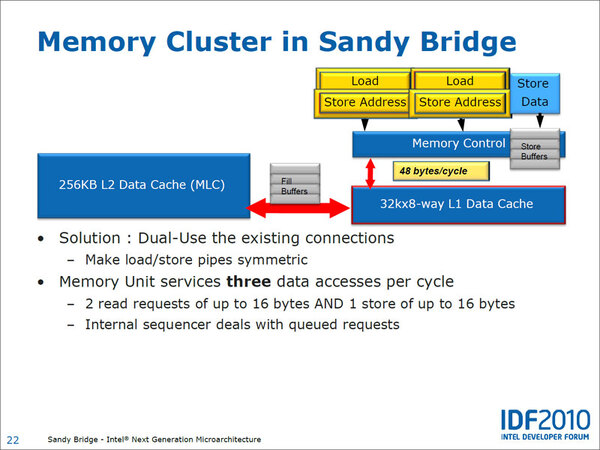
2次キャッシュ~1次キャッシュ~メモリーコントローラー間の帯域幅を示した図。メモリーコントローラーと1次データキャッシュが48byte/サイクルになっているが、これはリードの16byte/サイクル×2とライトの16byte/サイクルを合算した帯域
AVX命令の場合は、1つのレジスタへのロードを2つのロードユニットを使って行なうし、それ以外の場合は2つのロードを同時に行なえる。このあたりはAVX以外の命令の性能改善につながる改良といえよう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















