




本来の性能では出荷できず
後継のGTX 580は優秀な製品に
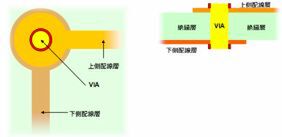
図4 シングルVIAの構造
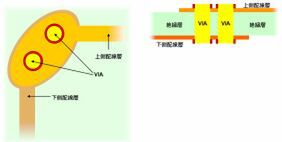
図5 二重化したVIAの構造
図4が通常のVIA、図5が二重化したVIAの構造である。それぞれの図の左側が上から見た状態で、右側が横から見た状態となる。VIAを二重化する場合、当然ながら接続部の面積は2倍では利かなくなる。配線を太くすることもそうだが、こうした配慮には余分な面積が必要になる。GF100では、この余分な面積を取る余地がないのが問題だった。なにせシングルVIAのままですら、550mm2のダイサイズである。全体をダブルVIA化したら、ダイサイズは600mm2近くになりかねない。同社としては苦渋の選択だったようだ。
そしてそのつけは、恐ろしく低い歩留まりとして返ってきた。なにせ最初のロットの歩留まりは、嘘か真かは不明だが2%ほどだったという。その後もステッピングを重ねてできる範囲での改良を施したものの、最終的に2010年3月のGeForce GTX 480発表時点で出荷可能な枚数は全世界を合わせて数千枚程度でしかなかった。
しかもこれは、本来512個のCUDAコアを集積したGF100を、480コアに制限しての出荷である。これは高すぎた消費電力を抑えるためと、冗長コアを用意することで多少の欠陥があってもダイを利用できるようにするという、両方の意味があった。元の280Wのままでは、ダイによっては消費電力が300Wを超えるカードになってしまう可能性があった。これではPCI Expressで利用できる供給電力の上限を超えてしまうから、もう少しマージンを取るために32コア分を無効にして、その分消費電力を抑えることが製品構成上必要だった。
結局のところGF100は、さらに無効とするCUDAコアの数を増やした「GeForce GTX 470」や、「GeForce GTX 465」といった製品でなんとか消費できた。そして幸いにも、NVIDIAには時間が与えられた。当初TSMCは40nmプロセスに続いて、32nmプロセスの提供を開始する予定であった。ところがこちらもトラブルが続いたため、最終的に32nmプロセスのサービス提供を中止。28nmに注力することとなる。だが、28nmプロセスの利用開始時期は2011年後半とされていたので、当面は40nmプロセスのまま継続するしかなかった。
これを受けてNVIDIAは、GF100コアを再設計する。今度は単にVIAの数を増やすのみならず、トランジスター構造の見直しまで行った。GF100では設計期間が短かったためか、高速かつリーク電流大のトランジスターを多用していたが、遅くても済む部分には低速でもリーク電流を抑えるトランジスターを配置するなど、改良はごくまっとうであった。
これらは時間を喰う作業でもあり、設計期間が短いときにはどうしても後回しになる。NVIDIAは明確にしていないが、おそらく配線層も増やしたのではないかと思われる。配線層を増やすことはVIAの数の増加と歩留まりの悪化、製造コストのアップにつながる一方で、配線そのものの短縮や、配線のサイズアップをしやすいというメリットもある。歩留まりに関しては、今度はデュアルVIAや配線の冗長化などを図ってカバーすることが可能だ。
こうして2010年11月に登場した「GF110」コアは、今度こそ512のCUDAコアをフルに生かすことが可能になり、また動作周波数もGF100より多少引き上げることが可能になった。これが「GeForce GTX 580」として、当時の「Radeon HD 5870」から最高速GPUの座を奪い取った。さらに「Tesla M2090」としてGPGPU向けにも大量投入されることになり、こちらもHPCの分野で大量に使われることになった。そしてその影で、GeForce GTX 480はひっそりと消えていった。
再設計したGF110は十分に優秀なチップだから、元々のコンセプトが間違っていたとも言いにくい。やはり設計期間が短すぎたのが、GF100が黒歴史入りした最大の理由だと言えるだろう。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ







が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")




























