




ハートビートの監視
ここまで見てきたのは、問題が起こったあとの「事後対策」だ。では事前に何かできることはないのだろうか。もっとも手軽なのは、サーバのハートビート(死活)を定期的に監視することだ。ハートビートとは、「心臓の鼓動」のことで、この場合はサーバが動いていることの証という意味である。
なにをもってハートビートとするかはいろいろな判断基準があるが、簡単なのは、定期的にメールを送るようにしておくことだ。メールの宛先を携帯電話のアドレスにしておけば、出張先や自宅でも監視できるので安心である。どれくらいの間隔でメールを送るようにするかはケースバイケースだが、あまり短い間隔だと煩雑かもしれない。とはいえ、あまり間隔を空けすぎると、対処が遅れて意味をなさない。状況を見ながら調整しよう。
Linuxサーバの場合
Linuxであれば、cronを使えばよい(画面9)。
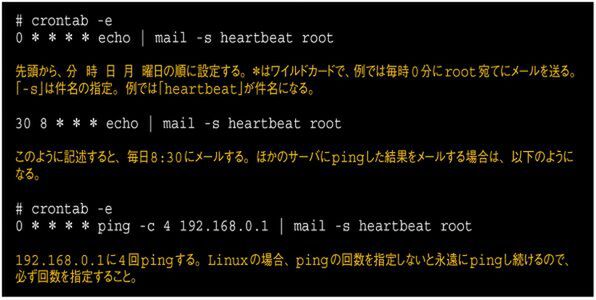
画面9 cronで定期的にメールを送る設定例
Perlなどを使えるなら自分でスクリプトを書けばよいが、とりあえずの簡便な方法としては、単純にメールするだけでも十分目的を達する。
pingの実行結果をメールできるので、自サーバだけでなく、同時に(Windowsサーバを含む)ほかのサーバのハートビートも監視できる。あるいはFedoraやCentOSなどの場合、もともとLogwatchが毎日午前4時にroot宛てにメールを送るようになっているので、それで代用してもよいだろう。
Windowsサーバの場合
Windows Server 2008の場合、[管理ツール]にあるタスクスケジューラから定期的にメールを送れる。
[操作]メニューから[タスクを作成]を選び、メニューに従ってスケジュールなどを設定する。あとは[操作]タブで「電子メールの送信」を設定すればよい。なお、メール送信の詳細条件を設定したければ、Windows PowerShell(Windows Script Host)などでスクリプトなどを書く必要がある。興味ある方は、マイクロソフトTechNetスクリプトセンターなどを参照するとよいだろう。
この連載の記事
-
第8回
サーバー・ストレージ
メールサーバからメールが送信されない -
第7回
サーバー・ストレージ
DHCPサーバからIPアドレスが発行されない -
第6回
サーバー・ストレージ
RAIDのエラー対策をしていますか? -
第5回
サーバー・ストレージ
ファイルサーバのファイルが操作できない -
第4回
サーバー・ストレージ
ファイルサーバの文字化けの解消方法は? -
第3回
ネットワーク
ハードディスクのクラッシュに備えよう -
第1回
サーバー・ストレージ
管理者の心構えはできていますか? -
ネットワーク
サーバトラブル解決のセオリー<目次> - この連載の一覧へ




