



アクセンチュアが考える技術的なブレイクスルー
“データが語る時代の端緒”統計のプロが考えるビッグデータ
2012年05月17日 09時00分更新

「ビッグデータ=大容量のデータ解析」というイメージがあるが、統計学に基づいたデータ解析は従来から存在していたものだ。では、データ解析のプロから見たビッグデータは、どのようなものなのだろうか? アクセンチュア テクノロジーコンサルティング本部 アナリティクスインテリジェンスグループ グループ統括責任者の工藤卓哉氏に聞いた。
全件データをとって見えるモノがある
アクセンチュア アナリティクスインテリジェンスグループは、ビジネス・アナリティクスと呼ばれる企業のデータ分析をはじめ、組織の最適な情報活用ソリューションの提案、データウェアハウス等の情報基盤構築から、分析力を武器にしたい組織に対して、高度な予測モデルの構築支援をしている部隊である。
今回お話を伺った同グループ統括責任者の工藤卓哉氏は、おもに多変量解析などのデータ解析分野を手がけており、テクノロジー面での支援を行なっている。工藤氏は、「もともとSASやR、SPSSなども、バッチアーキテクチャを前提としたアナリティクスを扱っていました。しかし近年は、形態素解析やテキストマイニング、ひいてはビッグデータと呼ばれる領域についてまでカバーするようになっています。たとえば、静的に埋め込まれた予測モデルで判定するものから、機械学習とインメモリの技術により、動的に予測モデルを高度化する技術が、一部のツールでも実現されつつあり、それら予測モデルの実装まで担当しています」と話す。最近では、SNSの解析のようなビッグデータ的な案件も増えており、社内でも積極的に勉強会やプロジェクトを立ち上げているという。

