




GPGPUを見据えたGPUになるはずが……
インテル Larrabee

Larrabeeのコンセプトを継承してようやく製品化された「Xeon Phi」
最後のネタはインテルの「Larrabee」(ララビー)だ。2000年代後半からGPGPUのニーズが高まっていることを受けて、インテルもGPGPU分野に対する製品投入の必要性を、強く感じていた。インテルはチップセット内蔵用のGPUコアとして、「Intel 740」をベースに強化を続けてきたものの、AMD(ATI)やNVIDIAに比べると、かなり低い性能のGPUコアしか持ち合わせていなかった。これを強化することも必要だったし、さらにGPGPU的な使い方が今後増えてくることは明白で、何らかの形で対応する必要があった。
そこでGPGPUをフルスクラッチではなく、x86をベースに作るという決断をしたのは、いかにもインテルらしいところだ。インテルは当時、x86以外のさまざまなアーキテクチャーが全部不成功に終わっていることを受けてか、「何でもかんでもx86で」という方向性に固執していた感がある。だがGPGPUにまでx86を投入するのは、「さすが」としか言いようがない。
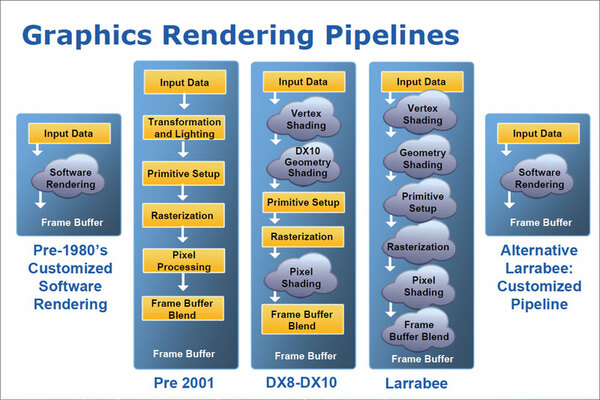
インテルによるGPUの進化の流れ。左から右へと進化していく。このレベルでの考え方は間違っていないと思う
Larrabeeの基本的な考え方は上図のとおり。昔は固定機能で描画パイプラインが構成されていたが、DirectX 8以降はプログラマブルシェーダーの登場によって、固定機能がなくてもうまくパイプライン的に処理できるプロセッサーがあれば、GPUが構成できるという発想だ。そこでLarrabeeでは、「P54C」(要するにPentiumのコア)を拡張してベクトル演算ユニット(Vector Unit)を追加し、これを複数並べるという構成を取った。
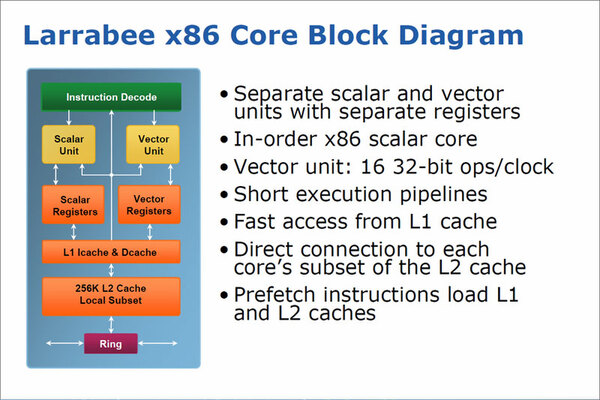
Larrabeeコアの構成図。左列の「Scalar Unit」や「Scalar Register」は、基本的にPentiumのものそのまま。一方右列の「Vector Unit」や「Vector Register」、256KBの2次キャッシュやリングバスインターフェースは新規追加
LarrabeeのVector Unitは、最大で同時16個のデータを処理できる巨大なSIMDエンジンである。通常のGPU的なオペレーションでは、この「16-wide Vector ALU」というSIMDエンジンがデータを処理し、非定型な処理あるいは特殊な処理の場合は、上のスライド左列のScalar側のコアが動く、というオペレーションを想定していた。とはいえ、テクスチャーユニットとかディスプレー出力は、別途用意しないといけない。そこで、Larrabeeコアと外部ユニットを、双方向のリングバスでつなぐという形で全体を構成した。
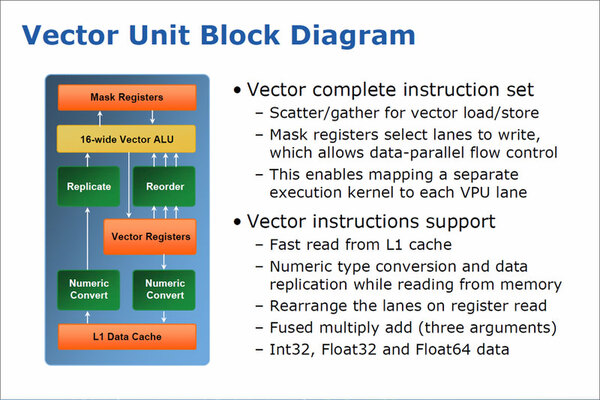
Vector Unitの構造。Vector Registerや16-wide Vector ALUは、既存の「SSE」や「AVX」とは互換性のない、まったく独自の構造である
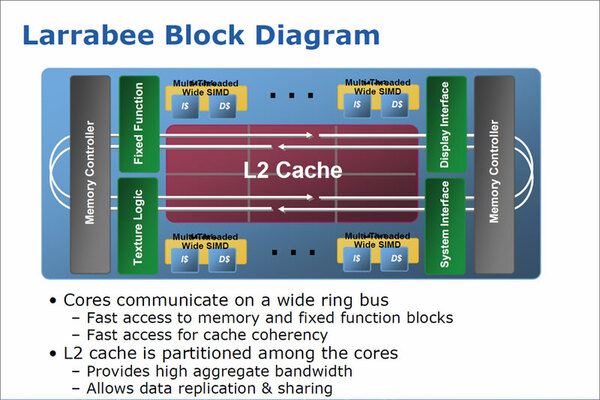
Larrabeeの構造。このコアが16個搭載された
2009年4月に北京で開催された開発者向けイベント「IDF 2009 Beijing」の基調講演では、Larrabeeは2009年末~2010年に市場投入される、と予定が発表された。同じ2009年9月にサンフランシスコで開催された「IDF 2009」では、実際に試作カードを利用しての動作デモも披露されている。

