Swift Playgroundsで学ぶiOSプログラミング 第87回
Core MLを間接的に利用する画像処理を利用
顔の位置と顔のパーツを認識するプログラム
2018年05月16日 17時00分更新

このところ「機械学習」の成果を、iOSやmacOSのアプリとして容易に利用可能にするCore MLや、それを間接的に利用するフレームワークを使って、ある意味「知的」な処理をプレイグラウンド上で試しています。
前回の最初に示した図を憶えていらっしゃるでしょうか。そう、Core MLという大きなブロックの上に、「Vision」「自然言語処理」「GameplayKit」という3つのブロックが載っていて、さらにその上に「アプリ」が載るという図でした。
これは、例えばiOSの自然言語処理機能を利用するアプリは、間接的にCore MLを使うことになる、という意味を持つ図でした。前回は、その自然言語処理を使ってみたわけですが、今回はその隣にあったVisionを使います。
前回にもざっと説明したように、VisionはCore MLを利用した画像認識機能を提供するフレームワークです。画像認識にもいろいろありますが、現在注目されているのは人間の顔を認識するもので、Visionもそれを中心機能として据えています。Visionには、ほかにも画像の中に含まれる文字や、バーコード、QRコードの認識機能も含まれています。今回は、人間の顔認識機能を使ってみましょう。
Visionの顔認識には、大きく2つのタイプがあります。1つは、画像の中のどこに顔があるか、つまり顔の領域を認識するものです。これはデジカメなどにも内蔵されている機能に近いもので、顔認識としては比較的初歩的なものと言えるでしょう。
もう1つは、人間の顔の上に配置されている目、鼻、口といったパーツや、顔の輪郭そのものを認識するものです。これは比較的高度な機能で、人物を特定したり、さらには表情や、それが示す感情を認識したりするのためにも必要な技術となります。
今回は、両方の機能を順に試していきましょう。
Visionを使って顔の位置を識別する
今回のプログラムでは、プレイグラウンドのライブビュー機能は使わないので、まずはその名も「Vision」というフレームワークを1つだけインポートします。先頭に「VN」と付いているのが、このフレームワークに固有のクラスです。

画像認識機能を提供するVisionフレームワークを利用するには、最低限「Vision」をインポートするだけでいいのです。顔の長方形を認識するリクエストのオブジェクトと認識リクエストを処理するオブジェクトを作り、後者のメソッドを使って認識を実行すれば、前者のプロパティとして結果が戻るという手軽さです
まずは、VNDetectFaceRectanglesRequestクラスのオブジェクトを作ります。これが顔の位置を示す長方形の領域を検出するためのクラスですね。次に、検出すべき画像を指定するために、その画像のURLを与えてVNImageRequestHandlerクラスのオブジェクトを作ります。ここでは、例によって週アスの表紙画像を与えています。オプションは辞書で与えるのですが、ここでは空にしています。
ハンドラーオブジェクトのperformメソッドを実行すれば、指定したリクエストの認識が始まります。結果は最初のリクエストオブジェクトのほうのresultsプロパティに入るので、その中身を調べます。
1つの画像に複数の顔が含まれていることも少なくないので、結果は複数あることが前提です。結果は長方形として得られます。この例では、とりあえずそれをbRectという定数に代入しています。その結果は、プレイグラウンドのデバッグ機能を使って見てみましょう。
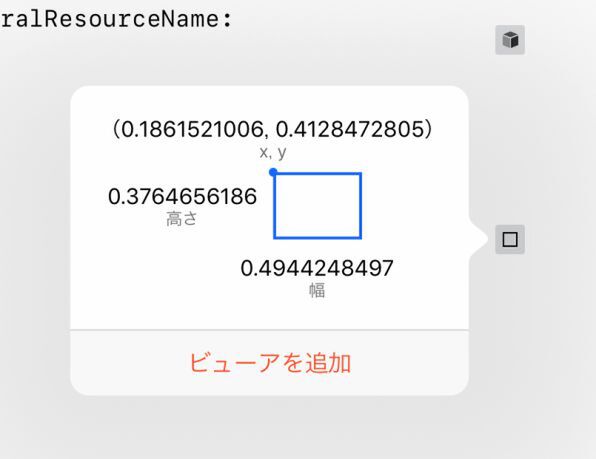
顔の領域を認識した結果の長方形の座標(左上の点と幅と高さ)として得ることができます。とはいえ、数値で返ってきてもそれだけではピンときません
数字では、相対的な位置がわかりにくいのですが、何かしら顔の位置が検出されたことだけはわかります。そこで元の画像の上に、得られた長方形を描画して、その画像を再びデバッグ機能で確認することにしましょう。
iOSのプログラムでは、ビューの上に図形を描画する例は、よく見かけますが、画像の上に描画する例は、あまり見ないかもしれません。そのためには、グラフィックコンテキストというものを使います。「コンテキスト」は、一般的には「文脈」というような意味ですが、この場合はグラフィックを描く「対象」のようなものだと考えてください。つまり画像をコンテキストとして設定すれば、そのコンテキスト、つまり画像の上に直接描けるようになるわけです。そのための処理は、今回の本題ではないので、プログラムを見てなんとなくそんなものだと理解してください。
グラフィックコンテキストは、UIKitに含まれているので、UIKitのインポートを追加するところから始めます。プログラムの前半は、主にそのコンテキストを設定するためのものです。

認識した結果を元の画像の上に描画して確認するために、UIKitのグラフィックコンテキストを使います。ビューを用意しなくても画像の上に直接描画できるのですが、実際に描画するまでの手続きは若干面倒です
上の例では、単に検出した顔を囲む長方形の座標を得ただけでしたが、今回は、その座標を使って画像の上に長方形を描画しています。

1つの画像の上には複数の顔があることが前提なので、結果は複数の顔の領域が返ってくることを想定して処理する必要があります。とはいえ、forループで1つずつ描画領域を取り出して描画するだけです
長方形の枠線だけを描いています。色は緑で、太さは5ポイントに設定しました。描画結果の画像をdImageという定数に代入だけしておいて、その画像をデバッグ機能で確認しましょう。

週アスの表紙画像に含まれる顔の領域を認識させてみました。Visionによる認識の精度はかなり高く、多少のノイズがあっても、顔の一部が隠れたりしていても認識できます
週アスの表紙画像には、人物の上に多くの文字が重なっていて、いわばノイズの多い画像になっていますが、こともなげに顔の領域を認識できました。
この連載の記事
- 第100回 SceneKitの物理現象シミュレーションとアニメーションをARKitに持ち込む
- 第99回 「物理学体」と「物理学場」を設定して物理現象をシミュレーション
- 第98回 SceneKitのノードに動きを加えるプログラム
- 第97回 いろいろな形のノードをシーンの中に配置する
- 第96回 SceneKitの基礎シーンビュー、シーン、ノードを理解する
- 第95回 現実世界の床にボールや自動車のモデルを配置する
- 第94回 ARKitを使って非現実世界との融合に備える
- 第93回 ARKitが使えるiPadを識別するプログラム
- 第92回 Swift Playgrounds 2.1での問題点をまとめて解消する
- 第91回 iPadの内蔵カメラで撮影した写真を認識するプログラム
- この連載の一覧へ
























