HTMLファイルからページタイトルを抽出して表示
HTMLファイルの読み込みができたら、今度は少し解析してみましょう。ここでは、ページタイトル (<title>〜</title>)を抽出してアラートダイアログに表示します。
取得したファイルを読み込むにはnew File()のパラメータにファイルのパスを指定します。new File()によりファイルオブジェクトが生成されるので、open()メソッドを使ってファイルをオープンします。引数には、読み込みなのか書き込みなのかを文字で指定します。今回は読み込みのみなので"r"を指定します。"w"だと書き込みになります。
ファイルからすべてのデータを読み込むにはread()メソッドを使います。一行だけ読み込ませたいのであればreadln()を使います。読み込まれたデータはテキストになっていますので、JavaScriptのStringオブジェクトのプロパティやメソッドを使って処理できます。ここでは単純にシリアルサーチのindexOf()を使ってタイトル文字を抽出します。
実際のプログラムはサンプル05です。ただ、indexOf()でHTMLタグの内容を抽出するのはあまりよい方法とは言えません。文法的に問題のないXHTMLであれば、new XML()を使ってXMLデータとして処理したほうがよいでしょう。
そこで、次回はASCII.jpで配信しているRSS (XML) を読み込んで必要な情報だけを抽出する方法について解説します。どうぞお楽しみに。

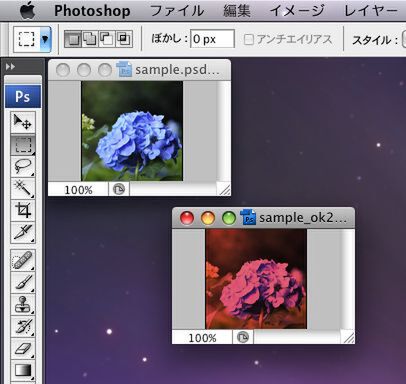
ASCII.jpのページタイトルがアラートダイアログに表示されます
●サンプル05
#target "Bridge"
// Http, Ftpが使えるようにする
if ( !ExternalObject.webaccesslib ) {
ExternalObject.webaccesslib = new ExternalObject("lib:webaccesslib");
}
// 取得先のURLと保存先のパスを指定
var url = "http://ascii.jp/web/";
var filepath = "~/asc.html";
// Webサーバーへ接続
var http = new HttpConnection(url);
http.response = new File(filepath); // 保存先を指定
http.execute(); // サーバーへリクエスト
http.response.close(); // 取得したら終了
// 取得したHTMLファイルを保存
var fileObj = new File(filepath);
// ASCII.jp/WebProfessionalページのタイトルをアラートダイアログに表示
if (fileObj.open("r") == true){
var txt = fileObj.read();
var startPtr = txt.indexOf("<title") + 7;
var endPtr = txt.indexOf("</title>", 7);
var titleStr = txt.substring(startPtr, endPtr);
alert(titleStr);
}