




命令デコードでμOpに変換
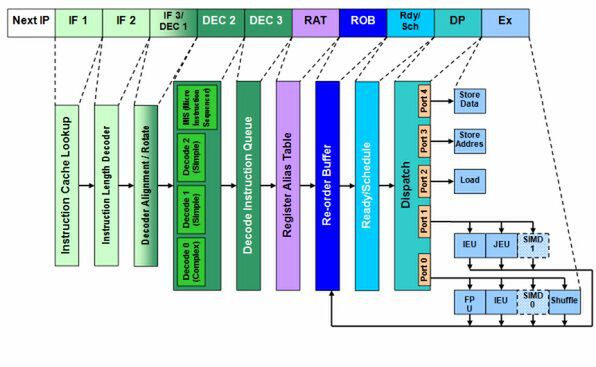
図1 Pentium Proの内部構造図
P6アーキテクチャーはIF2までに、最大で3つのx86命令を取り込む。取り込んだ命令を「μOp」に変換するのが、次のデコードである。μOpというのはようするに、「そのままの形でCPUが処理できる内部命令」と思えばよい。図1で「IF 3/DEC 1」となっている部分は、このステージの作業の半分がフェッチ、残りの半分はデコードに分類されるからである。
デコードの一番肝になる部分は、「DEC 2」のところである。ここには3種類4つのデコーダが用意されている。「Decode 0」は「Complex Decode」と呼ばれ、ひとつのx86命令を2つ“以上”のμOpに、「Decode 1/2」は「Simple Decode」と呼ばれ、ひとつのx86命令をひとつのμOpにそれぞれ変換する。例えば「メモリーにある2つのデータを足し算」という処理では、CPUは以下のような処理をすることになる。
- メモリーからデータ1をロードしてレジスタ1に格納
- メモリーからデータ2をロードしてレジスタ2に格納
- レジスタ1とレジスタ2の値を加算して、結果をレジスタ3に格納
元のx86命令では1命令で済むが、内部的には3命令相当になるわけだ。μOpというのは、この内部で行なわれる処理に1対1で対応する命令セットとなる。「CPU内部でRISC命令に変換」などと書かれることも多いが、これは元々のRISCの思想が内部命令に近いものだったからという話で、μOpが特にRISCを意識したわけではない。結果として「RISC命令に近いものになった」ということである。
インテルの資料によれば、レジスタ間の演算やデータ移動、あるいはメモリーからレジスタへのデータ移動は1μOpで済むが、メモリー/レジスタ間の演算やレジスタからメモリーへの移動は2μOp、レジスタ/メモリー間の演算になると、最大4μOpに変換される。ちなみに、図1のDEC 2にはもうひとつ、「Micro Instruction Sequencer」(MIS)と呼ばれるものがあるが、こちらはSimple DecodeやComplex Decodeでは対処できない複雑な命令を、マイクロコードベースで処理する部分だ。変換後のμOp数はいろいろだし、通常は1サイクルでは処理が終わらない。数十サイクルかかる場合もある。
DEC 2で変換されたμOpは、「DEC 3」の「Decoder Instruction Queue」にいったん格納される。これは続くRATのために、バッファにμOpを貯めておく必要があるためである。DEC 3では最大6つのμOpを格納できる。
アウトオブオーダーに欠かせない
レジスタ・リネーミング
DEC 3の後に入るのがRegister Alias Table(RAT)という処理だが、これは「レジスタ・リネーミング」という呼び名の方が通りがいいかもしれない。例えば以下のようなμOpが続いたとする。
- ① load R1, 1 (レジスタR1に1を代入)
- ② load R2, 2 (レジスタR1に2を代入)
- ③ add R1,R2 (レジスタR1とR2の値を加算して結果をR1に代入)
- ④ load R3, 3 (レジスタR3に3を代入)
- ⑤ load R2, 4 (レジスタR2に4を代入)
- ⑥ add R3,R2 (レジスタR3とR2の値を加算して結果をR3に代入)
この場合に問題になるのは、③の計算が終わるまで⑤の処理が始められないことだ。同じR2を使っているので、③が終わる前にR2を書換えてしまうと、③の結果がおかしくなってしまう。これを避けるための一番簡単な方法は、R2を使わないことである。
- ⑤’ load R4, 4 (レジスタR2に4を代入)
- ⑥’ add R3,R4 (レジスタR3とR4の値を加算して結果をR3に代入)
そこで(5)~(6)を上のように変えてしまえば、もはや⑤’は③の完了を待つ必要がない。R2は作業用に使っているだけなので、⑤のR2はR2でなくてもいいわけだ。
こうしてレジスタの干渉を解決すると、アウトオブオーダーで並行に処理を行なわせやすくなる。そのためアウトオブオーダーのCPUでは、利用できるレジスタを内部で大量に用意しておき、指定されたレジスタを適時切り替えることで、並行処理の効率をあげる仕組みが入っている。これがレジスタ・リネーミングあるいはRATと呼ばれる処理である。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ



































