




ウイルス対策ソフトではスパムメールは防げない
昨今大きな問題となっているのが、ユーザーが受け取りを望まないスパムメールである。こうしたスパムは、おもに広告を目的として、無差別に、しかも大量に送られることが多い。そのため、ユーザーは業務の生産性を落としたり、金銭的な被害を受ける可能性が高い。
現在、スパムメールはインターネットのトラフィックの7割~8割を占めるとすらいわれており、インターネットのインフラに大きな負荷を与え続けている。また、必要なメールのみ振り分ける手間があまりにも大きいため、コミュニケーションツールとしての電子メールの存在意義を大きく揺るがせている状態だ。さらに、メールを使って、不正なWebにジャンプさせ、アカウントや個人情報などを詐取するフィッシングも、こうしたスパムメールを用いて実現されることが増えている。
ウイルスやスパイウェアに関しては、第2回で紹介した通り、ウイルス対策ソフトやIDS・IPSを用いることである程度駆除ができる。しかし、こうした対策ではスパムメールは防げない。多くのスパムメールはテキストのメッセージに過ぎない。そのため、メールに添付される不正プログラムをチェックするウイルス対策では、対応が困難なのだ。そのため、スパムメールの除去には、アンチウイルスとは異なった専用の検出技術が必要になる。
現在、スパムメールを除去する方法としては、メールのヘッダにある送信元アドレスやドメインなどを元にスパムメールを判断する「ソースフィルタリング」と、メッセージ自体を解釈してスパムを判断する「コンテンツフィルタリング」が用いられる(図3)。
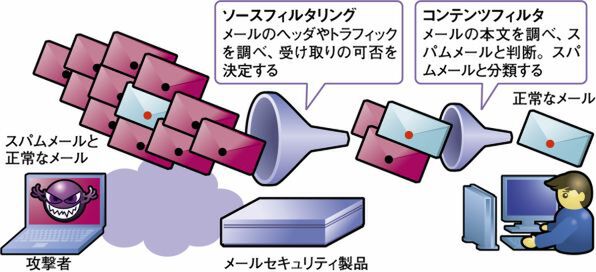
図3 スパムメールのフィルタリング
これらの技術はメールサーバに到着する前にウイルスやスパムメールを除去するメールセキュリティゲートウェイ製品や、ユーザーが利用しているメールクライアントなどに搭載されている。以下、2つのアプローチについて、解説していこう。
送信元を疑うソースフィルタリング
ソースフィルタリングでは、スパムメールを送信しているメールサーバを集めたデータベースを元にスパムメールの受信を拒否する。
こうしたデータベースはインターネット上で提供されており、スパム業者が所有しているサーバはもちろん、管轄のドメイン以外の第三者からのメール転送を許可するオープンリレーサーバと呼ばれるサーバがブラックリスト化※3されている。メールサーバは接続要求を受け取った段階で、送信元のIPアドレスと、こうしたデータベースを照らし合わせ、不正なサーバからの接続要求は拒否すればよいわけだ。
※3:ブラックリスト 不正なサーバを登録したデータベースがブラックリスト。逆に正当なサーバを登録したものがホワイトリストになる。
こうしたソースフィルタリングでの検出はデータベースの精度に依存する。インターネット上の有志で実現されているDNSBL(DNS BlackList)は無償で利用できるが、サーバの登録に責任が伴わないため精度に問題がある。
一方、ベンダーの研究機関などが提供しているサービスは、製品やサービスを導入したユーザーしか使えないが、やはり精度は高い。多くのベンダーは、単に不正なサーバのリストアップだけではなく、送信履歴などから疑わしい送信元を格付けして、判定に活かしている。こうした高度な格付けサービスを「レピュテーション(評判)」と呼ぶ。ユーザー拠点に設置された製品は、定期的にこうしたレピュテーションサービスに問い合わせたりする。
