




ストレージのコストを減らす重複排除
想定される事故・障害に備えてまじめにバックアップを行なうと、バックアップの対象となる本番データに比べて、はるかに多くのデータ量を保管することになる。たとえば、4世代ぶんのフルバックアップを保管するという運用であれば、本番データ量の5倍以上のデータ量を持つ計算になる。これをすべてストレージ装置で保管しようとすれば、必要なHDDは大量になり、テープに比べてはるかに高額な費用をかけなければならない。
最近ではイントラネットやメールなどのデータもバックアップの対象となっている。これらのサーバーに蓄積されるデータには、重複が多いことが知られている。特にメールの添付ファイルは、「CC」あるいは転送などの処理により何回もコピーされることが多く、サーバーのディスク容量を圧迫することが多い。バックアップ用のストレージ装置でも同じことがいえる。そこで、同じデータを繰り返しバックアップしないよう、「重複排除(重複除外、De-duplication)」の技法が考案された。
古くから使われている「データ圧縮」も、重複排除の一種といえる。典型的なデータ圧縮の方法は、1つのファイルの中で「繰り返し出現するビット列(データパターン)」をより短いシンボルに変換して記録するというもので、これによりメディアに書き込むデータ量を削減する。
次いで登場したのが、「ファイル単位の重複排除」である。これは、ファイルごとに一意なIDを割り当てる。そしてファイルを保存する際には、すでに同じ内容のファイルが存在しないか確認し、存在する場合はそのファイルのデータを保存せずにIDだけを記録する。この方法により、同じ内容のファイルを重複して保存することが避けられる。
そして最近の重複排除の技法としては、「ブロック単位での重複排除」である。これは、1つのファイルを数KBから数十KB程度の細かいブロックに分割して、ブロック単位で重複したデータを保存しないようにする技法である(図4)。
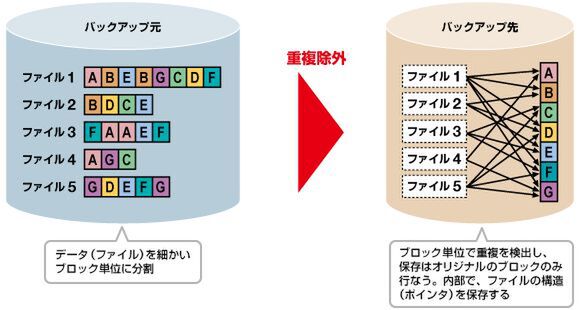
図4 重複排除の仕組み
表紙に配布先名を埋め込んだプレゼンテーション資料が大量にある場合を想定してみよう。表紙以外はまったく内容が共通したファイルのため、ファイル単位の重複排除に比べてブロック単位の重複排除の効果は非常に大きい。
この連載の記事
-
最終回
データセンター
バックアップを賢く行なうための設定チェック -
第11回
データセンター
シンプルなバックアップを試してみる -
第10回
データセンター
ホストから始まったバックアップの歴史を振り返る -
第9回
データセンター
サーバー仮想化環境では、どうバックアップする? -
第8回
データセンター
データを長期間安全に保護するアーカイブとは? -
第7回
データセンター
災害対策のためのバックアップを知ろう -
第5回
データセンター
バックアップメディアはテープからHDDへ -
第4回
データセンター
バックアップに使うメディアはどう選ぶ? -
第3回
データセンター
フルバックアップと増分バックアップは何が違う? -
第2回
サーバー・ストレージ
バックアップをするには何が必要なの? - この連載の一覧へ




