




現状を把握する
それでは、具体的な行動の解説に入ろう。トラブル対策の理想としては、システム設計の段階から予防策を組み込んでおくべきだが、今からでも遅くはない。まずは現状を把握することから始める(表2)。

表2 把握しておくべき情報
可能ならば、実際に現場に行って確認する。その際、デジカメを持って行って要所要所で写真を撮っておくと、あとで整理する際に役立つ。
前任者や現場責任者と面識がない場合は、挨拶も兼ねていろいろ話しを聞いてくるとよい。過去のトラブルはもちろん、すでにトラブルが発生していたり、トラブルの予兆があるかもしれない。社内であっても人脈は重要だ。いざというとき、スムースに物事を進めるためにも顔見知りになっておこう。
全体を整理したら、トラブル解決のPDCAサイクルを考える(図1)。
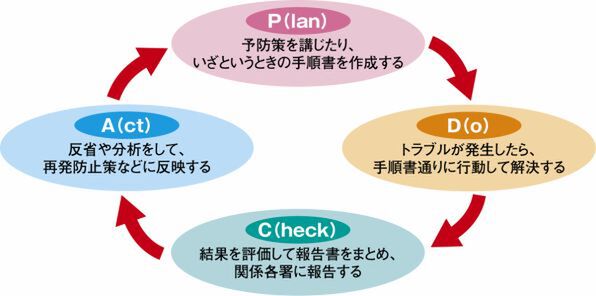
図1 トラブル解決のPDCAサイクル
トラブルの発生をゼロにすることは難しいが、予防策を講じる意義はある。予防策を現実のものとするには、予算折衝など社内の政治的・経済的な事情も考慮しなければならないが、本稿では純粋に技術的な視点やサーバ管理者のあるべき行動という視点を中心に解説する。
トラブルの影響を見積もる
引き続き、想定したトラブルが起きた場合の被害や影響の範囲を見積もる。重要度、深刻度、緊急性などを勘案し、対処する優先順位などを分類する(表3)。

表3 トラブルの分類例
どのように分類するかは、会社の業務や組織などに応じて柔軟に考える。その際、上司と相談しながら連絡すべき範囲も併せて考えておこう。場合によっては、役員への連絡も必要になり、特別プロジェクトチームを編成して対応することになるかもしれない。
手順書を作成しておく
実際にトラブルが発生したら、どのように行動すべきかを手順書としてまとめておこう。チームで動ける場合は、それぞれの役割分担を決めておき、互いに交代やフォローできる体制にする。指揮命令系統などが平時と異なる、自分1人で動かなければならないケースでも、つねに上司や関係部門などと連携しながら動くようにして、決して1人で何とかしようとは考えないこと。勝手な判断が、トラブルを悪化させることもあるのだ。
また、緊急連絡網を整備し、必要に応じて社外の連絡先も整理しておく(表4)。誰が誰に連絡するのかの分担も決めておくと、慌てなくて済む。

表4 社外の連絡先の例
被害の拡大を抑える
トラブルが起きた際、被害を最小限に抑えるためにどうすべきかも、考えておく。トラブルの影響が及ぶ範囲をネットワークなどから切り離したり、リストアなどの復旧作業を開始するタイミングや順番を間違えると、被害が拡大することもある。とりあえず応急処置だけして、上司の判断を仰ぐなど、いろいろなケースを想定しておこう。たとえば、ファイルサーバやデータベースサーバなら、現状のデータを保全することを優先させるべきだ。
予行演習を怠らない
いざというときに、確実に行動できるよう、予行演習もしておこう。たとえば、ファイルサーバのリストア作業や、Windows Serverの回復コンソール(Windows回復環境)からの復旧などは、実際に作業を体験しておかないと、いきなり本番は難しい。また、UPS(無停電電源装置)が停電時に正しく動作し、サーバをシャットダウンしてくれるかどうか、通電時にサーバが自動起動するかどうかもテストしておきたい項目だ。
報告書のフォーマットを作る
トラブルが解決したら、報告書を作成し、関係部門などへ配布することになる。そのため、あらかじめ定型の報告書フォームも作成しておく。いわゆる「5W1H」を網羅するのはもちろん、再発防止に役立つような記載事項を設ける。
また、トラブルが長期化し解決に時間がかかる場合は、中間報告も必要だ。ただし報告書を書くにあたり、原因究明のプロセスが犯人捜しにならないよう気を付ける。もちろん、被害内容によっては本当に犯人捜しが必要なこともあるが、それは社内のしかるべき部門や警察・消防などに任せよう。
(次ページ、「トラブルを防ぐには?」に続く)
この連載の記事
-
第8回
サーバー・ストレージ
メールサーバからメールが送信されない -
第7回
サーバー・ストレージ
DHCPサーバからIPアドレスが発行されない -
第6回
サーバー・ストレージ
RAIDのエラー対策をしていますか? -
第5回
サーバー・ストレージ
ファイルサーバのファイルが操作できない -
第4回
サーバー・ストレージ
ファイルサーバの文字化けの解消方法は? -
第3回
ネットワーク
ハードディスクのクラッシュに備えよう -
第2回
サーバー・ストレージ
まずはリモートでトラブルの原因を切り分けよう -
ネットワーク
サーバトラブル解決のセオリー<目次> - この連載の一覧へ




