




「Early Decode」の導入で
省電力化と効率向上

図1 Yonahの内部構造図
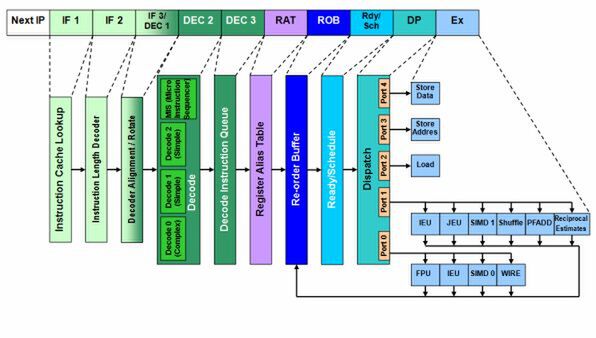
図2 Baniasの内部構造図
上にYonahとBaniasの内部構造を並べてみた。Baniasまでフェッチとデコードであわせて5段だった構成は、Yonahで7段に増やされている。まず命令フェッチでは「Alignment」と「Rotate」が分離されて、別々のステージになった。
Yonahのフェッチサイズは16byte/サイクルで、これはP6~Banias世代から変わっていない。またデコーダーも3命令/サイクルというBaniasを継承していると思われる。ただし、Yonahの開発時点で「次世代のアーキテクチャーではデコーダーを4命令/サイクルとする」という方向性はほぼ決まっていたと思われるので、これにあわせてフェッチ段の効率化や、高性能化に向けた取り組みが行なわれていたのは間違いないと思う。AlignmentとRotateを分離したのは、Micro Ops Fusion自体の対象となる命令が増えたことにより、命令のデコード順並び替えの頻度が増えることに対応しての措置と考えられる。
一方のデコーダ段であるが、RotateとDecodeの間に1段ステージが追加されている。これは「Early Decode」と思われる。Early Decodeとは、通常なら複雑な命令を直接Decodeで処理する代わりに、簡単な複数の命令に分解する処理を行なう部分だ。
Yonahの場合、DecodeそのものはP6~Banias同様に、ひとつのx86命令を複数のμOpに変換する「Complex Decode」が1基と、ひとつのx86命令をひとつのμOpに変換する「Simple Decode」が2基という構成である。本来ならばComplex Decodeで処理すべき命令を、Early Decodeで分解してからSimple Decodeで処理できるようにしておけば、相対的にComplex Decodeの利用頻度を下げられる。
もともとCPUのパイプラインで、相対的に消費電力が高いのはデコーダ部である。Complex Decodeを使う代わりにSimple Decodeを使うことで、多少の省電力化も期待できるわけだ。また、1基しかないComplex Decodeに対してSimple Decodeは複数存在するので、これにより同時デコード命令数を増やすこともできる。Yonahの世代ではそれほど効果はないが、これは次のMerom世代で明確にメリットになるので、このあたりも睨んでの設計であろう。
SSEユニット自体の改良で
Micro Ops Fusionに対応
- Decoderの高機能化。SSE3の対応に加え、SSE/SSE2への「Micro Ops Fusion」対応が追加された。
- Dispatch Portの強化(5ポート→6ポート)
- FPUとSSEのスループット強化
前ページで挙げた3つの改良点のうち、「Decoderの高機能化」は2つの側面がある。「SSE3の対応」とは、純粋に命令の追加である。一方、「SSE/SSE2へのMicro Ops Fusion対応」は、これとはかなり異なる。Baniasの回で説明したように、Micro Ops Fusionは基本的に、「load命令」+「整数演算」の組み合わせを、2つのμOpに分解せずにひとつのμOpのまま処理するものである。むしろ「load+整数演算」という、新しいμOpを追加したと言うほうが正確だろう。
だがSSE/SSE2に関しては話が異なる。SSE命令はご存知のとおり、128bit幅のレジスタを使ったSIMD演算命令である。演算によっても異なるが、8bitデータならば同時16演算、16bitデータなら同時8演算となり、64bitデータでも同時2演算を可能とする。ただし、最初にSSEを実装したPentium IIIでは、内部的には128bit分をまとめて計算するのではなく、64bit分ずつ2回に分けて計算していた。結果として、SSEを使って加算を行なう場合、まず最初の64bit分について「load」と「演算」を行なってから、次に残りの64bitのloadと演算という具合に、都合4つのμOpに分解されることになっていた。

YonahでのSSE命令に対するMicro Ops Fusionの対応に関する説明図。左が従来の変換結果で、右がMicro Ops Fusionによる変換。この手法を当時インテルは、「Digital Media Boost」と称していた(IDF Fall 2005の講演より)
BaniasでSSEがMicro Ops Fusionを利用できなかった理由は、「128bitレジスタから64bit分を抜き出す」操作が必要になるためだ。これを実現するには、デコーダ部に手を入れるだけではすまなかったからだ。YonahではSSEユニットにも大幅に手を入れて、128bit演算を同時に行なえるように改変した結果として、デコーダ部でもMicro Ops Fusionの対象にできるようになったというわけだ。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