こうしたシンプルなフィルタリングのほか、「グレーリスト」という手段もある。これは初めてメールを送信してくるメールサーバに対してはいったんエラーを返信し、再度送信してきたメールサーバの受信のみを受け入れるというもの。スパムメールの送信は配送効率を重んじるがあまり、SMTPの仕様で規定されている再送を行なわないため、有効な方法である。
最近では、同一送信元からのメール流量を総合的に判断してスパムメールを判定したり、利用可能な帯域自体を絞り込む「トラフィックシェーピング」などの技術も導入されている。
ソースフィルタリングはスパムメールの受信自体を避けることができるという大きなメリットがある。メールサーバに届く前段にソースフィルタリングを実施するメールセキュリティゲートウェイ装置を配置しておくと、サーバにも負荷をかけないで済む。
メールの中身を精査するコンテンツフィルタリング
送信元のみを判断材料にするソースフィルタリングは、精度に限界がある。そのため、通常はメッセージの中身を精査して、スパムメールかを判定するコンテンツフィルタリングが併用される。
コンテンツフィルタリングには、数多くの技術が用いられる(図4)。ユーザーがスパムメールと判定した単語や表現を学習して、スパムメールの定義を学習していく「ベイジアンフィルタ」(図5)や、ベンダーがヘッダや文章構造などからスパムメールらしさをスコア付けしていく「ヒューリスティックフィルタ」、不正なURLが記述された段階でスパムメールと判定する「URLフィルタ」などがある。最近では、ベンダーが収集したスパムメールの情報とメッセージのダイジェスト※4を照らし合わせるシグネチャ方式がよく利用されている。
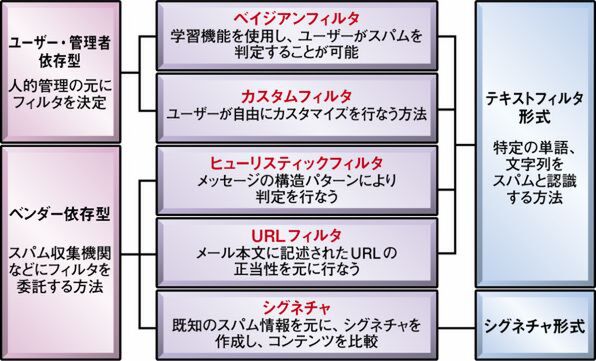
図4 コンテンツフィルタリングの分類
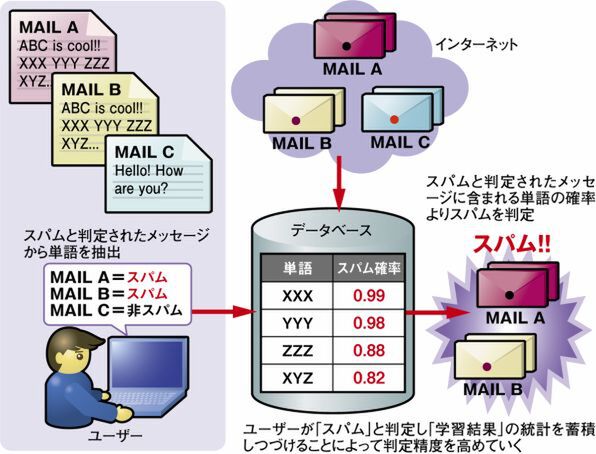
図5 スパムを学習させるベイジアンフィルタ
※4:ダイジェスト ここでのシグネチャは、メッセージの一部を切り出して、ハッシュ関数をかけで算出された文字列を指す。メール全文を照らし合わせるのに比べ、処理が高速化される。
コンテンツフィルタリングの弱点は、メッセージをひととおり精査するため、処理の負荷が高いことだ。そのため、通常はソースフィルタリングで精査すべきメールの量をある程度ふるい落としてから、コンテンツフィルタで判定するというパターンが多い。
次回は、メールソフトウェア側でメールのセキュリティを強化する技術、そしてユーザーやサーバを認証する技術を紹介していこう。
この連載の記事
-
第11回
TECH
正規のユーザーやPCを判断する認証製品 -
第10回
TECH
社内の安全を守るセキュリティ製品の進化を知ろう -
第9回
TECH
検疫からシンクライアントまで!情報漏えいを防ぐ製品 -
第8回
TECH
ITでどこまで実現する?情報漏えい対策の基礎 -
第7回
TECH
インターネットで構築するVPNの仕組み -
第6回
TECH
通信サービスを安価にしたVPNの秘密 -
第5回
TECH
メールソフトのセキュリティとメールの認証 -
第3回
TECH
拡がるWebの脅威と対策を理解しよう -
第2回
TECH
巧妙化する不正プログラムを防ぐには? -
第1回
TECH
不正アクセスを防ぐファイアウォールの仕組み - この連載の一覧へ




