




一般的な構造と異なる路線を選択した
NV30のアーキテクチャー
今から思えばNV30の構造は、既存のGPUをGPGPUに作り変えるための第一歩であったと考えられる。当時の従来型の延長にあるシェーダーは、例えば図1のような構造を取る。
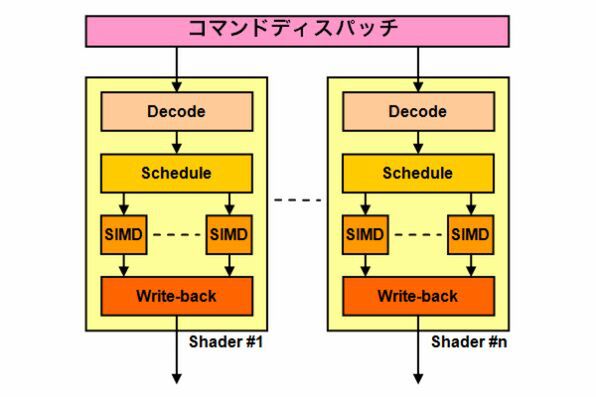
図1 当時の従来型シェーダーの構造例
まず、頂点演算や描画演算といった命令を複数個受け取ると、それを複数個のシェーダーに割り当てる(ディスパッチ)。各々のシェーダーはその命令を受け取って解釈し、それを自分の配下にあるSIMDエンジンに実行させて、最後に書き戻すという仕組みだ。書き戻し先はメモリーだったりキャッシュだったり、一時的に待避できるバッファだったりと、アーキテクチャーによって異なる。このあたりはCPUによく似ている。
これに対してNV30のアーキテクチャーは、例えるなら図2のような構成だったと考えられる。シェーダーそのものの数はずっと少なく、その代わり大規模な構成になっている。
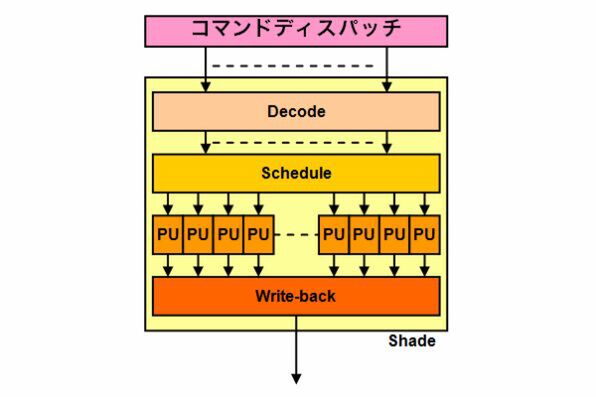
NV30のシェーダーの構成
そしてシェーダーは図1と異なり、複数の命令を同時にハンドリング可能となっている。最大の特徴はSIMDエンジンの代わりに、細かな演算ユニット(PU、Processing Unit)を複数搭載することだ。これはどういう意味があるか? 頂点シェーダーとして使うケースを考えてみよう。
例えば図1のケースで、各シェーダーが4つの128bit SIMD(32bit×4 or 16bit×8)の演算が可能だとする。このSIMDでトライアングルの頂点計算をやろうとすると、同時に1~2トライアングルしか処理できない。1つのトライアングルには当然頂点が3つあり、各々の頂点が3次元(X、Y、Z)の座標軸を持つから、1個のSIMDエンジンで同時に処理できる頂点の数は16bit座標の場合で2つ、32bit座標の場合は1つしかない。
各シェーダーはこのSIMDエンジンを4つ持つので、同時に頂点を4ないし8処理できる勘定になる。だが、データ的には1トライアングルをひとかたまりとして処理するから、同時に3ないし6の頂点演算が行なわれて、SIMDエンジンは1つ遊んでいることになる。もし、複数のシェーダーにまたがる形でトライアングルの処理を行なえれば、もう少し効率が上がる。だが今度は、コマンドディスパッチが恐ろしく複雑になるし、各シェーダーのライトバックの結果を組み合わせて、データを構成する手間が発生する。
一方で図2の構成では、各々のPUは16bitか32bitの固定演算ユニットであるが、複数のPUを自由に組み合わせて、同時に処理可能という仕組みになっている。そのため例えば頂点演算なら、3つのPUを組み合わせて計算させられる。もし図1でシェーダーが全部で4つあるとすると、SIMDが合計16個あり、32bit演算が同時に64個可能という計算になる。一方図2で64個のPUがあれば、同時に7つのトライアングル(3PU×3×7=63PU)の頂点処理が可能ということになる。演算器そのものを増やさなくても、内部構成を変えるだけでトライアングルの処理性能を、倍近くまで引き上げることが可能というわけだ。
この構造は、もうひとつメリットがあった。それはプログラミングの容易さである。最近はマルチコアとかメニーコアが当たり前になっており、複数のプロセッシング・コンテキスト(この図で言えばシェーダー)を並行に処理するマルチスレッドプログラミングが当たり前である。しかし、2002年当時はまだ一般的とは言いがたく、むしろ1つのスレッドの内部を勝手に展開して、広い幅の実行ユニットで内部的に並列処理するという方が一般的だった。
そのため、GPGPU的な考え方からすると図2のような構成の方が、好ましいと考えられる。NVIDIAはとりあえず、Cgである程度のプログラミング環境を整えたわけだが、まだこの時点ではGPGPU世代のプログラミングモデルを含めた全体像を、完全には固めきれていなかった。そのため、いろいろな点で試行錯誤をしている状況だった。おそらくNV30の構成も、そうした試行錯誤の中のひとつの選択で、プログラミングの容易さを優先した構成だったのだろう、と想像される。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ







が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")




























