




さらなるCPUとGPUの融合を見据えて
Fusionの進化は進む
ではこの先はどうなるのか?(写真4)。現在挙げられている範囲の機能には、以下のようなものがある。まずAMDのI/O仮想化技術「AMD IOMMU」が仮想記憶に対応することで、GPUからCPU管理の仮想メモリーにアクセスしたり、逆にCPUからGPU管理の仮想メモリーにアクセスできるようになる。PCI Express Gen3対応により、CPU/GPUと外部を接続するバスの帯域も増加する。さらに先には、GPUを含むシステム全体のキャッシュコヒーレンシーや、GPUを含むコンテキストスイッチといった方向性も検討されている。
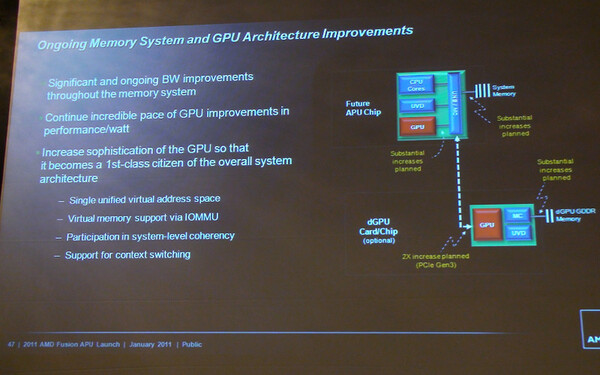
写真4 次世代におけるFusionの構成。図は似たようなものだが性能は改善する見込み
こうしたハードウェアの進化により、次第にFusionのテクノロジは高いレベルでの融合を見せると、マクリー氏は述べた(写真5)。マクリー氏が予想する進化のプロセスは以下のようになる。

写真5 Fusionの進化の方向。最終的にはOSレベルでの統合に向かう
- ①現状はとりあえず統合しただけ。ただしメモリーアクセスの効率化は実現
- ②次のステップでは、CPUとGPUのインターフェースの改善、高水準言語によるGPUサポート、GPUとCPUを合わせた形での電力管理が達成される
- ③CPUとGPUが同じメモリー空間をアクセスするようになり、この結果GPUが仮想メモリーを利用できるようになる。この段階でキャッシュコヒーレンシも実現されるほか、GPUが単独ではなく、システム全体のハードウェアスケジューラーの管理下に置かれる
- ④ ③が実現したら、GPU処理のコンテキストスイッチやランタイムレベルのタスク処理の統合などに向かう。このレベルで初めて、アーキテクチャーあるいはOSレベルでの統合が実現する。また外部GPUのコヒーレンシもこの段階で実現する。
ハードウェアがこうした進化を実現したときに、問題となるのは当然ソフトウェア側である。例えば②から③に進む過程で、現在よりも高度なレベルのミドルウェアが必要になる(写真6)。ただし、このレベルでは当然ながらOpenCLなど従来のミドルウェアも使われているため、新しいミドルウェアは従来のAPIと互換性を持ったものになる。

写真6 統合が進んだ世代では、現在のデバイスドライバーモデルに代わる、新しいレイヤーが追加されると予想
マクリー氏に、「ではこの世代では、デバイスモデル※1はどうなるのか?」と聞いたところ、長い答えを一言でまとめると「この世代ではデバイスモデルが意味をなさない」だった。互換性のため、従来のGPUと同じように見えるデバイスモデルは作成されるが、その中身は単にソフトウェアランタイムを呼び出すだけの、仮想デバイスドライバーになるという形を想定しているようだ。
※1 ハードウェアがすべてデバイスドライバー経由で操作される、現在のソフトウェアのモデル
③~④の世代になると、さらに融合が進む(写真7)。アプリケーションは従来のGPUモデルを使うことも、「FSA」(Fusion System Architecture)モデルを使うことも、あるいはGPUを直接操作することも可能になるという。

写真7 将来のソフトウェア構成の予想図。左は従来型モデル、右は進化したFSAモデルの構成
ではこの世代では、CPUとGPUの処理分担はどういう形で実現されるのかというと、まだ検討中の段階という話だ。写真8はグループインタビューでマクリー氏がホワイトボードに書いた説明図だ。「あくまでひとつのアイディアだが」と前置きした上でマクリー氏は、「例えば(図左のキューに積まれた処理から)CPUの処理とGPUの処理を振り分けることはできる」と述べた。
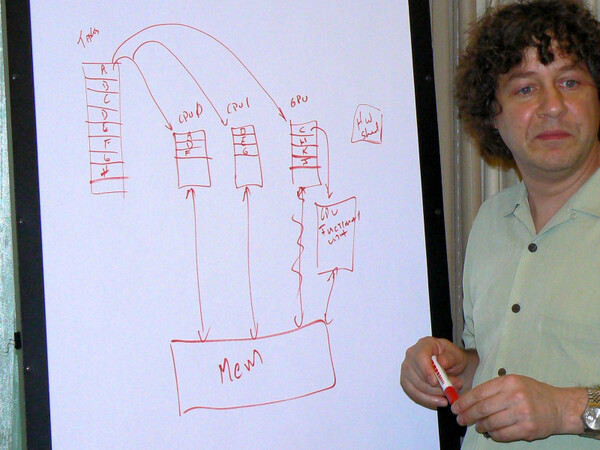
写真8 将来のタスクスイッチングについて、図を描きながら説明するマクリー氏
これは粒度の大きい、つまりCPU処理とGPU処理が明確に分離できるようなプログラムには有効だ。しかしもっと粒度の細かい、つまりCPUとGPUの処理が混在しているようなプログラムでは、切り替えのたびにキューに積み直す形になり、これでは効率が悪い。
とはいえ、こうした仕組みについての議論は、そもそもこの世代がどんな形でCPUとGPUを融合させているかと密接に関係している。だから、現時点でここだけを取り出して議論することには、あまり意味がない。
ちなみに、③~④世代が実現するのは「まだだいぶ先」(マクリー氏)とのことで、筆者もここ2~3年の間に実現するのは、せいぜい②までであろうと思う。現時点のLlanoや、次世代Bulldozerベースの「Trinity」にしても、おそらく①の範疇からは出ない。逆に言えば、Fusionをまだまだ進化させていくことを、AMDがきちんと計画していることがわかると言えよう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























