




単位、判定方法、処理タイミング
意外と違う重複排除
重複排除はデータをブロックに分割。比較したうえで、重複を排除。その構成要素と設計図だけを保持することで、データを削減するというものだ。重複排除を実装する製品は数多いが、一言で「重複排除」といっても実はいろんな技術がある。桂島渡氏によると、大きく重複排除の単位、判定方法、そして処理のタイミングなどが異なってくる。
重複排除の単位については、ファイル単位、固定長ブロック、可変長ブロックなどに分けられる。同じDell|EMCの製品でも、Dell NS(EMC Celerra)がファイル単位で重複排除を行なうのに対して、Dell DDは可変長ブロックで効率的に重複を排除する。「固定長だと、途中にデータが挿入された場合にズレが生じ、重複を認識できなくなる。可変長はこのズレを自動的に吸収できる」(桂島氏)。
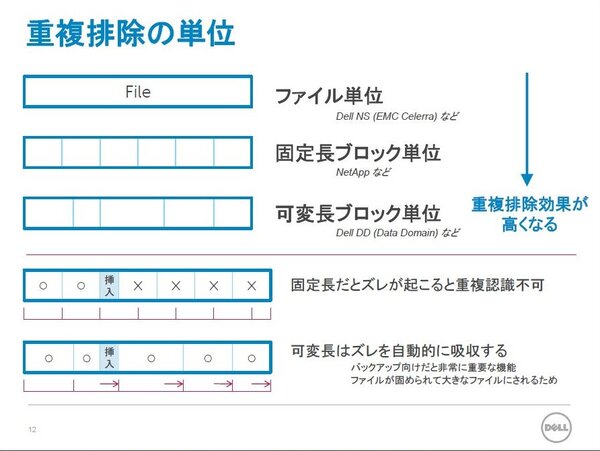
重複排除の単位としては、ファイル単位、固定長ブロック、可変長ブロックなどがある
また、データ自体の重複を判定方法としては、データ自体を付き合わせて比較する方法、データ比較とチェックサムを行なう方法、そしてデータのハッシュ値を比較する方法の3つがあるという。同じ値同士で衝突する確率がほとんどないため、現在ではDell DDも含め、サイズが小さく、比較が容易なハッシュ値を使うのが一般的。ただ、登場した当初は市場に受け入れられないという考えも多く、データ自体を付き合わせていたベンダーも多かったようだ。
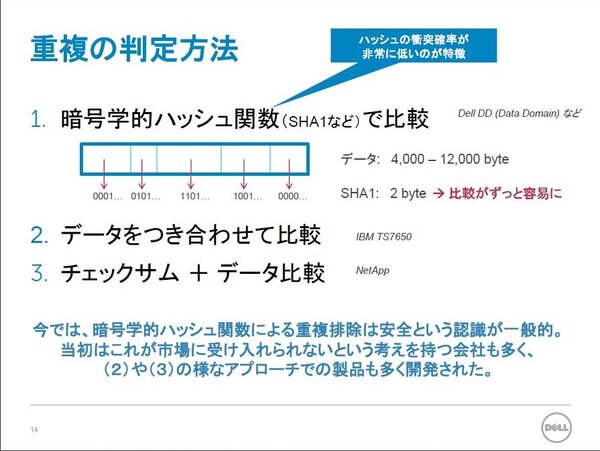
重複の判定方法としてはハッシュ値を比較する方法が主流になっている
さらに重複排除の処理タイミングについては、ディスクに保存する前に実行する「インライン処理」と、いったんディスクに保存した後に実行する「ポストプロセス処理」の2つがあるという。バッファが必要で、ディスクアクセスの多いポストプロセス処理に対して、Dell DDが採用するインライン処理では、バッファが必要なく、ディスクアクセスも1回で済む。もちろん、バックアップ時にかかる負荷はインライン処理のほうが重いが、最近はCPUの進化で無視できる程度にとどまっているという。
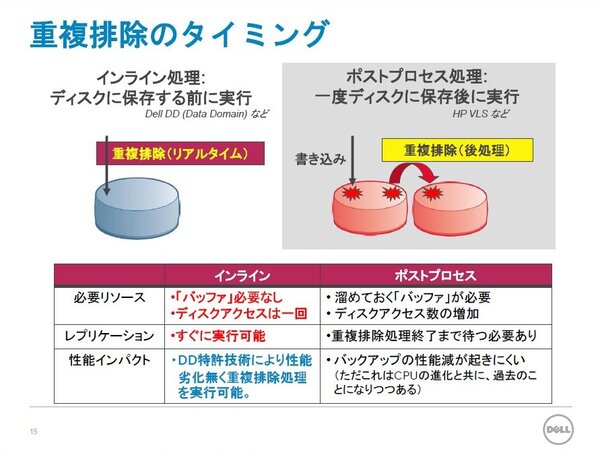
重複排除の処理タイミングはインライン処理とポストプロセス処理の2つがある
コンテンツに合わせてアルゴリズムを変える
オカリナの新技術
後半では重複排除技術について説明した。桂島氏によると、重複排除は専用製品ではなく、さまざまな用途で用いられるようになる。バックアップやアーカイブだけではなく、プライマリストレージでの適用が進むほか、データライフサイクル管理の中に組み込まれ、バックアップ、アーカイブなどの処理ごとに重複排除を行なわないで済むと予想される。
こうした重複排除の進化や一般化を見据えてデルが買収したのが、オカリナネットワークスである。オカリナでは「コンテント・アウェア型」と呼ばれる技術により、コンテンツの種類に合わせて重複排除や圧縮の方法を変えることができる。今までの重複排除ではデータの種類と問わず均一に処理されているが、たとえば圧縮の効かないJPEGなどは対象から外してしまう。
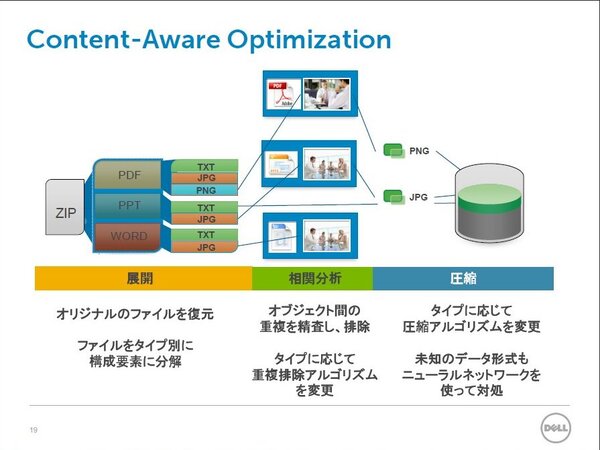
オカリナネットワークスの「コンテント・アウェア型」重複排除・圧縮
同様に、2000以上のファイルタイプを登録済みで、タイプに合わせて40以上のアルゴリズムを使い分ける。このアルゴリズムのなかにはJPEGすら圧縮してしまうという技術もあり、重複排除と合わせて高いデータ削減効率が得られる。「既存の製品では、重複排除や圧縮は映像や画像に弱かったが、オカリナの技術であれば大幅にデータを削減できる」とのこと。製品への実装が楽しみだ。