アクセンチュア テクノロジーコンサルティング本部 アナリティクスインテリジェンスグループ グループ統括責任者 工藤卓哉氏
まず、データ解析を行なっている立場からビッグデータの可能性を聞くと、「今までは統計的な有意性を示すために、バッチアーキテクチャで限定的に取得したデータを整理し、効果を見たい因子のみ条件を変えられるようにしてモデルを構築してきました。しかし、たとえば非接触認証技術などで行動履歴を動的に取得できるようになれば、サンプルメソッド自体が必要なくなるかもしれません。苦労して学習データでモデル構築し、有意性検定や検証を重ねるより、瞬時に全件をとって傾向を見てしまえば、正解補足率だけ限っていえば意思決定のスピードが速まる可能性があります」(工藤氏)と説明する。データ自体の「量」「多様性」「速度」が飛躍的に高まったことによって、経営にもたらす重要性や価値が向上した現在、わかりやすいキーワードとして登場してきたのが、ビッグデータではないかと工藤氏は考える。
では、こうしたビッグデータのソリューションは今までのデータ解析技術では難しかったのか? 「できなかったかといえば、できないことはなかったはずです。しかし、処理能力やリソース、コスト効果から考えると現実的ではありませんでした」(工藤氏)とのこと。分散処理技術の導入とハードウェアの向上、インメモリDBなどの技術的なブレイクスルーではじめて現実味を帯びてきたというわけだ。
シンプルなモデルでのストリーミング解析が有効
では、具体的にビッグデータでは、どのようなデータ解析が可能なのか? 工藤氏は「たとえば、ベイズ理論*や過去のデータを一定の基準でグループ分けする判別分析のようなシンプルなモデルであれば、機械学習とあわせることで有効な解析が可能になると思います。一方で、あまりモデルが複雑だと実装に耐えません」という。プロセスとして定義できるものはシステムに組み込めるのが前提だが、「複数の変数を可変させる重回帰分析などはモデルが複雑になるので、難しいのではないでしょうか」というのが工藤氏の意見だ。
*ベイズ理論:未来の事象(仮説に対する確率)は、現在の事象を動的に加味しながら(現事象を加味した条件付き確率で)、予測を機械的に向上させることができるとする理論
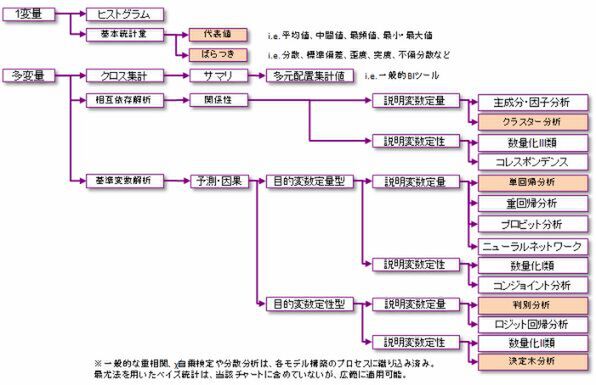
多変量解析モデル選定のアプローチ:ビックデータにむくモデル。一般には高度な変数ダミー化が求められず、バイナリ数値データなど判別しやすいデータ群に対して、ビックデータ処理向きのモデルがある(判別分析や、線形分類器、クラスタリングなど)。逆に、履歴データから傾向を判別するようなモデルには、ビックデータは不向き。たとえば、交互作用を時系列で取る分散分析や多重共線性などの排除が基本となる重回帰分析には不向きといえる(出典:アクセンチュア)
こうしたシンプルな統計モデルを背景にしたビッグデータの事例として考えられるのは、たとえばセンサーから取得した電力消費量からその住居に住んでいるお年寄りの状況を推測するといったソリューションなどだ。また、各所に設置されたエレベーターの電力消費量を集計し、稼働率を得るといったソリューションは線形解析で実現できるという。総じて、センサーで収集したデータをシンプルな解析モデルでストリーミング処理していくような用途は、ビッグデータに向いていると考えられる。
特にセンサーによるデータ収集に関しては、ビッグデータでのリアルタイム性や粒度という要件を満たす大きな特徴だという。「人手を使って交通量を収集して、渋滞などを調べることも理屈的には可能ですが、収集結果が次の日に出ても、意味がないですよね。センサーで収集結果をリアルタイムに送信して、ストリーミング解析までできれば、事故による通行止めや渋滞状況がわかる。収集だけでなく、抽出や集計、解析まで実現するという点では画期的といえます」と工藤氏は述べる。
一方で、今までデータを取得・活用していなかっただけで、既存の構造化データやRDBで十分解析できる分野も多く残っているというのが、工藤氏の意見だ。「たとえば、クレジットカードの利用履歴を見て、教育ローンを提案したりするソリューションは、RDBに構造化データを入れ、ソートしていけば、凝った予測モデルなんて構築しなくても導き出せます。ただし、それら構造化データから性別や世帯構成を逆引きするような予測モデル構築は、RDBの実装だけでは無理です」(工藤氏)。ビッグデータに限らないが、せっかくデータを収集しても、適切な入れ物やツールがなければ、有効な解析は難しいし、できることとできないことの線引きを把握できるリテラシを持つことも重要というわけだ。
総じて、工藤氏はデータ解析の可能性を拡げるものとしてビッグデータに期待を寄せている。「今は多少バブルなイメージもありますが、自然言語処理領域だけでなく、ライフサイエンスや社会インフラ部分など、有効な分野が絞り込まれてくると思います。ゼタバイトクラスのデータを扱うようになる可能性を秘めた将来、必ずしも、これまでの理論(演繹的)をベースとした古典的統計アプローチではなく、理論ではなく、データが物事を語る(帰納的)時代が来ると思います」(工藤氏)。
人のフィルターは避けて通れない
一方で、工藤氏は多様な分析ニーズを満たすソリューションの不足、そしてデータ解析のための人材不足などが課題に残ると指摘した。工藤氏は、「データが物事を語る時代が到来すると、処理性能の向上でリアルタイム性が増し、基本統計量も限りなく母集団に近く集約、抽出処理できるようになります。そのため、正解補足率だけを見れば、統計上サンプルなんて概念はいらなくなり、検定やモデル検証は不要になるという意見を、IT処理基盤を過信した一部の技術者が鼻息荒くいっています。しかし、それは慎重さを欠くコメントです」(工藤氏)と、よくある誤解について警笛を鳴らす。
同氏は「いくら自動化が進むといっても、データ解析に人のフィルターは避けて通れません。バイタルにせよ、センサーにせよ、せっかくデータがあっても、これを活かす実装方式と、それを評価できる運用方法を考える人がいないと、せっかく高度で有益な分析をしても現場で理解されず、現実的なソリューションになりません」と、データ解析を設計するための「データサイエンティスト」と呼ばれる人材が不足している点を問題視する。
人命に関わるライフサイエンスや国益(国防や国際紛争、セキュリティなど)の政策領域において長年携わってきた工藤氏は、「ビッグデータが古典的統計を駆逐する」というコメントをIT技術者から聞くにつれ、早期にデータサイエンティストを育成することが重要だと痛烈に感じているという。「たとえば製薬業界の製薬承認プロセス1つを取ってみても、分散分析などの実験計画法から得られる示唆、つまり負の交互作用(副作用)を見抜くことは、履歴データの静的なモデルからしか確度の高い有意性検定ができません。リアルタイム性を追求したり、大規模データを処理しても限界にぶち当たってしまいます。1つ間違えば副作用で尊い人命を失うリスクをはらんでしまう。こういう領域から古典的統計が消えてなくなることはないのです」と工藤氏は強調する。
つまり、ビックデータ解析で効果を得やすい領域もあれば、まったく太刀打ちできない領域もあるという指摘だ。「大切なことは、相互にこれらデータ解析手法が共存していくべき事実を理解し、データ特性に応じたメリット/デメリット、あるいはリスクを把握。そして、提案できる人材を育成することが、お客様に真の付加価値を提供していくことだと確信しています」と工藤氏は語る。高度な分析結果も、現場に噛み砕いて落とさなければ宝の持ち腐れ。また技術に過信することなく、つねに裏側に潜むリスクを見据えながら、データの解析効果を、現場に落とし込んで最大化する視点が、今求められている。その意味で、人のフィルターは避けて通れないわけだ。
この連載の記事
-
第14回
ビジネス
“シリコンバレーの技術者集団”ではトレジャーデータを見誤る -
第13回
デジタル
セクシーなデータサイエンティストになるまで5年かけていい -
第13回
ビジネス
富士通のキュレーターに聞いたビッグデータの新しい活用論 -
第12回
ビジネス
ビッグデータに一番近いダイレクトマーケターが考える価値 -
第11回
ソフトウェア・仮想化
「データ」をビジネスにしないとIT業界では生き残れない -
第10回
ソフトウェア・仮想化
富士通のキュレーターが挑む「ビッグデータからものづくり」 -
第9回
ビジネス
ビッグデータを使うWeb事業者が外食産業に進出したら? -
第6回
ソフトウェア・仮想化
“ビジネスでの価値は事例が語る”IBMが考えるビッグデータ -
第5回
ソフトウェア・仮想化
“非構造化データは宝の山”オートノミーが考えるビッグデータ -
第4回
ソフトウェア・仮想化
“常識を覆す迅速な仮説検証へ”JR東WBが考えるビッグデータ - この連載の一覧へ




