




6ポートに増やされたDispatch Port
実は5つで十分だった?

図1 Yonahの内部構造図
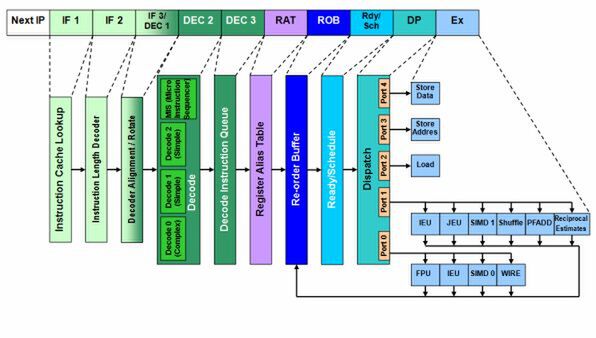
図2 Baniasの内部構造図
次の改良点は「Dispatch Port」の強化である。P6からDothanまでのアーキテクチャーでは、Dispatch Portは5ポート構成が踏襲されていた。5ポートのうち、Load/Storeユニットが3ポートを使っているので、それ以外の命令は実質2ポートしかない。Yonahではここが3ポートに強化された。またポート数の増加にともなって、実行ユニットそのものも改めて整理された。図1では簡略化しているが、Yonahの実行ユニットは以下の3つに分類される(図1右下の赤枠部分)。
- Vector ALU
- Scalar ALU
- Memory Access Unit
Vector ALUはMMXおよびSSEの演算用であり、5つの処理がPort 0~2に割り当てられる。
| Port 0 | Vector ALU 0、Vector Floating Multiply |
|---|---|
| Port 1 | Vector ALU 1、Vector Floating Add |
| Port 2 | Vector Shuffle |
Scaler ALUはFPUとALUの2種類があり、以下のように割り当てられる。
| FPU動作時 | |
|---|---|
| Port 0 | Floating Multiply |
| Port 1 | Floating Add |
| ALU動作時 | |
| Port 0 | Complex ALU(Multiply/Shift) |
| Port 1 | Simple ALU 1 |
| Port 2 | Simple ALU 2 |
Memory Access UnitはLoad/Storeがメインだが、新たに「Branch Unit」がPort 2に新設されている。
実はYonahで6ポートに増やされたDispatch Portは、続くMeromや「Penryn」(45nm世代Core 2 Duo)では5ポートに減らされている。しかし、ALU側に3ポートを割り当てるという点は変更されておらず、現在のCore iシリーズでも踏襲されている。実行ユニットの数も、YonahとCore iシリーズを比較してそれほどの違いはない。つまり、実はYonahでもデコード段をもう少し充実させれば、「Conroe」(65nm世代Core 2 Duo)と変わらないIPC(1サイクルあたりの命令処理数)を獲得できた可能性がある。
もっとも、Yonahの設計目標は「性能/消費電力比の改善」であった。これはALUを単純に3つに増やすのではなく、面倒な処理を行なう「Complex ALU」と、簡単な処理用の「Simple ALU」に分けて実装されたことからも明らかだ。デコード段の増加に合わせて、ALU側でも複雑な処理、例えば乗算や除算はComplex ALUにまとめてしまい、簡単な演算だけをSimple ALUに集約することで効率を上げよう、という方針だったのだろう。
だが、この方針がうまくいったかと言うと、怪しいところだ。MeromではSimple ALU/Complex ALUの区別をやめているので、おそらく「思ったほど効果がないね」という結論だったのではないかと思われる。
SIMD演算に関しては、上述のとおりVector ALUが大幅に強化されているので、多くの命令が128bitのまま、まとめて処理できるようになっている。ただし、全部の命令がそうなったわけではない。例えばPort 2に接続された「Vector Shuffle」とは、SSEレジスタの内部データを入れ替えるものだが、これは64bit幅なので、128bitを2回に分けて処理しなくてはならない。
同様に、SSEでの浮動小数点演算でも、「Vector Floating Add」と「Vector Floating Multiply」はどちらも64bit幅なので、128bit全体を一度に処理できない。このあたりが改善されるのは、次のMerom世代になってからである。ということで、次回はMeromのアーキテクチャーについて解説したい。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

