IDF 2009 Beijingでの説明スライド。当初は独立GPUのみで、統合型についてはもっと先というのが、このときの話であった
それにも関わらずインテルは、この2009年末にLarrabeeの製品化を断念。これに続いて開発予定だった「Larrabee2」も、やはり中止となった。何が悪かったかといえば、あまりにLarrabeeは構造が汎用的すぎて、GPUとして使うには性能/消費電力比が悪すぎたという問題と、絶対的な性能が低すぎた問題の2つが指摘されている。
問題の根幹は同じ理由にある。GPGPU的な使い方を考慮しすぎたために、GPU的として使う際にはほとんど不要なP54Cコアが残されており、性能/ダイサイズ的に不利になっていた。最大で同時16個のデータが処理可能なSIMDエンジンを持つとは言え、コアそのものが16個なら同時処理データ量は1サイクルあたり256個に過ぎず、これは当時競合していたAMDやNVIDIAのGPUコアと比べて、かなり見劣りするものだった。
また、リングバスはレイテンシーが2サイクルあり、メモリーインターフェースまでのアクセス時間がかなり長くなるコアもある。このあたりも、クロスバー接続を使っていたAMD/NVIDIAの製品よりも遅延が増えてしまった。「これでは市場に出しても競争力は非常に低い」というのが、サンプルを評価した顧客からのフィードバックだったそうで、さすがにインテルもGPU的な使い方をあきらめざるをえなかった。
インテルはLarrabeeアーキテクチャーそのものをあきらめたわけではない。45nmから32nmにプロセスを微細化して、コア数を32に増やすと同時にテクスチャーユニットなどGPUに必要な機能を省いたものを、2010年に「Knights Ferry」として開発者向けに提供を開始する(関連記事)。これは「Intel MIC Architecture」(MIC:Many Integrated Core)という新しい看板をつけたもので、GPGPUとしての使い方「のみ」を想定したものである。
これに続いて2012年6月18日には、22nmプロセスで50個以上のコアを集積した「Knights Corner」を、「Xeon Phi」という製品名で発売すると発表した。その意味では、Larrabeeは決して無駄ではなかったのは間違いないのだが、GPUとして見たときには間違いなく黒歴史入り、と呼ばれても仕方ないことであろう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



















