




アーキテクチャーはK10と似通う
電力効率重視のためか?
もうひとつのメリットは、「Fusionへの移行の筋道が立った」ことだ(関連記事)。Fusionでは将来的にAPUとFPUが混在する形になる予定だが、今回FPUをコアの外に追い出したことで、将来的にAPUをここに組み込みやすくなった。AMDの場合、Fusionの進化は「1度に1ステップ」というゆっくりとしたペースでの移行を考えており、今回のFPU共有化もこの一環、と考えることもできるだろう。
FPUのみならず、フェッチ/デコードまで共有化したのは、単にダイサイズの節約以上の狙いもあると考えられる。キャッシュからデコードまでの構造は下のスライドに示すとおりである。
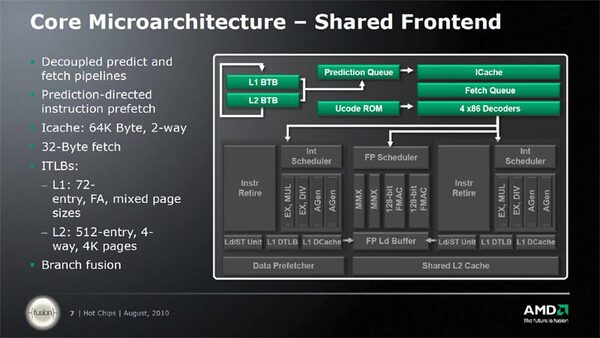
Bulldozerの構造図。TLBは増強されているし、デコードは4命令/サイクルに強化されているが、フェッチのサイズは32byteのままというのが面白い
面白いのは、このフロントエンドの構成がK10ベースのPhenom IIとほとんど変わらないことだ。もちろん、デコードはPhenom IIの3命令/サイクルから強化されているが、逆に言えばその程度の差でしかない。
Bulldozerの場合、それぞれのコアで1スレッドずつの処理が可能だから、例えば6命令/スレッドのデコーダーを用意すれば、理論上はほぼPhenom IIと同じピーク性能になる。あえてそれをしなかったのは、そこまでしても性能にあまり寄与せず、その割に消費電力が増えるので、AMDの言うところの「ワット性能」がむしろ低下するためと考えられる。
もともとK8(Athlon 64世代)~K10のアーキテクチャーでは、ALUとAGU(アドレス生成)がペアで配される形になっており、理論上は「Load」+「演算」が同時3命令処理可能、という仕組みだった。BulldozerやBobcatでALUとAGUが分離されたのは、実際にはこの組み合わせでピーク性能が出ることは少ない、と判断されたためだと筆者は考える。
命令がLoad+演算ばかりの場合は、K8~K10の構成はきわめて効果的である。ところがLoad命令が単独とか、Loadを伴わない演算命令ばかりといったケースでは、半分のユニットしか動かないことになる。またこうした単独命令の場合、K8~K10の世代ではLoadかALUが最大3命令までしか処理できない。一方でBulldozerやBobcatの場合は、ALUが2つとAGUが2つという構成だから、こうした単独命令の場合は最大で同時4命令まで処理できることになり、むしろ性能が上がる。
実行ユニットのこうした方針変更は、当然デコード段にも影響を及ぼす。もともとK10の世代では、SSE命令を同時に2つ処理できることを狙い、1次キャッシュの帯域を32byte/サイクルに増していた。これがそのままフェッチの帯域になっていたが、デコードは3命令/サイクルで(一部の命令を除くと)明らかにフェッチの帯域が過剰だった。
それがBulldozerでは4命令/サイクルのデコードとなり、バランスが多少改善された。また、実行ユニットが実質2命令/サイクルとなったことで、2コアで4命令/サイクルという、ちょうどマッチしたデコード性能になった。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



























